Sejong-Yonsei-Ewha NEtwork for Research on Galactic Interactions
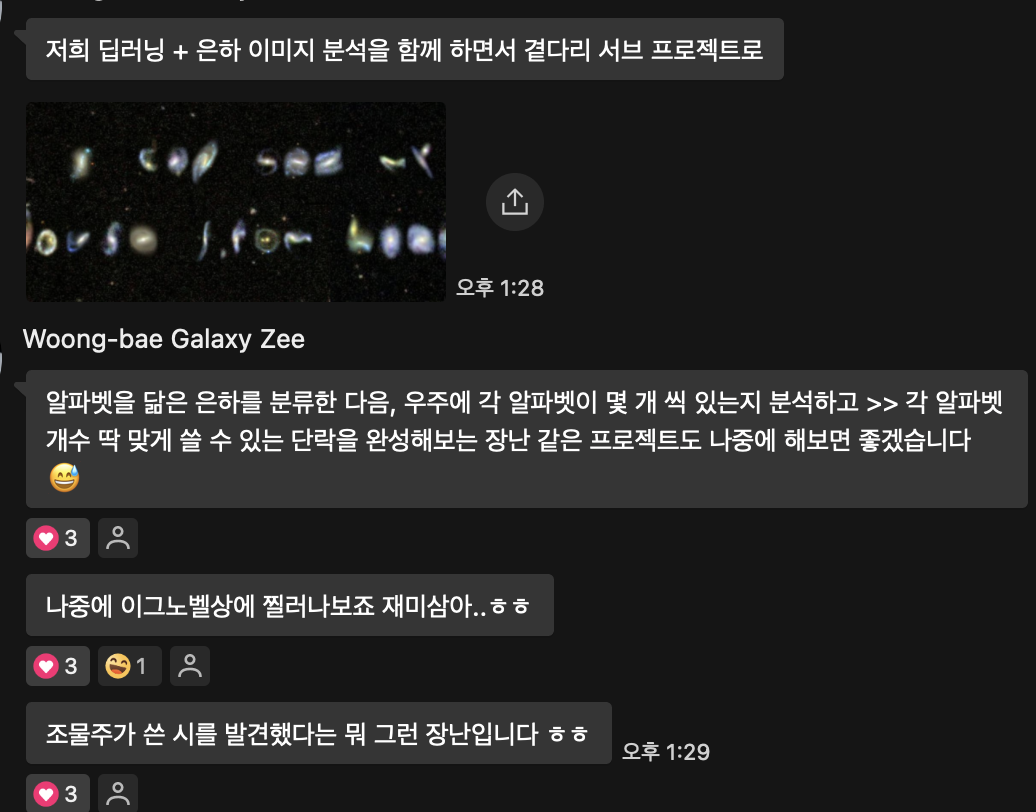
재밌겠다..
공부 겸 하는 것도 나쁘지 않을 듯
🏆 은하 알파벳 분류 모델 개발
1. 공개된 대규모 은하 이미지 데이터셋 (및 접근 방법과 라이선스)
알파벳처럼 보이는 은하를 많이 확보하려면 대용량의 은하 이미지 데이터가 필요
대표적인 공개 천문 데이터셋
- Galaxy Zoo – 시민과학 프로젝트로 전 세계 자원봉사자들이 SDSS, Hubble 등 망원경으로 촬영된 약 100만 개의 은하 이미지에 대해 형태 분류에 참여한 데이터셋이다 . 은하 형태(나선, 타원 등) 분류 결과와 이미지 ID를 제공하며, 데이터는 Galaxy Zoo 공식 사이트에서 다운로드 가능하다 . 이미지 자체는 Sloan Digital Sky Survey 등 출처로부터 링크되는데, 연구 용도로 자유롭게 사용 가능하며 결과 출판 시 Galaxy Zoo 논문을 인용하는 등의 조건이 있다 . (예: Galaxy Zoo 1 데이터는 약 90만 개 은하에 대한 분류 카탈로그 제공 ).
- Sloan Digital Sky Survey (SDSS) – 뉴멕시코 아파치포인트 천문대의 2.5m 망원경으로 하늘의 3분의 1 이상(약 14,000平方度)을 촬영한 광학 천문 서베이이다. SDSS는 5개 밴드 필터로 수억 개 천체를 이미지화했으며, 약 3억 개 이상의 별과 은하를 탐지하여 데이터베이스화했다 . SDSS 데이터는 SkyServer를 통해 SQL 질의 또는 웹 인터페이스로 접근 가능하고, 객체 좌표로 이미지 컷아웃도 받을 수 있다. 라이선스: SDSS 공개 데이터는 퍼블릭 도메인으로 간주되며, 웹사이트에 공개된 모든 이미지는 Creative Commons Attribution (CC-BY) 라이선스로 자유 이용 가능하지만 출처(SDSS)를 명시해야 한다 .
- Hubble Space Telescope (HST) 자료 – 허블 우주망원경이 촬영한 은하 이미지들은 고해상도이지만 특정 심우주 영역이나 관심 천체를 중심으로 한다. MAST (Mikulski Archive for Space Telescopes)를 통해 필터/좌표별로 이미지 데이터를 검색, 다운로드할 수 있다. 허블 이미지 데이터는 관측 후 1년의 지재권 유지기간이 지나면 공개되며, NASA와 허블 이미지 대부분은 퍼블릭 도메인으로 자유롭게 이용 가능하다 . (단, ESA 등 파트너 기관이 제공한 일부 데이터는 CC BY 4.0 등으로 공개됨 .)
- DESI Legacy Imaging Surveys – 다크에너지분광기(DESI) 준비를 위해 실시된 광범위 광학/적외선 천체 사진 조사로, DECaLS, BASS, MzLS 등의 서베이를 통해 북반구 약 14,000平方度 영역의 은하 이미지를 제공한다 . 수천만 개 이상의 은하를 포함하고 있으며, NOIRLab나 Legacy Survey 사이트를 통해 공개 접근이 가능하다. 데이터 사용 시 DESI Legacy Survey에 대한 인정문구를 포함해야 하나, 연구/교육 목적으로 자유롭게 활용할 수 있다 (미국 DOE/NSF 자금으로 수행된 공개 데이터).
- Pan-STARRS1 (PS1) Survey – 하와이 할레아칼라의 1.8m 망원경으로 전천을 다색(five-band) 촬영한 광역 서베이. 약 30억 개 이상의 천체를 검출하여 데이터베이스화했으며, 이 중 수억 개는 은하이다. PS1 데이터는 MAST 포털이나 AWS Public Dataset으로 공개되어 있어 대량 이미지 접근이 가능하다 . 라이선스는 공개(public domain)에 준하며, 이용 시 PS1 Survey를 출처로 명시한다.
가장 방대한 은하 이미지 소스는 SDSS와 그 후속 지상/우주 서베이들
2. 사람이 보기에 알파벳 형태인 은하 이미지 필터링/분류 전략
알파벳 모양으로 보이는 은하를 선별하는 일은 전통적인 천문 분류 범주(예: 나선팔, 타원핵 등)를 넘어서는 독특한 패턴 인식 작업이다. 효과적인 필터링/분류 전략으로 다음을 고려할 수 있다

- 크라우드소싱(Crowdsourcing): 사람의 직관적인 패턴 인식 능력을 활용하는 접근이다. Galaxy Zoo 프로젝트에서도 다수의 자원봉사자가 은하 이미지를 분류하면서 “알파벳처럼 보이는 은하”들을 발견한 바 있다 . 사람 눈에는 희미한 구조에서도 글자 형태를 알아보는 파레이돌리아(pareidolia) 현상이 발생하므로 , 일반 대중 참여가 효과적이다. 예를 들어 Zooniverse 플랫폼에 하위 프로젝트로 “은하 알파벳 찾기”를 개설하여, 참가자들이 각 은하 이미지가 어떤 글자에 가장 가까워 보이는지 투표하게 할 수 있다. Galaxy Zoo Principal Investigator인 Chris Lintott도 “이러한 패턴 인식 작업에서는 인간이 컴퓨터보다 낫다”고 언급했으며, 자원봉사자들의 도움이 결정적이었다 . 크라우드소싱을 통해 후보 이미지에 대한 라벨(예: ‘이 은하는 S자 모양’)을 수집하고, 다수결 또는 전문가 검증을 거쳐 신뢰도 높은 알파벳 모양 데이터셋을 구축한다.
- 시각적 특징 기반 자동 필터링: 사전에 사람이 일부 예시를 지정한 뒤 컴퓨터 비전 알고리즘으로 유사한 형태의 은하를 검색하는 방법이다. 예를 들어:
- 형태학적 특징 추출: 은하 이미지에서 에지(edge) 검출이나 등광도 컨투어(contour)를 추출한 후, 알파벳 글자들의 윤곽과 유사도를 계산한다. 각 알파벳(A–Z)의 이상적 형태(이진 마스크 등)를 마련하고, 은하 이미지의 이진화/외곽선과 교차 상관, Hausdorff 거리, Shape Context 등의 지표로 비교하여 임계치 이상 유사도를 보이는 것만 선별한다. 예를 들어 은하의 밝은 부분이 고리 형태라면 “O”에 높은 점수를 줄 수 있다.
- 딥러닝 임베딩 및 클러스터링: 사전 학습된 CNN이나 자동인코더를 사용해 이미지 임베딩 벡터를 추출한 뒤, 임베딩 공간에서 군집화(clustering)를 수행한다. 은하 모양이 비슷한 것끼리 모이므로, 군집 중 사람이 보기에도 특정 글자 형태인 군집(예: Y자형, S자형 등)이 나타날 수 있다. 이러한 군집을 식별하여 해당 군집의 은하들만 추출하는 방식이다. (t-SNE나 UMAP으로 시각화하여 군집을 식별할 수도 있음.)
- 전이학습된 문자 인식 모델 활용: 일반 문자 이미지를 학습한 모델(OCR 혹은 문자분류 CNN)에 은하 이미지를 투입해 어느 글자로 인식되는지를 보는 방법이다. 예컨대, 은하 이미지를 흑백 이진화하여 OCR 엔진에 넣었을 때 “A”로 인식된다면 해당 은하는 A글자 형태일 가능성이 높다. 다양한 각도에서 시도해 가장 자신있게 인식되는 글자가 있다면 그 후보로 분류한다. (물론 은하 이미지는 노이즈가 많아 오탐률이 높지만, 보조 지표로 활용 가능함.)
- 복합 전략: 머신러닝 + 크라우드소싱 혼합도 고려된다. 예를 들어 간단한 알고리즘으로 거르는 1차 필터(예: 크기나 대략적 길쭉함 등 기준으로 노이즈 제거) 후, 남은 후보에 대해 사람 혹은 ML의 정밀 판별을 적용한다. 또는 human-in-the-loop 방식으로, 모델이 점수가 높은 후보들을 제안하면 사람 검증으로 확정 라벨을 붙이고, 이를 다시 모델 학습에 반영하여 성능을 향상시키는 iterative한 접근도 가능하다.
크라우드소싱도 빼고..
ocr이 쉬울 것 같은데 그럼 모델 개발이 아니라 그냥 활용 아님?
3. 알파벳 형태 분류 모델 후보 (CNN 기반 및 이미지 생성/해석 모델)
수집된 데이터를 학습시켜 은하 이미지를 26개의 알파벳 클래스로 분류하거나, 또는 “알파벳 모양/해당없음” 이진 분류를 수행할 수 있다. 이때 고려할 수 있는 모델로 두 가지 부류가 있다: 전통적인 합성곱 신경망(CNN) 계열 모델과, 멀티모달/생성 모델의 활용이다.
3.1 CNN 기반 모델들 (분류기 성능이 검증된 모델들)
- ResNet (Residual Network) – 마이크로소프트 연구소에서 개발한 잔차 학습 구조의 심층 CNN 모델이다 . 수백 레이어까지 네트워크를 깊게 쌓을 수 있도록 skip connection을 도입하여 기울기 소실 문제를 해결했다 . ResNet-50, ResNet-101 등 변종들이 이미지넷 등 벤치마크에서 뛰어난 성능을 보였으며, 현재 이미지 분류의 사실상 기본 모델 중 하나다. 알파벳 형태 분류에도 ResNet을 활용하면, 사전 학습된 가중치(ImageNet 등으로)로 초기가능하고 우리 도메인(은하 이미지)으로 파인튜닝하여 좋은 성능을 기대할 수 있다. 특히 ResNet은 계층이 깊어도 학습이 잘 되므로, 우리의 경우 데이터가 충분하면 복잡한 형태 차이도 학습해낼 수 있다. (공식 구현은 TensorFlow/ PyTorch 등에 존재하며, ResNet 논문은 2015년 arXiv 등에서 공개 .)
- EfficientNet – 구글에서 제안된 모델로, 모델 스케일링(해상도, 깊이, 너비 균형 확장)에 최적화된 CNN 계열이다 . EfficientNet은 Neural Architecture Search로 설계한 Baseline 네트워크를 다양한 크기로 확장하여 B0~B7 모델들을 만들었는데, 적은 파라미터로 높은 정확도를 달성한 것이 특징이다 . 예를 들어 EfficientNet-B7은 이미지넷에서 84.3% Top-1 정확도를 내면서도 이전 최상위 ConvNet 대비 8.4배 작고, 추론 속도도 6배 이상 빠르다고 보고되었다 . 우리 작업에서는 경량 모델로서 EfficientNet-B0/B1 등을 활용해도 충분한 성능이 나오리라 예상되며, 자원 제약이 있는 경우 유리하다. EfficientNet도 공개 구현과 사전학습 가중치가 있으며, 전이학습 후 미세조정하여 사용할 수 있다.
- Vision Transformer (ViT) – (질문에 직접 언급되진 않았지만 최신 방법으로) CNN이 아닌 Transformer 구조를 영상에 적용한 모델이다. 패치 단위 임베딩과 셀프 어텐션으로 이루어진 ViT는, 대규모 데이터로 사전 학습 시 높은 분류 성능을 보인다. 알파벳 형태처럼 국소 패턴보다는 전체 윤곽이 중요한 경우, 전역적 어텐션을 가지는 ViT도 적합할 수 있다. 다만 ViT는 대용량 데이터 학습에 강점이 있으므로, 우리의 데이터 규모에 따라 효과가 달라질 수 있다.
- 기타 CNN 모델: 이 외에도 Inception (GoogLeNet), DenseNet, VGG 등 전통적인 영상분류 모델들을 고려할 수 있다. 최근에는 Swin Transformer 등 CNN과 Transformer의 장점을 절충한 모델도 나와 있다. 하지만 소규모 커스텀 분류 문제에서는 결국 ResNet 계열의 성능과 효율이 검증되어 있고 구현도 수월하므로, 먼저 ResNet/EfficientNet 위주로 시도하고 필요시 다른 구조를 테스트하는 것이 일반적이다.
3.2 이미지 생성/해석에 강한 모델들 (모델 활용 아이디어)
- CLIP (Contrastive Language-Image Pre-training) – OpenAI가 개발한 멀티모달 모델로, 웹상의 대규모 (이미지, 텍스트) 쌍 데이터로 학습되었다 . CLIP은 이미지와 텍스트를 동일한 임베딩 공간에 맵핑하여, 자연어로 묘사된 카테고리를 zero-shot으로 인식할 수 있다 . 예를 들어 라벨 없이도 “이 이미지가 ‘알파벳 X 모양의 은하’와 유사한가?”를 텍스트 쿼리로 넣어 평가할 수 있다. 이 모델을 활용하면 (1) zero-shot 분류기로 사용할 수 있고 – 각 글자에 대한 프롬프트(ex: “galaxy shaped like the letter A”)와 입력 이미지를 비교해 가장 유사한 글자 클래스를 선택 – 혹은 (2) 사전학습된 시각 특징 추출기로 활용하여 커스텀 분류기의 입력 피쳐로 사용할 수 있다. CLIP 자체는 분류 정확도 면에서 task-specific 모델만큼 정교하지 않을 수 있지만, 라벨 부족을 보완하거나 모델의 예측을 검증하는 용도로 쓸 수 있다는 장점이 있다.
- VAE (Variational Autoencoder) – 2013년 Kingma & Welling이 제안한 생성모델 기반 자동인코더이다 . VAE는 인코더-디코더 구조로 입력 이미지의 **잠재공간(latent space)**을 학습하며, 잠재벡터를 샘플링해 새로운 이미지를 생성할 수도 있다 . 우리 문제에서 VAE의 활용법은 두 가지 정도 있다: (1) 비지도 학습으로 은하 이미지의 잠재표현을 학습시켜 두 벡터 간 거리를 통해 모양 유사도를 판단하거나 클러스터링에 활용 (예: 글자 모양 유사 은하들은 잠재벡터도 서로 가깝게 분포할 가능성), (2) 학습된 VAE 디코더를 이용해
알파벳 모양 은하의 생성 –예를 들어 글자 형태를 강화한 합성 은하 이미지를 만들어 데이터 증강에 활용할 수 있다. VAE는 다른 생성모델에 비해 학습이 안정적이고 해석이 비교적 용이하여, 은하 이미지의 잠재 특성을 파악하는 데 유용하다. - GAN (Generative Adversarial Network) – 비록 질문에 직접 언급되진 않았지만, 이미지 생성 및 변환에 뛰어난 GAN 계열 모델도 고려 가능하다. 예를 들어 특정 글자 형태로 은하 이미지를 생성하는 GAN을 학습시키면 (이미지 증강에 활용) 모델이 다양한 각도와 조건의 합성 데이터를 얻을 수 있다. CycleGAN 같은 기법을 활용하면 임의 은하 이미지 -> 글자 모양 은하 이미지로의 도메인 변환도 가능할 수 있다. 다만 GAN은 훈련이 까다롭고 많은 데이터가 필요하다는 점은 고려해야 한다.
- Vison-Language 거대 모델: 예컨대 CLIP 외에도 BLIP이나 Flamingo, GPT-4 Vision과 같은 모델은 이미지에 대한 캡션이나 질문응답이 가능하다. 이러한 모델에 은하 이미지를 보여주고 “이 이미지에서 보이는 모양이 영문 알파벳 글자 중 어떤 것과 가장 비슷합니까?”와 같이 물어보아 라벨링을 자동화하는 시도도 가능하다. 특히 최신 GPT-4 같은 모델은 사람 수준의 관찰로 “이 은하는 S자 형태로 휘어져 있다”고 묘사할 가능성이 있다. 다만 이 방법은 아직 신뢰도나 비용 측면에서 보조적 수단일 뿐이며, 본격적인 분류 모델은 아닌 점을 감안해야 한다.
4. 이미지 전처리 방식 및 데이터 증강 전략
- 중심 정렬 (Centering): 은하의 중심을 이미지의 중앙에 오도록 정렬한다. 많은 천문 이미지에서 은하가 프레임 한쪽에 치우쳐 있거나 배경 여백이 많을 수 있는데, 이를 방지하기 위해 은하 중심 좌표(예: 광도 중점)를 계산하여 잘라내고 일정한 크기로 리사이즈한다. 중심 정렬로 모델이 일관된 위치에서 패턴을 학습하도록 돕는다.
- 회전 보정: 알파벳 글자는 회전각에 따라 인식이 달라진다. 일반적으로 사람이 “글자처럼 보인다”고 인식하려면 수평 기준으로 정상적인 방향에 가까운 각도가 유리하다. 따라서 필요시 이미지를 회전시켜 해당 은하 형태가 가장 글자답게 보이는 각도로 맞춘다. 예를 들어 ‘ㄱ’자 모양 은하가 45도 기울어져 있다면 직각이 되도록 보정한다. 다만 어떤 글자는 회전해도 여전히 같은 글자로 인식될 수 있지만(O, X 등), 어떤 것은 다르게 보일 수 있다(N을 90도 회전하면 Z 모양). 일괄적인 회전 증강 이전에, 사람이 본 기준 방향으로 정렬하는 것이 바람직하다. (이 단계는 향후 학습된 모델이 회전 불변성을 갖도록 할지 여부에 따라 조정 가능하다.)
- 색상/채널 처리: 은하 이미지는 종종 여러 필터(밴드) 합성 컬러이지만, 형태 인식에는 명암 대비가 주로 중요하다. 색 정보를 제거하고 **그레이스케일(흑백 변환)**로 입력을 단순화할 수 있다. 이는 모델 파라미터 수 감소와 오버피팅 억제에 도움이 된다. 반면 색상으로 인한 구조적 강조(예: 별형 성단이 파란색으로 드러남)를 잃을 수 있으므로, 필요에 따라 채널별 정규화나 PCA 등을 적용할 수도 있다. 기본적으로는 흑백 변환 후 대비 조정(Histogram equalization 등)으로 형태를 두드러지게 하는 것을 권장한다.
- 노이즈 제거 및 정규화: 천문 이미지 특성상 노이즈(검출 한계, 센서 잡음)가 존재한다. 가우시안 블러로 약간 부드럽게 하거나 로컬 콘트라스트 필터로 잡음을 억제해 형태를 부각시킨다. 또한 입력 정규화 (평균 0, 표준편차 1 스케일링)를 통해 밝기 범위를 통일한다.
- 크기 및 해상도 통일: 모델 입력 크기에 맞춰 모든 이미지를 동일 해상도로 리사이즈한다 (예: 224×224 픽셀 등). 이때 aspect ratio를 크게 왜곡하지 않도록, 중앙을 자른 뒤 패딩하거나, 최대 영역에 맞춰 비율을 유지한 채 리사이즈하는 방안을 쓴다. 글자 모양 판단에는 비율 유지가 중요할 수 있다 (예: 원형 은하를 지나치게 찌그러뜨리면 O->0처럼 보일 수 있음).
이러한 전처리 후, 데이터 증강을 통해 모델의 일반화 성능을 높인다. 다만 증강 시 주의점은, 알파벳 형태라는 라벨을 훼손하지 않는 범위여야 한다는 것이다. 예를 들어 임의 회전을 과하게 적용하면 글자의 방향성이 바뀌어 다른 글자로 인식될 위험이 있다. 아래는 적절한 증강 기법들이다:
- 소폭 회전 (Rotation): ±10도 이내의 경미한 회전을 무작위 적용하여, 동일 글자 모양에 대한 경사 변화에 모델이 견고하도록 한다. 90도 단위의 큰 회전은 지양한다 (예: ‘N’이 90도 회전하면 ‘Z’처럼 보일 수 있으므로). 만약 모델을 “회전에 상관없이 글자 모양 인식”으로 설계한다면 작은 각도 범위 내에서만 증강을 주어 모델이 약간의 기울기 변화에 robust하도록 한다.
- 스케일링 및 위치 변환: 은하 크기나 화각이 다를 수 있으므로, 이미지에 랜덤 확대/축소(예: 0.8~1.2배) 및 약간의 평행이동(translation) 증강을 준다. 이는 모델이 중심 위치나 크기에 조금 변동이 있어도 특징을 잡도록 돕는다. 주의할 점은 너무 크게 확대하여 테두리 일부가 잘리면 글자 형태 단서가 사라질 수 있으므로, 확대는 제한적으로 적용한다.
- 좌우 대칭 플립: 대부분 알파벳은 좌우 대칭이 아니므로, 좌우반전시 글자가 달라질 위험이 있다. 예를 들어 ‘b’와 ‘d’는 좌우 반전 관계이고, ‘L’은 대칭 시 ‘⅃’ (다른 모양)가 된다. 따라서 수평/수직 뒤집기 증강은 일반적으로 하지 않는다. 다만, ‘O’나 ‘X’처럼 대칭적인 글자는 상관없지만, 데이터 전체에 일괄 적용하기엔 부적절하다.
- 광학 변동 증강: 망원경 이미지의 다양성을 모사하기 위해 밝기, 대비, 색상 변동을 준다. 예를 들어 랜덤하게 이미지의 전체 밝기를 ±20% 변경하거나, 가우시안 노이즈를 추가하여 센서 노이즈 상황을 흉내낸다. 약간의 블러를 추가해 해상도 차이를 모사할 수도 있다. 이러한 증강은 모델이 조명조건이나 노이즈 변화에 견고해지는 효과가 있다.
- 배경 별도 처리: 알파벳 형태 인식에는 은하 본체의 형태가 중요하고, 배경의 별이나 잡음은 방해가 될 수 있다. 필요하면 배경 제거 또는 마스크 적용도 고려된다. 예를 들어 은하의 임계 밝기 이하 영역을 검게 처리하거나, 별점 같은 작은 원형 광원을 제거하는 전처리를 해둘 수 있다. 또는 증강 차원에서 배경에 별자리 이미지를 합성하여 다양한 배경에서도 robust하게 만드는 것도 가능하다.
5. 학습 데이터 라벨링 및 라벨 수집 방법
모델 학습을 위해서는 충분한 라벨링된 데이터(은하 이미지 → 해당 알파벳 글자)가 필요하다. 그러나 알파벳 형태라는 라벨은 일반 천문 데이터에 존재하지 않으므로, 라벨 수집 전략이 필요하다:
- 크라우드소싱을 통한 라벨 수집: 앞서 2항목에서도 논의한 것처럼, 대중 참여를 활용해 라벨을 얻는 방법이다. Galaxy Zoo와 같은 플랫폼을 이용하여 은하 이미지와 26개 알파벳 옵션(또는 “해당 없음”)을 제시하고, 참가자가 직관적으로 보이는 글자를 선택하게 한다. 각 이미지에 대해 다수결로 가장 많이 선택된 글자를 라벨로 지정하고, 모호한 경우 (표결 분산 또는 “None” 다수) 제외하는 방식이다. 예를 들어 어떤 은하에 100명의 투표 중 80명이 “Z”로 응답했다면 해당 은하는 Z형으로 라벨링하고, 100명 중 30%A, 30%H, 40% 기타 이렇게 의견이 갈리면 해당 이미지는 제외하거나 “모호” 라벨로 분류한다. 태스크 설정은 PC, 모바일에서 쉽게 할 수 있도록 직관적으로 하고, 보상이나 게이미피케이션 요소를 도입하면 참여를 높일 수 있다. 크라우드소싱의 장점은 사람의 인지 능력을 활용해 기계가 찾기 어려운 패턴을 잡아낸다는 것인데 , 단점은 시간이 걸리고 품질 관리가 필요하다는 것이다. 품질 향상을 위해 골드 스탠다드 이미지를 일부 섞어 참가자 신뢰도를 추정하거나, 활동 상위 참가자 그룹의 검증 단계를 추가할 수도 있다.
- 전문가 또는 소규모 인력 라벨링: 만약 크라우드소싱이 어렵다면, 소수의 천문학자/학생 인턴들이 수작업으로 라벨링하는 방법도 있다. 예비 단계로 공개 천문 이미지 아카이브에서 알파벳 사례로 보이는 것들을 수백 개 수집하고, 이를 확장하는 방식이다. 이 접근은 데이터량이 적을 수밖에 없으나 정확도는 비교적 높을 수 있다. 작은 셋으로 모델을 훈련시킨 뒤, 모델이 새로운 데이터에서 예측한 결과를 수동 검토하며 라벨을 확충하는 active learning 방식으로 진행 가능하다.
- Vision-Language 모델 활용 (자동 라벨링): 앞서 3항목에서 언급한 CLIP이나 GPT-4 Vision 등의 사전학습 멀티모달 AI를 라벨링에 활용할 수 있다. 예를 들어 CLIP을 활용하면, 각 은하 이미지에 대해 “This galaxy looks like the letter [A/B/…]”라는 문장들 각각과 이미지를 입력하여 가장 높은 유사도를 보이는 문장을 찾는다. 이를 해당 은하의 예측 글자로 간주해 자동 라벨을 달 수 있다. OpenAI의 CLIP 연구에서도 자연언어 카테고리 이름만으로 이미지 분류가 가능함을 보여주었는데 , 이를 우리의 알파벳 분류에 적용하는 것이다. 다만 CLIP의 판단이 항상 사람 직관과 일치하지 않을 수 있으므로, 후처리로 사람 검증을 거치거나 높은 컨피던스 결과만 채택하는 식으로 신뢰도를 담보해야 한다. 또 다른 방법으로, 이미지 캡션 생성 모델(예: BLIP-2 등)에게 은하 이미지를 설명하게 한 뒤, 생성된 문장에 특정 글자 언급이 있는지 찾는 방식도 가능하다. 예컨대 모델 설명에 “S-shaped galaxy”라고 나오면 라벨 S로 추정하는 식이다. 이러한 Vision-Language 모델들은 100% 정확도를 기대하기 어렵지만, 라벨링 작업량을 줄이는 보조 도구로 활용하면 유용하다.
- 반자동 및 능동 학습: 소량의 정확한 라벨로 모델을 학습시킨 후, 미라벨 데이터에 예측을 적용하여 후보 라벨을 얻는다. 그리고 사람이 그 결과를 확인/수정하여 확정 라벨로 만든다. 이를 반복하면 갈수록 라벨링 속도를 높일 수 있다. 예를 들어 1,000장의 라벨드 데이터를 모델에 학습시킨 뒤, 새로운 10,000장에 대해 예측하게 하고, 그 중 모델 신뢰도가 높은 2,000장은 그대로 라벨 채택, 애매한 8,000장은 사람 검토. 검토 후 10,000장의 라벨이 완성되면 다시 모델 재학습… 이런 식으로 Active Learning을 수행하면 라벨링 비용을 절감할 수 있다.
결론적으로, 현실적으로는 시민과학 크라우드소싱이 가장 방대한 라벨 확보 수단이며 이미 Galaxy Zoo로 그 유효성이 입증되었다. 보조적으로 최신 AI 모델을 활용하면 속도를 높일 수 있다. 최종 라벨은 가능하면 다수 인원의 합의 또는 전문가 확인을 거친 신뢰성 높은 라벨이어야 모델 평가와 활용 단계에서 혼선을 줄일 수 있다.
음....
비지도학습으로는 음..
알파벳 라벨이 없는 은하 이미지들만 가지고,
비지도 학습으로 “알파벳 형태”처럼 보이는 패턴을 스스로 구분하거나 묶게 만들 수 있을까?
비지도 표현 학습 + 클러스터링 + 사람 피드백 loop
라벨 없이도 은하 이미지들을 “형태(특히 알파벳 유사)” 기준으로 그룹화 또는 임베딩해서
나중에 사람이 볼 수 있는 의미 있는 패턴(예: 알파벳 모양 군집)을 찾거나 뽑아낼 수 있는 모델을 만든다.
🔹 비지도/자기지도 학습 프레임워크
다음은 은하 이미지에 적합한 비지도 또는 약지도 학습 방법들이야:
✅ (1) SimCLR / BYOL / DINO (자기지도 Contrastive Learning)
- 아이디어: 은하 이미지를 다양한 증강 버전으로 만들고,
- 서로 유사한 인스턴스를 서로 가깝게, 다른 인스턴스는 멀어지게 학습
- 장점:
- 라벨 없이도 형태 기반 임베딩 공간 생성 가능
- 나중에 군집화(Clustering) 또는 K-NN으로 유사 이미지 탐색 가능
- 적용 방식:
- 은하 이미지에 회전, 밝기, 노이즈 증강을 랜덤 적용
- 임베딩 벡터 학습 → UMAP, t-SNE로 시각화
- 비슷한 모양끼리 잘 모이면 → 알파벳 후보 군집 추출 가능
✅ (2) VAE (Variational Autoencoder)
- 아이디어: 은하 이미지를 잠재공간(latent space)에 압축
- 비슷한 이미지가 가까운 위치에 매핑되도록 학습
- 활용:
- 잠재 공간에서 KMeans로 클러스터링
- 시각적으로 유사한 패턴끼리 모이게 됨
- 클러스터별 대표 이미지를 확인 → “이건 G처럼 생겼다”, “이건 M 같다” 등
✅ (3) SwAV, DeepCluster, Barlow Twins
- 이미지 분류용 최신 비지도 학습 기법으로,
- 입력 이미지들을 feature space로 매핑
- 정적 클러스터링을 동적으로 학습과 연결
- 장점: CLIP이나 ResNet 기반 백본에 연결하여 강한 표현력 확보
🔹 라벨 없이 알파벳 후보를 찾는 파이프라인
[은하 이미지]
↓
[자기지도 학습 (SimCLR / DINO / VAE 등)]
↓
[2D 임베딩 (UMAP or t-SNE)]
↓
[클러스터링 (DBSCAN, KMeans)]
↓
[사람이 클러스터 대표 이미지 보고 알파벳 할당]
↓
[작은 라벨셋 → 모델 미세학습 / 자동확장]
참고자료: 공개 데이터셋 정보 , Galaxy Zoo 프로젝트 사례 , ResNet/EfficientNet 논문 , OpenAI CLIP 보고 , VAE 개요 등.
🏆 은하 알파벳 조합 알고리즘 개발
“알파벳 모양을 가진 은하들 사이의 실제 우주 공간 내 거리”를 기반으로, “가까이 있는 알파벳 은하들을 조합해 단어를 만들 수 있을까?”
“공간적으로 가까운 알파벳 은하 → 의미 있는 단어”를 찾는 위치 기반 애너그램 생성 알고리즘
?
천문 공간 상의 위치 정보(예: 라덱/적경적위)와 알파벳 분류 결과를 활용해서, 단어를 만드는 공간적 패턴 탐색 문제
✅ 문제 정의
- 입력:
- 각 은하의 위치 정보: (RA, Dec) 또는 (x, y, z)
- 각 은하의 알파벳 분류 결과: 'A' ~ 'Z'
- 목표:
- 공간적으로 가까운 은하들끼리 모아서 가능한 한 단어가 되는 조합을 찾기
✅ 접근 방식 요약
| 1. | 알파벳 모양으로 분류된 은하들에 대해 위치 좌표를 포함한 정보 저장 |
| 2. | 모든 은하 쌍 사이의 거리 계산 (또는 k-NN 그래프 구성) |
| 3. | 거리 기준으로 가까운 은하 군집(예: 반경 5도 이내)을 찾음 |
| 4. | 해당 은하들의 알파벳 조합으로 만들 수 있는 단어 후보 탐색 |
| 5. | 사전(dictionary) 매칭으로 실제 단어 필터링 |
✅ 알고리즘 예시 3가지
🔹 1. Sliding Sphere + Dictionary Match
개념:
- 우주 공간에서 반경 r을 가진 구(sphere)를 슬라이딩하며
- 구 안에 들어오는 알파벳 은하들을 조합 → 단어 후보 생성
- 조합된 알파벳이 실제 사전에 있는 단어인지 확인
예시 흐름:
- 모든 은하에 대해 반경 r 이내에 있는 이웃 은하 리스트 구성
- 이웃 은하들이 총 n개일 때, 그들의 알파벳으로 만들 수 있는 모든 n! 조합 계산
- 조합 중 실제 단어 존재 여부 확인
🔹 2. Graph-based Word Search
개념:
- 은하들을 노드로 하고, 두 노드 사이의 거리가 일정 기준 이하면 간선 연결
- 이 그래프 위에서 DFS/BFS로 길이 n의 경로를 탐색하면서
- 해당 경로의 알파벳 조합이 단어가 되는지 확인
장점:
- 단어를 순차적으로 형성하는 구조와 유사
- 긴 단어 탐색에 유리하고 효율적 pruning 가능
응용:
- 예: 3글자 단어는 길이 3의 경로 → DFS(node, depth=3)로 탐색
🔹 3. Spatio-Textual Pattern Mining (빈발패턴 탐색 기반)
개념:
- 은하 간 거리 기반으로 dense cluster (군집)를 찾고
- 그 군집에서 자주 나오는 알파벳 조합을 탐색
- 이는 “어떤 위치 집단에 의미 있는 단어들이 형성되었는가?”를 찾는 데 유용
적용 알고리즘:
- DBSCAN 등 군집 알고리즘 + 텍스트 빈발 패턴 매칭
- 예: Apriori, FP-Growth, Aho-Corasick
✅ 평가 지표/아이디어
- 단어 길이: 더 긴 단어를 만드는 클러스터가 우선
- 위치 응집도: 단어를 구성한 은하들이 더 밀집되어 있을수록 높은 점수
- 문장 생성 가능성: 단어 간 거리 고려하여 문장도 생성 가능할지 여부
✅ 추가 확장 가능성
- 시각화: 3D 공간에 알파벳 은하 위치를 나타내고, 단어 후보가 되는 클러스터를 선으로 연결
- 다중 단어 구성: 전체 은하 집합에서 최대한 많은 단어 조합 생성 후 “은하 문장” 구성
- 우주 시 쓰기: “LOVE”, “STAR”, “HOPE” 같은 단어를 우주 속 은하로 이루어진 조각처럼 구성
'Club|Project > 졸업 연구 | 멀티모달 AI를 이용한 은하 병합 단계 분류' 카테고리의 다른 글
| 🌌 [Determining the time before or after a galaxy merger event] - 경쟁 논문 (0) | 2025.05.22 |
|---|---|
| 🌌 SpaceAI 천문연구원 킥오프 미팅 (1) | 2025.05.20 |
| 🌌 충돌 은하 분류 연구 : 지웅배 교수님 진행 계획 정리 (0) | 2025.05.20 |
| 🌌 [Identifying galaxy mergers in observations and simulations with deep learning] 논문 공부 (0) | 2025.05.15 |
| 🔭 LSST with AI : day 2 (0) | 2025.05.14 |


