- 가상환경 활성화
>>> source env/bin/activate
- 키 못 찾을 때 환경 변수 재로드
from dotenv import load_dotenv
load_dotenv()🎀 RAG
: Retrieval Augmented Geration ( 검색 증강 생성 )
새로운 데이터를 제공
질문 + 원래의 데이터 + 추가된 새로운 데이터 => 를 모델에 보내 응답 받기
새로운 데이터를 프롬프트에 넣고 모델에다 전송
첫번째 단계 : Retrival ( 랭체인의 모듈 )
Retrieval | 🦜️🔗 Langchain
Many LLM applications require user-specific data that is not part of the model's training set.
python.langchain.com
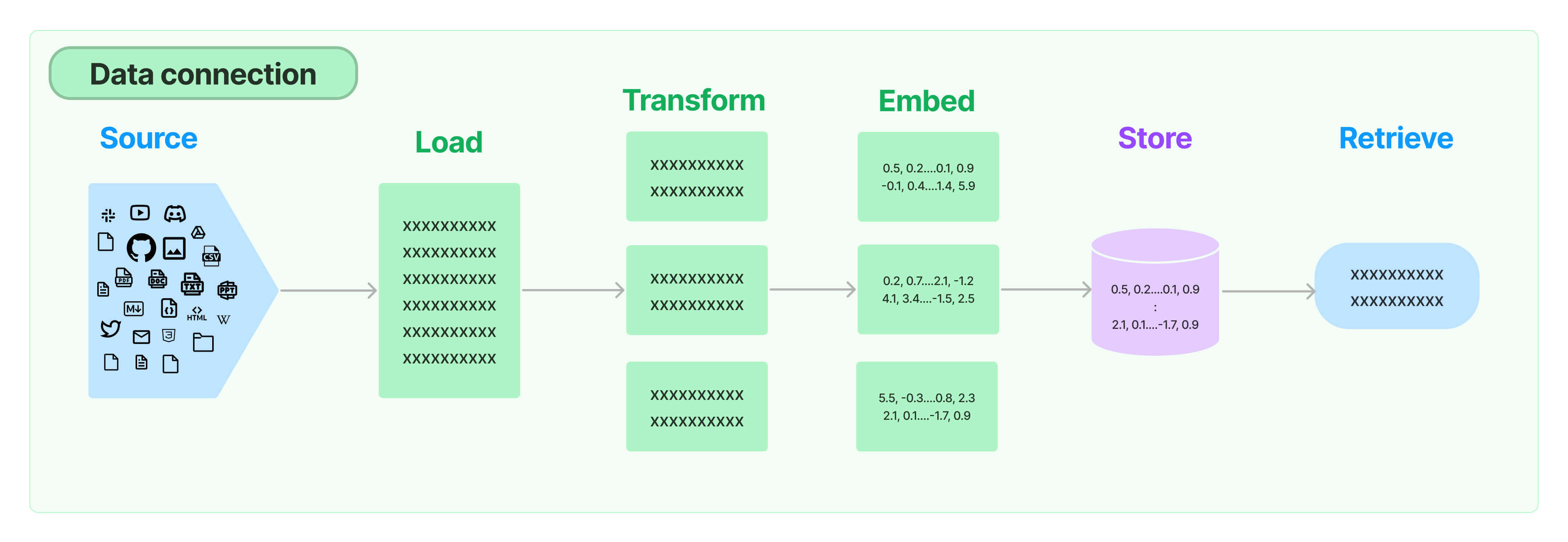
데이터를 Retrival하기 : 데이터를 소스에서 로드하고/ 분할 / 임베딩(텍스트를 컴퓨터가 이해할 수 있는 언어로 바꾸기) / 저장
🎀 Load : 문서로드/분할하기 Data Loaders and Splitters
Document loaders | 🦜️🔗 Langchain
📄️ Grobid GROBID is a machine learning library for extracting, parsing, and
python.langchain.com
문서 로더 : 소스에서 데이터를 추출하고 랭체인에 가져다 주는 코드 (깃허브도 잇고 피그마도 있고!)
https://python.langchain.com/docs/integrations/document_loaders/google_drive
https://python.langchain.com/docs/integrations/document_loaders/discord
햐 디코랑 구글드라이브잇다 체고다
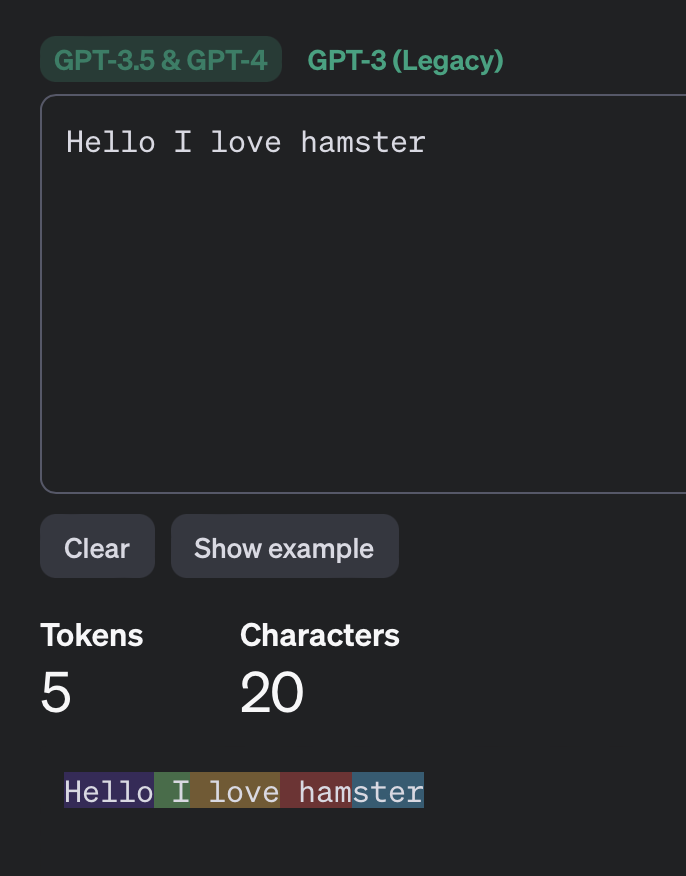
🎀 Transform : TikToken
문자 개수를 토큰으로 항상 취급하는 것이 아님. 아래에서 확인 가능
https://platform.openai.com/tokenizer
🎀 Embed : Vectors
텍스트를 컴퓨터가 이해할 수 있는 일들로 바꾸는 일
vertorization 벡터화
1000차원 모델~등등
- 차원 만들기
- 각각의 차원에 embeding하기
+ 각각의 단어를 통해 연산하여 새 단어를 만들 수 있음 (숫자로 치환햇기 때문)
+ 벡터 안에서의 가까운 정도를 보고 연관성 체크 가능
https://turbomaze.github.io/word2vecjson/
Word to Vec JS Demo
turbomaze.github.io
단어 입력 시 비슷한 벡터를 가진 단어를 보여주는 사이트
https://www.youtube.com/watch?v=2eWuYf-aZE4
로드하고 토큰 나누고 임베드하고 하는 과정이
LLM에게 주요한 정보(관련잇는 정보) 만 넘김으로서 자원을 아낄 수 있음
🎀 Langsmith
https://www.langchain.com/langsmith
LangSmith
Get your LLM app from prototype to production.
www.langchain.com
가입완료
내 코드의 체인이 무슨 일을 하고 있는자 시각적으로 확인 가능!!
🎀 RetrievalQA
LLM chain 은 legacy
"Langchain Expression Language ( LCEL)" 사용권장
와와!!
Rag로 학습시킨 문서에서 찾은 정보로 질문에 답변해줌!
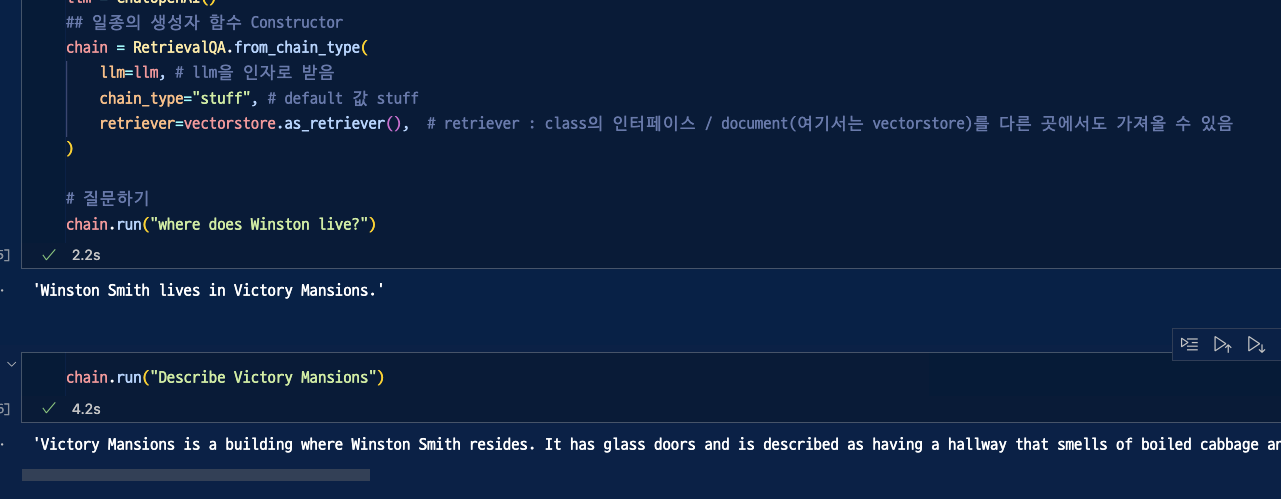
🎀 Stuff LCEL Chain
🎀 Map Reduce LCEL Chain
=> 큰 용량의 문서 사용에 유리
1. list 내부의 모든 문서들을 위한 Prompt 만들어서 llm에게 던지기
for doc in list of docs | prompt | llm
2. llm으로부터 받은 reponse들을 취합해 하나의 document 만들기
for respone in list of llms response | put them all together
3. 만들어진 하나의 최종 document : LLM 을 위한 prompt 로 전달
final doc | prompt | llm
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings, CacheBackedEmbeddings
from langchain.vectorstores import FAISS
from langchain.storage import LocalFileStore
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
llm = ChatOpenAI(
temperature=0.1,
)
cache_dir = LocalFileStore("./.cache/")
splitter = CharacterTextSplitter.from_tiktoken_encoder(
separator="\\n",
chunk_size=600,
chunk_overlap=100,
)
loader = UnstructuredFileLoader("./files/chapter_one.txt")
docs = loader.load_and_split(text_splitter=splitter)
embeddings = OpenAIEmbeddings()
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(embeddings, cache_dir)
vectorstore = FAISS.from_documents(docs, cached_embeddings)
# retriever : string 값을 입력받고 document들을 출력해줌
retriever = vectorstore.as_retriever()
# 1번 체인(map_doc_chain) : 1. list 내부의 모든 문서들을 위한 Prompt 만들어서 llm에게 던지기
map_doc_prompt = ChatPromptTemplate.from_messages(
[
(
"system", # 질문에 대한 답변이 포함되어 있는 것 같은 부분을, 그대로 반환해달라 요청!
"""
Use the following portion of a long document to see if any of the text is relevant to answer the question. Return any relevant text verbatim. If there is no relevant text, return : ''
-------
{context}
""",
),
("human", "{question}"),
]
)
map_doc_chain = map_doc_prompt | llm
# map_chain용 함수 :
# 한 개의 string만 반환해야 함!
def map_docs(inputs):
documents = inputs["documents"] # Input에서 document 값 추출
question = inputs["question"]# Input에서 question 값 추출
# 여기서의 반환값 => "chain = {"context": 여기!" 에 들어감
return "\\n\\n".join( # 2. llm으로부터 받은 reponse들을 취합해 하나의 document 만들기
map_doc_chain.invoke( # 각 문서마다 질문을 던져주는 또다른 chain(1번 체인(map_doc_chain)) 실행!
{"context": doc.page_content, "question": question}
).content
for doc in documents
# # 또는
# results = []
# for document in documents:
# result = map_doc_chain.invoke(
# "context": doc.page_content, "question": question}
# ).content
# results.append(result)
# results = "\\n\\n".join(results)
# return results
)
# map_chain : retriever를 통해 얻어진 document 전달 : 각 문서를 살펴보며 사용자 질문 대답에 필요한 정보가 담겨 있는지 확인
# => map_chain 목표 : 사용자의 질문과 관련 있는 하나의 문서!
map_chain = {
"documents": retriever, # documents는 retriever으로부터 받아 옴
"question": RunnablePassthrough(), #사용자 질문 대답 전달
} | RunnableLambda(map_docs)
# RunnableLambda : chain과 그 내부 어디서든 function을 호출할 수 있도록 해줌
# 2번 체인(final_prompt) : 3. 만들어진 하나의 최종 document : LLM을 위한 prompt로 전달
final_prompt = ChatPromptTemplate.from_messages(
[
(
"system", #최종적으로 LLm에게 던지는 질문 ( 할루시네이션 방지 + )
"""
Given the following extracted parts of a long document and a question, create a final answer.
If you don't know the answer, just say that you don't know. Don't try to make up an answer.
------
{context}
""", # {context} 에는 많은 발췌문들이 삽입
),
("human", "{question}"), # 사용자의 질문
]
)
chain = {"context": map_chain, "question": RunnablePassthrough()} | final_prompt | llm
# "question": RunnablePassthrough() : 아래 질문이 이 부분을 통과해서 final_prompt의 question에 전달되게 함
# 실행!
chain.invoke("Describle victory mention")
'🤖 AI > LangChain - GPT 강의' 카테고리의 다른 글
| 🦜 풀스택 GPT - Quiz GPT ing (0) | 2024.05.28 |
|---|---|
| 🦜 풀스택 GPT - MEMORY (0) | 2024.02.27 |
| 🦜 풀스택 GPT - MODEL IO (0) | 2024.02.20 |
| 🦜 풀스택 GPT - LangChain (2) | 2024.02.17 |
| 🦜 풀스택 GPT - 시작하기~ (0) | 2024.01.07 |


