이 강의
잊지 않고 있었다고요
🎀 DOCUMENT GPT

🎀 Streamlit
Streamlit • A faster way to build and share data apps
Streamlit is an open-source Python framework for machine learning and data science teams. Create interactive data apps in minutes.
streamlit.io
머신 러닝과 데이터 과학을 위한 아름답고 사용자 정의 가능한 웹 앱을 쉽게 만들고 공유할 수 있게 해주는 오픈 소스 Python 라이브러리
pip install streamlit
streamlit run 문서명
하면 딴

바로 페이지 만들어짐
https://docs.streamlit.io/develop/api-reference
Streamlit Docs
Join the community Streamlit is more than just a way to make data apps, it's also a community of creators that share their apps and ideas and help each other make their work better. Please come join us on the community forum. We love to hear your questions
docs.streamlit.io
다양한 위젯 확인 가능
chat_message, input 등등 활용
- 단 한 개의 요소가 변화해도 전체 파일 재로드
import time
import streamlit as st
st.set_page_config(
page_title="DocumentGPT",
page_icon="📃",
)
st.title("📃 Document GPT")
# st.session_state가 messages라는 키를 가지고 있지 않다면
if "messages" not in st.session_state:
# 데이터를 추가할 수 있는 위젯 session_state
st.session_state["messages"] = []
#메세지 보내기 - 메세지 내용, 보낸 역할
def send_message(message, role, save=True):
# 인물 - 메세지 모양
with st.chat_message(role):
st.write(message)
# save가 없다면 streamlit은 변경 시 전부 재로딩하므로 이전 내용 사라짐
if save:
st.session_state["messages"].append({"message": message, "role": role})
#이전 내용 보이기
for message in st.session_state["messages"]:
send_message(
message["message"],
message["role"],
save=False,
)
# 메세지 인풋 창
message = st.chat_input("AI에게 메세지를 보내세용")
# 메세지가 입력되면
if message:
# 사람 질문
send_message(message, "human")
time.sleep(2)
# AI 답변
send_message(f"You said: {message}", "ai")
with st.sidebar:
st.write(st.session_state)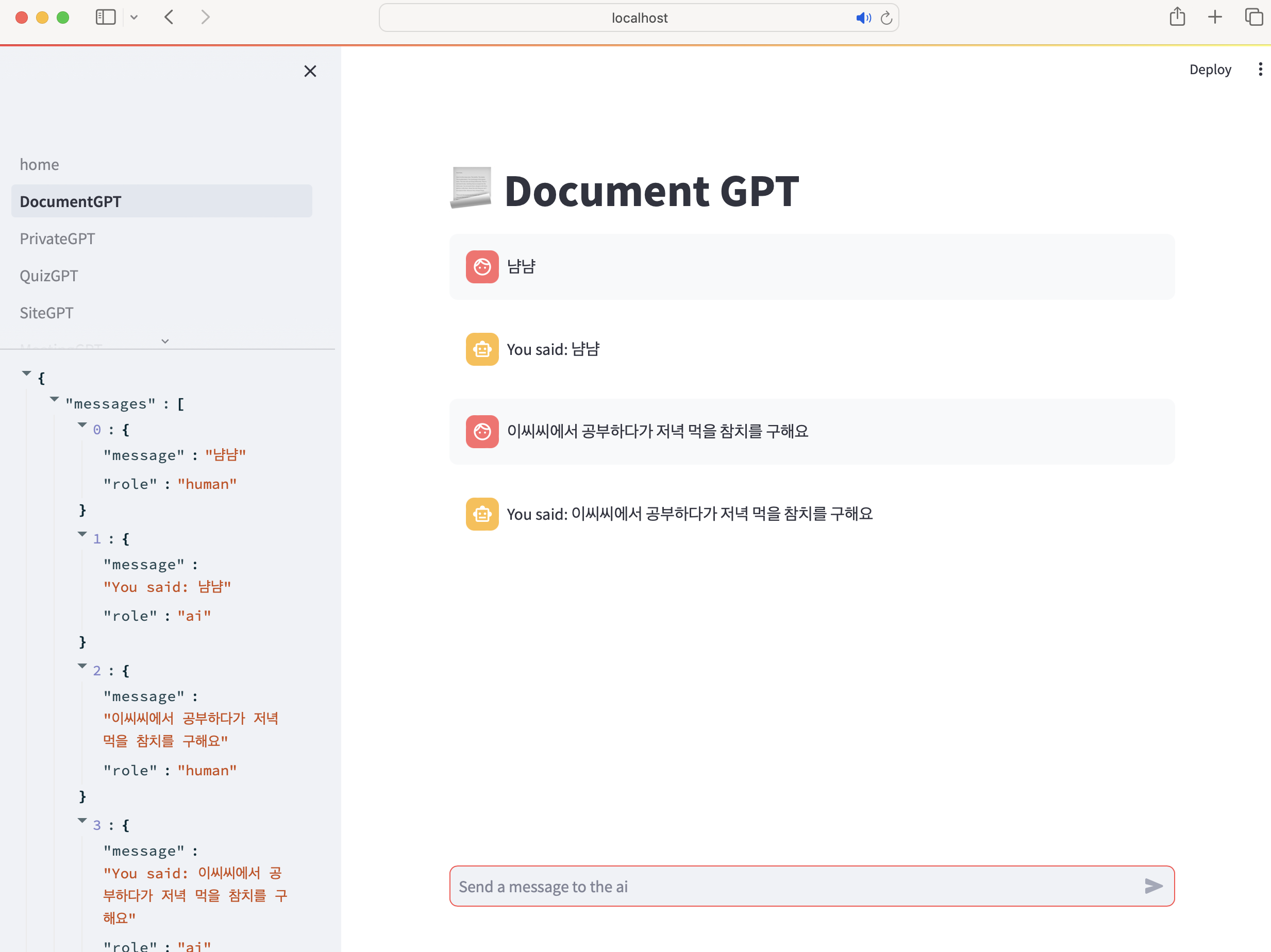
🎀 Langchain
Runnable interface | 🦜️🔗 LangChain
To make it as easy as possible to create custom chains, we've implemented a "Runnable" protocol. Many LangChain components implement the Runnable protocol, including chat models, LLMs, output parsers, retrievers, prompt templates, and more. There are also
python.langchain.com
docs = retriever.invoke(message)
docs = "\n\n".join(document.page_content for document in docs)
prompt = template.format_messages(context = docs, question = message)
llm.predict_messages(prompt)위 코드를 아래 코드로 체인으로 만들 수 있다
chain = (
{
"context": retriever | RunnableLambda(format_docs),
"question": RunnablePassthrough(),
}
| prompt
| llm
)
완성된 코드
import os
from langchain.document_loaders import UnstructuredFileLoader
from langchain.embeddings import CacheBackedEmbeddings, OpenAIEmbeddings
from langchain.storage import LocalFileStore
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.faiss import FAISS
import streamlit as st
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.chat_models import ChatOpenAI
OPENAI_API_KEY = st.secrets["openai"]["OPENAI_API_KEY"]
# 페이지 세팅
st.set_page_config(
page_title="DocumentGPT",
page_icon="📃",
)
# 모델 가져오기
llm = ChatOpenAI(
temperature=0.1,
openai_api_key = OPENAI_API_KEY
)
# 같은 파일일 시 재로딩 방지하기
@st.cache_data(show_spinner="Embedding file...")
# 파일을 받아서 처리하고 검색기를 반환함
def embed_file(file):
# 파일 저장을 위한 경로 설정
# 현재 스크립트의 절대 경로를 기준으로 캐시 디렉토리의 경로를 설정
base_path = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(base_path, "..", "..", ".cache", "files", file.name)
# 필요한 디렉토리가 있는지 확인하고, 없다면 생성
os.makedirs(os.path.dirname(file_path), exist_ok=True)
# 문서 로드 -> 쪼개기 -> 임베딩 -> 벡터공간 저장 -> 검색기 넘기기 ( + 임베딩 캐시 작업)
cache_dir = LocalFileStore(f"./.cache/embeddings/{file.name}") # 각각의 파일을 임베딩
splitter = CharacterTextSplitter.from_tiktoken_encoder(
separator="\n",
chunk_size=600,
chunk_overlap=100,
)
loader = UnstructuredFileLoader(file_path)
docs = loader.load_and_split(text_splitter=splitter)
embeddings = OpenAIEmbeddings(api_key=OPENAI_API_KEY)
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(embeddings, cache_dir)
vectorstore = FAISS.from_documents(docs, cached_embeddings) # FAISS 사용
retriever = vectorstore.as_retriever()
return retriever
# 화면 메세지 표시
def send_message(message, role, save=True):
with st.chat_message(role):
st.markdown(message)
if save:
st.session_state["messages"].append({"message": message, "role": role})
# 지난 대화 표시기
def paint_history():
for message in st.session_state["messages"]:
send_message(
message["message"],
message["role"],
save=False,
)
def format_docs(docs):
return "\n\n".join(document.page_content for document in docs)
# context와 question를 요구하는 프롬프트 작성
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""
Answer the question using ONLY the following context. If you don't know the answer just say you don't know. DON'T make anything up.
Context: {context}
""",
),
("human", "{question}"),
]
)
st.title("DocumentGPT")
# 마크다운 코드 작성
st.markdown(
"""
## Hi there!
당신의 파일에 대해 학습하고 답할 수 있는 chatbot!
"""
)
# streamlit의 파일 업로더
with st.sidebar:
file = st.file_uploader(
"Upload a .txt .pdf or .docx file",
type=["pdf", "txt", "docx"],
)
# 파일이 업로드되면 입력창이 나타남
if file:
retriever = embed_file(file)
send_message("I'm ready! Ask away!", "ai", save=False)
paint_history()
message = st.chat_input("Ask anything about your file...")
if message:
send_message(message, "human")
chain = (
{
"context": retriever | RunnableLambda(format_docs),
"question": RunnablePassthrough(),
}
| prompt
| llm
)
response = chain.invoke(message)
send_message(response.content, "ai")
else:
st.session_state["messages"] = [] # 새 파일은 히스토리 비우기
와~!
+ 응답 생성 완료 후 보이는 게 아니라 실제 지피티처럼 문장이 쓰여지는 게 바로바로 보이게 만들기
Streaming
# 스트리밍을 위한 클래스
class ChatCallbackHandler(BaseCallbackHandler):
message = ""
def on_llm_start(self, *args, **kwargs):
self.message_box = st.empty()
def on_llm_end(self, *args, **kwargs):
save_message(self.message, "ai")
def on_llm_new_token(self, token, *args, **kwargs):
self.message += token
self.message_box.markdown(self.message)시작할 때 호출되는 함수
끝날 때~
새로운 토큰마다~

이렇게 토큰토큰 쪼개져서 나온다
오왕!
'🤖 AI > LangChain - GPT 강의' 카테고리의 다른 글
| 🦜 풀스택 GPT - Quiz GPT ing (0) | 2024.05.28 |
|---|---|
| 🦜 풀스택 GPT - RAG (0) | 2024.03.03 |
| 🦜 풀스택 GPT - MEMORY (0) | 2024.02.27 |
| 🦜 풀스택 GPT - MODEL IO (0) | 2024.02.20 |
| 🦜 풀스택 GPT - LangChain (2) | 2024.02.17 |


