딥러닝 파이토치 교과서 - 서지영
12장. 강화 학습
🪼강화 학습이란
머신러닝 / 딥러닝의 한 종류
어떤 환경에서 어떤 행동을 했을 때 그것이 잘 된 행동인지 아닌지 판단하고 보상/벌칙을 주는 과정을 반복하여 스스로 학습하게 하는 분야
환경 environment
에이전트 agent
=> 환경과 상호 작용하는 에이전트를 학습시키는 것
상태 state (다양한 상황) 에서 행동 action을 취하며 그에 대한 응답으로 보상 reward를 받으며 학습
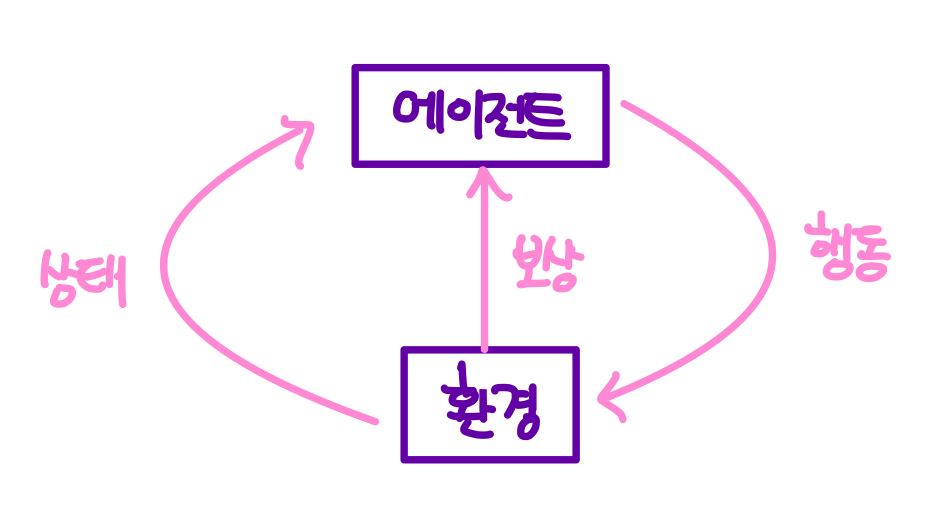
상태 State
: 에이전트가 관찰 가능한 상태의 집합
시간 T에서 에이전트의 상태 s

행동 Action
: 에이전트가 상태 S에서 가능한 행동
시간 T에서 특정 행동 a

🪼마르코프 결정 과정
강화 학습의 문제들은 마르코프 결정 과정으로 표현됨
마르코프 결정 과정은 모두 마르코프 프로세스에 기반
강화 학습 = 마르코프 결정 과정 + 학습
🪼마르코프 프로세스
어떤 상태가 일정한 간격으로 변하고 / 다음 상태는 현재 상태에만 의존하는 확률적 상태 변화
현재 상태에 대해서만 다음 상태가 결정
(현재 상태까지의 과정 필요 없음)
변화 상태들이 체인처럼 엮여 있음 => 마르코프 체인 markov chain 이라고도 부름
==
마르코프 특성을 지니는 이산 시간(연속적 ㄴㄴ 이상적 ㅇㅇ)에 대한 확률 과정
시간에 따른 상태 변화

상태 변화 = 전이 transition
전이는 확률로 표현됨 = 상태 전이 확률 (state transition probability)

🪼마르코프 보상 프로세스 markov reward process (MRP)
= "마르코프 프로세스 + 상태마다의 보상" 인 확률 모델
각 상태의 보상 총합 => "리턴"

어느 시점에서 보상을 받을지가 중요함
=> 현재 가치와 미래 가치를 잘 판단해서 행동해야 함
수식적으로 적용
할인율 r 이 적용된 리턴 G

- 할인율 r이 1과 가까워질수록 미래 보상을 더 많이 고려함 (원시안적 행동 수행)
- 할인율 r이 0과 가까워질수록 현재 보상을 더 많이 고려함 (근시안적 행동 수행
가치 함수 value function

현재 상태가 s 일 때 앞으로 발생할 것으로 기대되는 모든 보상의 합 (미래 가치)
- 강화 학습의 핵심 : 가치 함수를 최대한 정확하게 찾는 것
- 미래 가치가 가장 클 것으로 기대되는 결정을 하고 행동하는 것
🪼마르코프 결정 과정 markov desision process (MDP)
= "마르코프 보상 과정 + 행동" 인 확률 모델
각 상태마다 전체적인 보상을 최대화하는 행동이 무엇인지 결정하는 것
정책 policy ㅠ
각각의 상태마다 행동 분포를 표현하는 함수

MDP가 주어진 ㅠ를 따를 때 s에서 s'로 이동할 확률
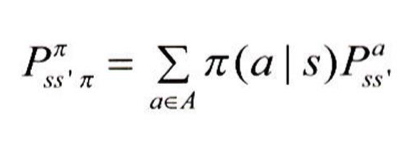
s에서 얻을 수 있는 보상 R
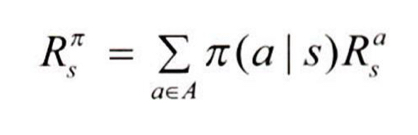
상태-가치 함수
상태 s에서 얻을 수 있는 리턴의 기댓값
MRP 가치 함수와의 차이
- 주어진 정책 ㅠ에 따라서 행동을 결정하고 다음 상태로 이동함

행동-가치 함수
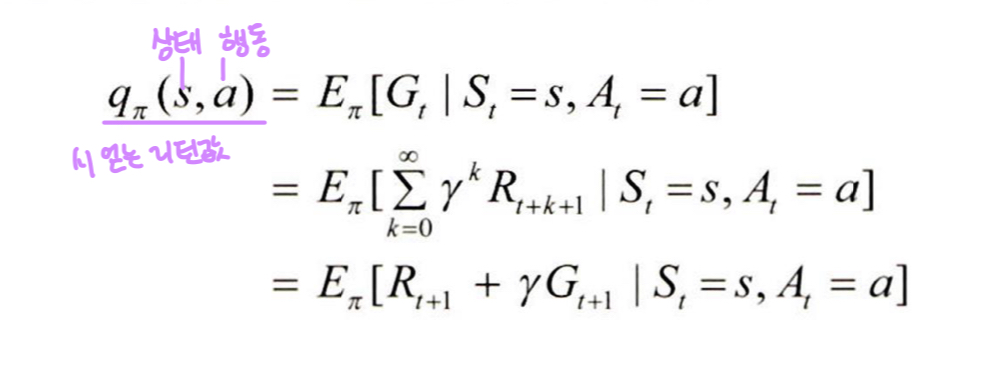
가치 함수 (행동-가치,상태-가치) 계산에는 O(n^3) 시간복잡도 필요 ( 별로 안 좋음ㅠㅠ
문제 해결 방법
- 다이나믹 프로그래밍
- 몬테카를로
- 시간 차 학습
- 함수적 접근 학습
'Club|Project > Euron | AI,데이터분석 학회' 카테고리의 다른 글
| ✳️[ Playing Atari with Deep Reinforcement Learning ] 논문 리뷰 (0) | 2025.03.30 |
|---|---|
| 🪼 강화 학습 - MDP를 위한 벨만 방정식 : 딥러닝 파이토치 교과서 (0) | 2025.03.28 |
| Generative Adversarial Nets : 발표 정리 (0) | 2025.03.25 |
| ✳️ [GAN: Generative Adversarial Nets] 논문 리뷰 (0) | 2025.03.24 |
| 🪼생성 모델 : 딥러닝 파이토치 교과서 (0) | 2025.03.23 |

