Determining the time before or after a galaxy merger event
<BR /> Aims: This work aims to reproduce the time before or after a merger event of merging galaxies from the IllustrisTNG cosmological simulation using machine learning. <BR /> Methods: Images of merging galaxies were created in the u, g, r, and i bands f
ui.adsabs.harvard.edu
🌌 ABSTRACT
목표
이 연구의 목표는 IllustrisTNG 우주론 시뮬레이션에서 병합 중인 은하들의 병합 전후 시간을 머신러닝을 이용해 재현하는 것이다.
방법
병합 은하들의 이미지를 IllustrisTNG 시뮬레이션에서 u, g, r, i 밴드로 생성하였다. 병합 시간은 병합 은하가 두 개의 은하로 추적되던 마지막 스냅샷과 단일 은하로 추적되기 시작한 첫 번째 스냅샷 간의 시간 차이로 계산되었다. 이 시간은 간단한 중력 시뮬레이션을 통해 추가로 정제되었다. 이렇게 얻은 데이터를 기반으로 병합 시간을 예측하기 위해 ResNet50, Swin Transformer, CNN, 그리고 하나의 잠재 뉴런을 갖는 오토인코더를 훈련시켰다. 또한 오토인코더의 전체 잠재 공간이 다른 방법들보다 병합 시간을 더 잘 재현할 수 있는지도 분석하였다. 이 때 차원 축소 방법으로 Isomap, 선형 판별 분석(LDA), 이웃 성분 분석(NCA), 희소 랜덤 투영(SRP), 절단 특이값 분해(TSVD), 그리고 UMAP을 사용했다.
결과
CNN이 가장 우수한 성능을 보였고, 오토인코더가 그 다음으로 근접한 성능을 나타냈으며 Swin Transformer는 그보다 약간 뒤떨어졌다. ResNet50은 가장 성능이 낮았다. 차원 축소 기법 중에서는 LDA가 가장 뛰어났다. 전체 잠재 공간을 활용한 예측은 오히려 단일 잠재 뉴런을 활용한 오토인코더보다 성능이 낮았다. 테스트 데이터셋에 대해 병합 시간의 중앙 오차는 약 190 Myr로, IllustrisTNG 스냅샷 간 시간 간격과 유사하다. 병합 약 625 Myr 이전 또는 병합 후 125 Myr 이상 지난 은하들에 대해서는 병합 시간 예측이 부정확했다.
핵심어
수치 방법 – 은하의 진화 – 은하 상호작용 – 은하 통계 – 은하 구조
🌌 1. Introduction
은하 병합은 우주적 시간 규모에서 은하가 성장하고 진화하는 방식에 있어 핵심적인 요소로 여겨진다. 냉암물질 패러다임(cold dark matter paradigm) 하에서, 암흑물질 헤일로는 계층적으로 병합하며, 이로 인해 해당 헤일로에 포함된 은하들도 함께 병합하게 된다 (예: Conselice 2014; Somerville & Davé 2015). 이러한 병합은 조석 꼬리(tidal tail)의 생성 같은 단기적인 형태 변화뿐만 아니라, 늦은 형 은하에서 이른 형 은하로의 전환과 같은 장기적인 변화를 초래한다 (예: Taranu et al. 2013).
이러한 단기적인 형태 변화는 은하 병합을 식별하는 데 활용된다. 시각적 은하 병합 판별은 전문가와 일반 천문학자 모두가 상호작용으로 인해 발생한 왜곡과 희미한 구조들을 식별하는 것에 의존한다 (예: Lintott et al. 2008; Holwerda et al. 2019; Pearson et al. 2022). 이러한 교란은 또한 병합 은하의 파라메트릭 및 비파라메트릭 특성에 변화를 일으켜, 집중도(concentration), 비대칭도(asymmetry), 평활도(smoothness) 같은 지표(CAS; Conselice et al. 2000, 2003)나 지니 계수(Gini) 및 M20 (Lotz et al. 2004, 2008; Snyder et al. 2015; Rodriguez-Gomez et al. 2019)를 이용한 병합 판별이 가능하게 한다. 은하 병합이 일어나기 위해서는 가까운 거리와 낮은 상대 속도가 필요하므로, 가까운 은하 쌍을 식별하는 방법도 병합 후보를 찾는 데 활용된다 (예: Barton et al. 2000; De Propris et al. 2005; Robotham et al. 2014; Rodrigues et al. 2018; Duncan et al. 2019). 형태 기반 식별은 일반적으로 병합 이후 은하(post-mergers)를 식별하고, 쌍 기반 방법은 병합 이전 은하(pre-mergers)를 식별하는 데 적합하다. 두 가지 방법에 모두 걸리는 은하는 병합 중인 은하일 가능성이 크다 (Desmons et al. 2023). 그러나 이러한 모든 방법은 잘못된 분류와 샘플 내 오염 문제를 피하기 어렵다 (예: Huertas-Company et al. 2015; Pearson et al. 2019).
병합 탐지의 성능을 향상시키기 위해, 천문학자들은 머신러닝 기법에 주목하고 있다. 지난 몇 년간 컨볼루션 신경망(CNN)은 병합 은하와 비병합 은하를 이미지로 구분하는 데 활용되어 왔다 (예: Ackermann et al. 2018; Bottrell et al. 2019; Pearson et al. 2019, 2022; Walmsley et al. 2019; Ćiprijanović et al. 2020; Wang et al. 2020; Bickley et al. 2021, 2022). 이러한 접근은 CNN이 이미지 내 희미한 구조를 감지할 수 있는 능력에 의존한다 (예: Pearson et al. 2022). 머신러닝은 형태 지표 (Snyder et al. 2019; Pearson et al. 2022; Guzmán-Ortega et al. 2023; Margalef-Bentabol et al. 2024)와 광도 측정값(Suelves et al. 2023)에도 적용되어, 병합 은하와 비병합 은하를 성공적으로 구분하고 있다. 이러한 모델들은 대개 7585%의 정확도를 보인다. 한편, 병합 이전(pre-merger), 병합 이후(post-merger), 비병합(non-merger) 등으로 세분화된 분류는 더 어렵고, 이 경우 정확도는 6575% 수준에 머무른다 (Ferreira et al. 2020; Margalef-Bentabol et al. 2024).
은하 병합은 병합 은하의 물리적 특성에도 영향을 주는 것으로 알려져 있다. 병합 중인 은하의 별 형성률(SFR)은 극적으로 증가할 수 있고, 활동 은하핵(AGN)의 활동성 또한 변할 수 있다. 그러나 이러한 물리적 특성 변화의 양상은 연구에 따라 상반된 결과를 보인다. 어떤 연구는 병합이 별 폭발(starburst)을 일으킨다고 보고하고 (예: Sanders & Mirabel 1996; Pearson et al. 2019), 다른 연구는 별 형성 증가가 미미하거나 오히려 감소한다고 보고한다 (예: Ellison et al. 2013; Silva et al. 2018; Knapen et al. 2015). AGN 활동성 변화도 마찬가지로 증가하거나 감소했다는 보고가 엇갈린다 (예: Weston et al. 2017; Gao et al. 2020; Steffen et al. 2023 vs. Silva et al. 2021).
이러한 불일치는 병합 단계에 따라 물리적 변화가 달라지기 때문일 가능성이 크다. 예를 들어, FIRE-2 시뮬레이션 (Hopkins et al. 2018)에서는 병합 은하의 SFR이 병합 전후 시점에 따라 달라진다는 결과를 보였고 (Moreno et al. 2019), IllustrisTNG 시뮬레이션에서도 AGN 활동이 병합 후 시간이 지날수록 감소하는 경향을 보였다 (Pillepich et al. 2018; Byrne-Mamahit et al. 2023). 하지만 병합 여부를 넘어서 병합이 ‘얼마나 전이었는가/후였는가’를 정확히 판단하는 것은 아직도 어렵다.
병합 시간을 머신러닝과 시뮬레이션을 통해 추정하는 시도가 최근 시작되었다. 시뮬레이션은 병합 전후 시점을 제공해줄 수 있지만, 제약도 존재한다. 고해상도 zoom-in 시뮬레이션은 시간 해상도는 높지만 샘플 수가 적고, 우주론적 시뮬레이션은 샘플은 많지만 시간 해상도는 낮다 (보통 100 Myr 수준).
병합 시간 추정에 대한 연구는 이제 막 시작 단계다. 예를 들어 Koppula et al. (2021)은 Horizon-AGN 시뮬레이션 데이터를 기반으로 신경망을 훈련시켜 허블 우주망원경 스타일의 병합 은하 이미지로부터 병합 전후 시간을 예측하였다. 병합 탐지 모델의 품질은 점차 상향 평준화되고 있지만, 병합 시간 추정은 아직 많은 연구가 필요한 단계다.
이 논문에서는 병합 전후 시간을 추정하는 다양한 방법들을 비교하고자 한다. 우리는 IllustrisTNG 시뮬레이션에서 병합 은하를 선정하고, 중력 시뮬레이션을 통해 시간 해상도를 개선하였다. 이후 은하 이미지와 병합 시간을 기반으로 네 가지 신경망 구조를 훈련시켜 결과를 비교하였다.
🌌 2. Data
실제 우주에 존재하는 은하들에 대해 병합 전후 시간(merger time)을 아는 것은 본질적으로 불가능하다. 그러나 이러한 병합 시간은 일정한 한계는 있지만, 우주론적 시뮬레이션 내에서는 비교적 정확히 알 수 있다.
이 연구에서는 IllustrisTNG 시뮬레이션의 TNG100-1 런(Marinacci et al. 2018; Naiman et al. 2018; Nelson et al. 2018, 2019; Pillepich et al. 2018; Springel et al. 2018)에서 식별된 은하 병합 데이터를 사용하였다. TNG100-1은 한 변이 75 comoving kpc/h 크기인 박스 안에 18203개의 암흑물질 입자를 시뮬레이션한 것으로, Planck 2015 우주론(Planck Collaboration XIII 2016)을 기반으로 하고 있으며, 소프트닝 길이는 0.5 ckpc/h이다. 이 박스 안의 가스 셀은 평균 질량이 9.44 × 10⁵ M☉/h이며, 암흑물질 입자는 5.056 × 10⁶ M☉/h이다. TNG100 시리즈 중에서 TNG100-1은 가장 높은 해상도를 가진다. 시뮬레이션 스냅샷 간의 시간 간격은 30 Myr에서 234 Myr 사이이며, 평균적으로는 약 138 Myr이다. 낮은 적색편이일수록 스냅샷 간 시간 간격이 더 길다.
IllustrisTNG에서 생성된 은하들은 관측된 은하와 형태적으로 유사하다는 점이 알려져 있으며, 질량에 따른 형태, 크기, 모양의 경향성이 관측된 경향과 1σ 수준에서 일치한다 (Rodriguez-Gomez et al. 2019). 다만, 색-형태 관계는 약하고, 실제 우주와는 달리 동일한 질량을 가진 원반 은하가 타원 은하보다 더 크지는 않다.
우리는 병합 은하를 병합 후 500 Myr 이내(post-merger) 또는 병합 전 1000 Myr 이내(pre-merger)인 은하로 정의한다. 이 병합 시점은 병합이 일어난 스냅샷과 관측 스냅샷(현재 은하가 존재하는 시점)의 상대적인 차이를 기반으로 정의된다 (Wang et al. 2020). 병합 스냅샷은 하나의 은하로 병합된 것이 처음으로 식별된 시점이며, 그 직전 스냅샷에서는 두 개 이상의 은하로 추적되었다. 주 병합(major merger)는 병합되는 두 은하 중 질량이 큰 은하의 별질량 대비 두 번째로 큰 은하의 별질량 비율이 1:4보다 작은 경우로 정의한다 (Rodriguez-Gomez et al. 2015). 또한 병합 은하의 바리온 성분(별 + 별 형성 가스)의 총질량이 1×10⁹ M☉/h 이상이어야 한다.
이러한 조건을 만족하는 주요 병합 은하들을 스냅샷 87번부터 93번까지에서 선택하였으며, 이는 0.07 ≤ z ≤ 0.15 구간에 해당한다. 이 범위는 Pearson et al. (2019)의 KiDS 병합 은하 카탈로그 상한과 일치하며, 낮은 적색편이 한계는 병합 전 시간을 충분히 확보할 수 있도록 하였다. 하나의 은하가 여러 스냅샷에서 병합 은하로 식별되면 각 스냅샷마다 중복 포함될 수 있다. 이 과정을 통해 총 6139개의 주요 병합 은하가 선택되었다.
병합 시간의 시간 해상도를 높이기 위해, 간단한 중력 시뮬레이션을 수행하였다. 각 은하는 점질량으로 간주되어, 병합 과정에 관련된 다른 은하들과의 중력 상호작용만을 고려하여 움직이도록 하였다. 이때 소프트닝 길이는 TNG100과 일치하도록 0.5 ckpc/h로 설정하였다. 주 은하의 질량 대비 1:10 이하의 질량을 가진 은하들만 상호작용에 포함시켰다. 이는 작은 은하들도 상호작용에 영향을 줄 수 있기 때문이다. 시뮬레이션은 스냅샷 간 시간 범위에서 1 kyr의 시간 간격으로 실행되었고, 두 은하의 최초 근접점(first closest approach)이 병합 시점으로 간주되었다. 병합이 다중 은하 간에 발생할 경우, post-merger에서는 마지막으로 가까이 접근한 은하를 기준으로 병합 시점을 정하고, pre-merger에서는 최초로 접근한 은하를 기준으로 병합 시점을 정했다. 이 병합 시간은 가장 가까운 1 Myr 단위로 반올림하였다. 만약 시뮬레이션에서 근접점이 나타나지 않으면 해당 은하는 제외되었다. 또한 pre-merger와 post-merger 양쪽 모두로 분류된 모호한 은하도 제외하였다. 이 과정으로 2818개 은하가 제외되어, 최종적으로 병합 시간이 명확히 정의된 3321개 은하가 사용되었다. 이 은하들은 모두 0.07 ≤ z ≤ 0.15의 범위를 가진다.

우리는 병합 시간을 “병합 전 시간(time before merger)“으로 정의하며, 따라서 post-merger 은하의 경우 병합 시간은 음수이다. 이 병합 시간은 0~1 사이의 범위로 정규화되었는데, -500 Myr는 0에, +1000 Myr는 1에 매핑된다. 이 정규화된 시간은 이후 분석 전반에서 사용된다. Fig. 1에서 볼 수 있듯이, pre-merger 은하의 병합 시간과 이미지 생성 시점의 은하 간 투영 거리 사이에는 강한 상관관계가 없다 (Pearson 상관계수 = 0.277, p < 0.001; Spearman = 0.407, p < 0.001). 각 은하에 대해 x, y, z 방향으로 3개의 이미지를 생성하였으며, 총 9963개의 이미지가 만들어졌다.

이미지 생성은 각 별 입자마다 Bruzual & Charlot (2003) 모델을 기반으로 스펙트럼을 생성하고, 이를 KiDS의 u, g, r, i 밴드 필터에 통과시켜 2D 이미지로 변환하였다 (Rodriguez-Gomez et al. 2019). 이미지의 해상도는 KiDS와 동일한 0.2 arcsec/pixel이고, 은하 중심을 기준으로 128×128 픽셀의 크롭 이미지를 사용하였다. pre-merger 은하의 동반 은하가 이미지 안에 반드시 포함되어야 한다는 조건은 없었으며, 이는 pre-와 post-merger 은하가 외형적으로 다를 것이라 가정했기 때문이다. 먼지에 의한 복사 전달 처리는 하지 않았는데, 이는 Bottrell et al. (2019)이 제시한 바와 같이 이러한 처리가 병합 은하 분류에서 성능 향상에 거의 영향을 미치지 않기 때문이다. 일부 이미지 예시는 Fig. 2에 제시되어 있다.
🌌 3. Neural networks
신경망은 생물학적 신경계가 정보를 처리하는 방식에서 착안하여 설계된 머신러닝 기법의 한 종류다. 이 연구에서는 지도 회귀(supervised regression)를 수행한다. 즉, 이미 병합 시간이 알려진 데이터를 활용해 연속적인 값(병합 시간)을 예측하도록 네트워크를 학습시킨다. 이를 위해 아래 네 가지 신경망 구조를 실험했다:
- ResNet50 (Residual Network)
- Swin Transformer (Swin)
- 컨볼루션 신경망 (CNN)
- 오토인코더 (Autoencoder)
데이터는 다음 세 가지 하위셋으로 나뉘어 사용된다:
- 학습 세트: 전체 데이터의 약 70~90%로 구성되며, 신경망을 실제로 학습시키는 데 사용된다.
- 검증 세트: 전체 데이터의 약 5~15%로 구성되며, 학습 중 네트워크 성능을 평가하고 최적의 하이퍼파라미터를 찾는 데 활용된다.
- 테스트 세트: 전체 데이터의 약 5~15%로 구성되며, 최종 학습이 완료된 후 단 한 번만 모델의 성능을 평가하는 데 사용된다.
본 연구에서는 학습:검증:테스트 비율을 80:10:10으로 설정했다.
모든 아키텍처에서 학습 시 이미지 증강을 적용했으며, 검증 세트에는 적용하지 않았다. 증강 방식은 다음과 같다:
- 이미지를 무작위로 90도 단위로 회전
- 그 후 무작위로 수평/수직으로 뒤집기
- → 이로써 학습 세트는 이론상 16배 증가한 효과를 얻는다. (단, 이는 실제로 새로운 데이터를 얻는 것만큼의 효과는 아니다)
이미지의 각 밴드는 개별적으로 두 번의 arcsinh 변환을 거쳐 0~1 범위로 정규화되었다. 이는 향후 실제 관측 이미지에도 적용 가능한 모델을 만들기 위함이며, 밴드 간의 상관관계(시뮬레이션에는 존재하지만 실제에는 없을 수 있음)가 학습에 영향을 주는 것을 방지하기 위한 전략이다.
모든 모델은 TensorFlow 프레임워크(Abadi et al. 2015)를 기반으로 구축되었으며, 1000 에폭(epoch) 동안 학습되었고, 검증 세트에서 병합 시간에 대한 MSE(Mean Squared Error)가 가장 낮았던 에폭을 선택하였다.
해당 코드와 학습된 모델은 다음 깃허브에서 다운로드 가능하다:
👉 https://github.com/wjpearson/TNGMergerTime
오 굿
3.1 ResNet50
ResNet(Residual Network; He et al. 2016)은 딥러닝에서 깊은 네트워크의 성능 저하 문제를 해결하기 위해 잔차 학습(residual learning)을 사용하는 구조다. 각 컨볼루션 블록 사이에 스킵 연결(skip connection)을 도입함으로써, 입력이 컨볼루션 블록을 거치지 않고도 다음 블록으로 전달될 수 있다.
이 구조는 원래 이미지 분류에 쓰였지만, 본 연구에서는 회귀에도 활용했다. 우리는 50개 블록으로 구성된 ResNet50을 사용했고, 기존의 완전 연결층을 제거한 뒤 하나의 출력 뉴런(시그모이드 활성화 함수)을 추가하여 병합 시간을 예측하도록 했다. 입력은 u, g, r 밴드로 구성된 3채널 128×128 이미지이며, 학습에는 MSE 손실 함수와 Adam 옵티마이저(Kingma & Ba 2015)를 사용했다.
3.2 Swin Transformer
Swin Transformer(Chen et al. 2021; Liu et al. 2021)는 윈도우 기반 어텐션을 활용한 비전 트랜스포머 구조로, 이 연구에서는 ImageNet-1K로 사전학습(pre-trained)된 모델을 사용하였다.
출력층으로는 병합 시간을 예측하는 단일 출력 뉴런(시그모이드 활성화)을 추가했다. Swin은 사전학습된 모델이기 때문에 입력은 반드시 3채널이며, 이미지 크기는 224×224이어야 한다. 이를 맞추기 위해 u, g, r 밴드를 사용하여 3채널 이미지를 만든 후, 중심부 112×112 영역을 자른 다음, 이를 최근접 이웃 보간법으로 224×224로 리사이징했다.
학습은 MSE 손실 함수와 stochastic gradient descent (SGD) 옵티마이저를 warm-up cosine 스케줄러와 함께 사용하였다.
3.3 CNN

CNN은 6개의 컨볼루션 레이어와 3개의 완전 연결층, 출력 뉴런 1개로 구성되었다. 각 구성은 다음과 같다:
- 컨볼루션 필터 수: 32, 64, 128, 256, 512, 1024
- 필터 크기: 6, 5, 3, 3, 2, 2
- 모든 층: ReLU 활성화, stride=1, same padding 사용
- 각 컨볼루션 층 뒤에는: 배치 정규화, 드롭아웃(0.2), 2×2 max pooling
- 완전 연결층: 2048 → 512 → 128 뉴런(ReLU), 드롭아웃(0.1)
- 입력: u, g, r, i 밴드 포함된 4채널, 128×128 이미지
- 출력: 시그모이드 활성화된 단일 뉴런
- 학습: MSE 손실 함수 + Adam 옵티마이저
3.4 Autoencoder

오토인코더는 CNN 인코더 구조를 그대로 사용하되, 출력층 대신 64차원의 잠재 공간(latent space)을 출력하도록 수정하였다. 이 중 1개의 뉴런이 병합 시간을 예측하도록 학습되며, 나머지 63개 뉴런은 이미지 복원을 위한 디코더에 전달된다.
- 인코더 출력: 64 뉴런 (시그모이드)
- 디코더:
- 완전 연결층: 128 → 512 → 2048 → 4096
- 출력: 2×2×1024로 reshape
- 이후 Transposed Conv: 필터 1024 → 512 → 256 → 128 → 64 → 32 (각각 필터 사이즈 2~6)
- 마지막 출력: 1×1 크기의 4채널 필터 (시그모이드)
오토인코더의 목표는 이미지 재생이 아니라 잠재 공간에 병합 시간 정보를 효과적으로 인코딩하는 것이다. 따라서 최종 손실 함수는:
- 입력-재생 이미지 간 MSE + 병합 시간 예측 뉴런의 MSE
을 더한 것이다.
3.5. 잠재 공간 (Latent space)
우리는 오토인코더의 잠재 공간(latent space)이 은하 병합 전후 시간을 예측하는 데 유용한 정보를 포함하고 있는지를 조사하였다.
이를 위해 오토인코더의 64차원 잠재 공간을 2차원으로 차원 축소하는 여러 기법을 사용했다. 이때의 조건은 다음과 같다:
- 새로운 데이터도 동일한 임베딩 공간에 투영할 수 있어야 한다.
- → 즉, 훈련 데이터를 사용하여 차원 축소 맵핑을 생성한 후, 검증 데이터를 동일한 맵핑에 투영할 수 있어야 한다.
사용된 차원 축소 기법은 다음과 같다:
- Isomap (Tenenbaum et al. 2000)
- LDA (Linear Discriminant Analysis)
- Fisher의 선형 판별 분석(Fisher 1936)의 일반화된 형태
- NCA (Neighbourhood Components Analysis) (Goldberger et al. 2004)
- SRP (Sparse Random Projection) (Li et al. 2006)
- TSVD (Truncated Singular Value Decomposition) (Halko et al. 2011)
- UMAP (Uniform Manifold Approximation and Projection) (McInnes et al. 2018)
이 중 대부분은 Scikit-learn 라이브러리를 사용했고, n_components=2로 설정하였다.
UMAP은 umap-learn 구현체를 사용하였으며, 기본 설정을 적용하였다.
병합 시간 예측 방법
검증 데이터의 병합 시간을 추정하기 위해 다음의 방식으로 잠재 공간을 활용하였다:
- 훈련 데이터의 잠재 벡터(64차원)를 2차원으로 임베딩한다.
- 검증 데이터도 동일한 방식으로 2차원에 투영한다.
- 검증 샘플이 임베딩된 점 주변에서 삼각형을 이루는 훈련 샘플 3개를 찾는다.
- 이 세 점의 실제 병합 시간을 Z축으로 하여 3차원 평면을 만든다.
- 검증 샘플의 (x, y) 위치에 해당하는 이 평면상의 z값을 해당 은하의 예측 병합 시간으로 사용한다.
이 작업을 통해 훈련 데이터 기반의 공간적 병합 시간 추정 방법을 구현하였다.
끙
🌌 4. Results
4.1. 신경망


신경망의 손실(loss) 값은 표 1 및 그림 5의 파란색 기호에 정리되어 있다. 결과적으로 CNN 구조가 병합 시간을 예측하는 데 있어 가장 낮은 평균 제곱 오차(MSE)를 기록하며 가장 뛰어난 성능을 보였다.
다만, CNN과 오토인코더의 성능 차이는 미미하다. 두 구조를 다시 학습시킨다면 오토인코더가 CNN보다 더 나은 결과를 보일 수도 있다. 네 가지 구조에 대한 예측 병합 시간과 실제 병합 시간 간의 관계는 그림 6에 정리되어 있다.

또한, 우리는 예측 오차(실제 병합 시간과 예측 시간의 절대 차이)의 평균 및 중앙값이 실제 병합 시간의 구간에 따라 어떻게 달라지는지도 분석했다 (그림 7 참조). 실제 병합 시간을 정규화한 값을 기준으로 0.1 간격의 구간으로 나눈 후, 각 구간에서의 평균 및 중앙 오차를 계산했다.

- ResNet50의 평균 및 중앙 오차는 정규화된 시간 ≈0.5에서 최소값을 갖고, 양끝(0 및 1)에서는 커진다. 이는 ResNet50이 대부분의 값을 0.5 근처로만 예측하는 경향을 보이기 때문이다.
- Swin, CNN, 오토인코더는 모두 병합 이벤트에 가까운 시간(0.3 근처)에서는 예측 정확도가 높고, 병합 시간에서 멀어질수록(정규화 시간 <0.25 또는 >0.75) 오차가 커지는 경향을 보였다.
4.2. 잠재 공간
LDA로 임베딩된 잠재 공간은 그림 8에, 그 외 Isomap, NCA, SRP, TSVD, UMAP 임베딩은 부록 A에 제시되어 있다. 각 기법에 대해 훈련 데이터(그림 8a)와 검증 데이터(그림 8b)의 결과를 시각화하였다.

검증 데이터의 병합 시간 역시 훈련 데이터의 병합 시간과 유사한 분포를 보인다. 이는 잠재 공간의 분포가 일정 수준의 시간 정보를 유지하고 있음을 의미한다.


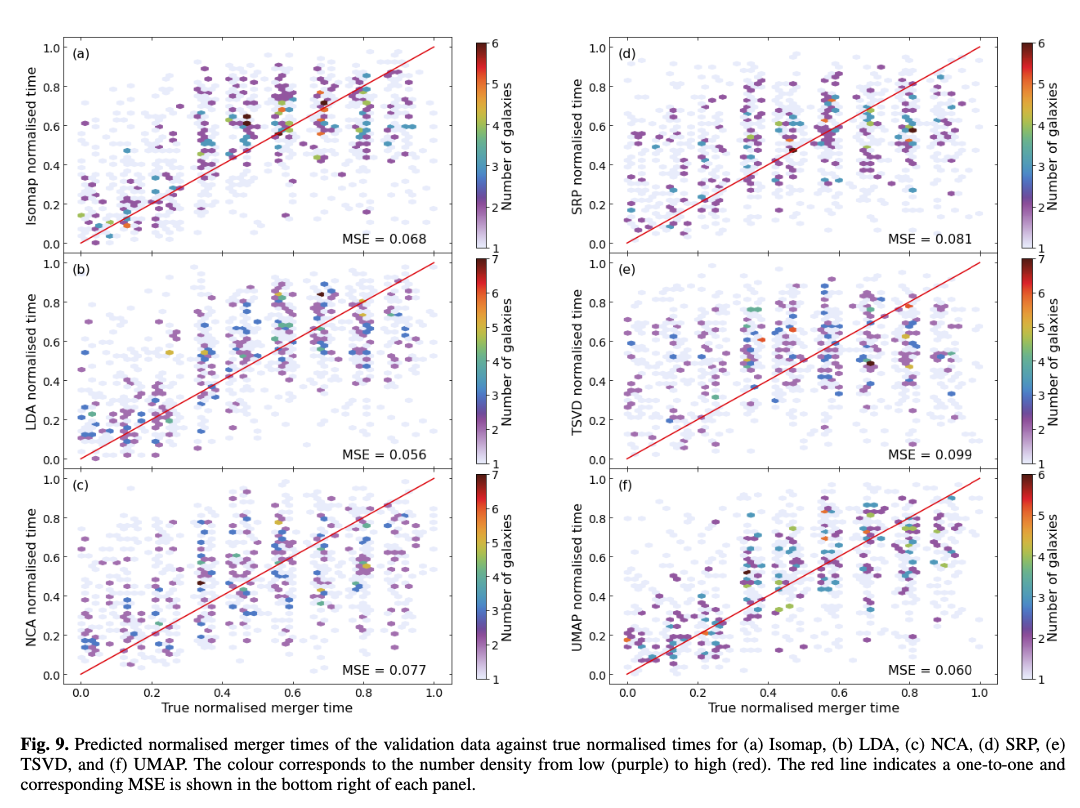
이 임베딩 공간에서 검증 데이터의 병합 시간을 예측한 결과는 표 2와 그림 5의 빨간 기호, 그리고 그림 9에 나타나 있다. 전체적으로:
- 잠재 공간 기반 추정은 오토인코더보다 성능이 낮다.
- LDA와 UMAP이 그나마 ResNet50보다 좋은 성능을 보였다.
그림 10에서는 각 임베딩 기법의 병합 시간 예측 오차가 실제 병합 시간 구간에 따라 어떻게 달라지는지 보여준다. 다음과 같은 경향이 나타난다:
- Isomap, LDA, UMAP: 평균 오차가 0.25에서 감소, 0.35에서 증가, 0.65에서 다시 감소, 1.0에서 재차 증가
- NCA, SRP, TSVD: 평균 및 중앙 오차가 정규화 시간 0.55까지 감소 후 증가
- → 이 세 가지는 성능이 떨어지는 기법군에 속함.
추가적으로, LDA의 x-축 임베딩이 병합 시간과 강한 상관관계를 보였기 때문에, 우리는 LDA의 x값을 선형 회귀로 병합 시간에 매핑하였다. 그 결과:
- 훈련 MSE: 0.032
- 검증 MSE: 0.039
- → 이는 오토인코더와 매우 유사한 성능이며, 그림 11에 시각화되어 있다.
4.3. 테스트 데이터
CNN이 가장 우수한 구조로 확인되었기 때문에, 이를 테스트 데이터에 적용하였다. 결과:
- MSE: 0.051
- 평균 오차: 253 Myr
- 중앙 오차: 190 Myr
- → 그림 12에 예측 병합 시간과 실제 병합 시간 간 관계를 나타냄.

그림 13은 테스트 데이터에서의 평균 및 중앙 예측 오차를 실제 병합 시간 구간별로 보여준다. 결과는 다음과 같다:

- 정규화 시간 0.25~0.55 구간에서는 검증 데이터와 유사한 오차 분포를 보인다.
- 그 외 구간에서는 평균 오차가 커지는 경향이 있다.
우리는 정규화 병합 시간이 0.33보다 크면 pre-merger, 작으면 post-merger로 간주했다. 이 기준에 따르면:
- 전체 정확도: 81 ± 1%
- bootstrapping을 통해 신뢰 구간 측정함.
🌌 5. Discussion
5.1. 신경망
ResNet50은 실험된 모든 구조 중 가장 낮은 성능을 보였고, 예측값이 대부분 0.5 근처로 수렴했다. 이는 과적합 때문이 아니라, 훈련 데이터에서도 동일한 문제가 발생했기 때문이다. 이는 놀라운 결과인데, 과거 ResNet50이 병합 시간 예측에 성공한 사례(Koppula et al. 2021)가 있었기 때문이다. 그러나 그 연구에서는 20만 장 이상의 병합 은하 이미지를 사용했으며, 본 연구에서는 약 1만 장의 이미지만 사용했다는 차이점이 있다. 또한 그들은 Horizon-AGN 시뮬레이션 데이터를 사용했지만, 이것이 성능 차이를 유발했을 가능성은 낮다. Koppula et al. (2021)은 은하의 질량과 적색편이도 입력 특성에 포함시켰기 때문에 성능 향상에 기여했을 수도 있다.
Swin Transformer는 병합 은하를 식별하고 병합 전후 시점을 구분하는 데 효과적인 것으로 알려져 있으며, 기존 CNN보다 나은 성능을 보인다는 연구도 있다 (Margalef-Bentabol et al. 2024). 하지만 본 연구에서는 CNN보다 약간 낮은 성능을 보였다. 이 원인은 Swin이 학습할 때 이용할 수 있는 밴드 수가 적었기 때문일 수 있다. 사전 학습된 Swin은 3채널 입력만 받을 수 있어 u, g, r 밴드만 사용했고, CNN은 모든 4개 밴드(u, g, r, i)를 사용할 수 있었다. 이 네 번째 밴드(i)가 병합 시간과 관련된 추가 정보를 제공했을 가능성이 있다.
CNN과 오토인코더는 유사한 MSE를 보였다. 오토인코더의 인코더 구조는 CNN과 동일하다. 오토인코더는 이미지 복원이라는 부가적인 학습 목표를 통해 더 풍부한 표현을 학습하게 유도했지만, 병합 시간 예측 성능 향상에는 큰 기여를 하지 못했다. 즉, CNN만으로도 이미지에서 추출 가능한 정보를 대부분 활용하고 있다는 것을 의미한다.
또한 CNN 구조를 개발하는 과정에서, 컨볼루션 층을 늘릴수록 성능이 향상되는 것을 확인했다. 현재 구조는 각 컨볼루션 뒤에 pooling이 존재하기 때문에, 더 많은 층을 추가하면 이미지 크기가 2픽셀 이하로 줄어들어버린다. 모든 층에 pooling을 적용하지 않는 구조로 변경하면 더 깊은 CNN을 설계할 수 있으며 성능이 향상될 여지가 있다.

그림 14에서 확인할 수 있듯, CNN을 포함한 모든 네트워크는 병합 시간 예측에서 투영 거리(projected separation)와의 상관관계를 보여주지 않는다. 이는 네트워크가 은하 간 거리보다는 형태적 교란(morphological disturbances)을 기반으로 병합 시간을 추론하고 있음을 시사한다.
5.1.1. 병합 시간에 따른 예측 오차의 형태
ResNet50에서 나타난 ‘U’자형 평균 및 중앙 오차 곡선은 모든 예측값이 0.5 부근에 몰려 있는 것에서 기인한다. 즉, 병합 시간과 무관한 출력을 낸다는 의미다.
Swin, CNN, 오토인코더는 병합 시점과 거리가 멀어질수록(정규화 시간 <0.25 또는 >0.75) 예측이 어렵다는 동일한 경향을 보였다.
- post-merger (병합 이후): 병합이 일어난 지 125 Myr 이상 지나면 은하가 안정되면서 병합의 흔적이 사라지기 때문에 예측이 어렵다.
- pre-merger (병합 이전): 병합까지 625 Myr 이상 남아있는 은하는 상호작용이 미약해지므로 예측이 어렵다.
- → 따라서 신경망이 예측에 실패하는 시간대는 물리적으로 병합 특징이 희미해지는 시점과 일치한다.
다만, 매우 이른 pre-merger와 매우 늦은 post-merger가 서로 헷갈려 예측되는 경우는 거의 없다. 즉, 양 극단 간 혼동은 거의 없고, 예측 실패는 해당 시점 주변에서 오차가 발생하는 정도에 그친다 (그림 6 참조).
5.1.2. Occlusion 실험
모델이 병합 시간 예측에 어떤 이미지를 참고하는지를 알아보기 위해 occlusion 실험(가림 실험)을 수행하였다:
- 이미지의 8×8 픽셀 정사각형을 좌상단부터 시작해 1픽셀씩 이동시키며 총 14,641개의 가려진 이미지를 생성했다.
- 각 이미지를 네트워크에 넣어 예측값을 얻고, 해당 픽셀이 가려졌을 때 병합 시간 예측값의 평균을 계산하여 히트맵을 생성했다.
실험 대상은:
- Swin, CNN, 오토인코더에서 예측 오차가 낮은 pre-merger 3개, post-merger 2개 은하
- ResNet50은 분석 제외 (출력이 대부분 0.5이기 때문)
결과 분석:
- ResNet50: 모든 히트맵의 예측값이 좁은 범위(0.06 내외)에 몰려있다. 이는 모델이 이미지를 제대로 학습하지 못했음을 의미한다.
- Swin: 주변 은하나 희미한 구조를 가릴 경우 예측값이 유의하게 변화했다. 이는 모델이 형태 교란에 의존하고 있음을 보여준다.
- CNN: 가장 정확한 예측을 했고, 이미지 중심이나 동반 은하를 가리면 예측값이 민감하게 변화했다.
- Autoencoder: Swin 및 CNN과 유사하게 동반 은하나 중심부, 희미한 구조가 중요하지만, 때때로 배경 노이즈도 민감하게 반응하는 경향이 있었다.
이 실험은 네트워크가 은하 간 거리보다는 은하 구조(중심, 꼬리, companion 등)의 왜곡을 바탕으로 병합 시간을 판단하고 있음을 시사한다.
5.3. 테스트 데이터
CNN이 모든 구조 중 가장 성능이 우수하므로, 우리는 이 모델을 테스트 데이터에 적용하였다 (그림 12 참조). 그 결과는 다음과 같다:
- 평균 제곱 오차 (MSE): 0.051
- 평균 오차: 253 Myr
- 중앙값 오차: 190 Myr
이는 CNN이 병합 시간을 약 1개의 시뮬레이션 스냅샷 정도의 정확도로 예측할 수 있다는 것을 의미한다. 참고로, IllustrisTNG에서 사용된 스냅샷 간 평균 시간 간격은 162 Myr이며, 최대 간격은 194 Myr이다.
이로부터 얻을 수 있는 시사점:
- 단순 중력 시뮬레이션을 통해 병합 시간을 더 세분화하는 시도는
- → CNN의 예측 정확도 관점에서는 그다지 큰 이득을 주지 않았을 가능성이 있다.
- 중력 시뮬레이션 과정에서 전체 병합 샘플의 약 절반(2818개)이 제외되었는데,
- → 더 많은 학습 샘플 확보가 시간 정밀도 향상보다 더 큰 효과를 줄 수도 있다.
- 그러나 CNN으로 중력 시뮬레이션 없이 병합 시간 추정한 실험에서는 큰 성능 향상이 나타나지 않았다.
검증 데이터와의 비교:
테스트 데이터의 평균 및 중앙 오차 곡선은 검증 데이터와 유사한 패턴을 보이며, 일부 시간 구간에서는 약간 더 큰 오차를 보였다 (그림 13). 이는 다음과 같은 점을 확인시켜 준다:
- 병합과 가장 거리가 먼 시점
- 병합 후 125 Myr 이상 경과하거나
- 병합까지 625 Myr 이상 남은 은하
- → 예측 성능이 가장 낮다.
하지만 이러한 은하들이 완전히 반대 방향으로 혼동되는 경우는 거의 없으며, 이는 검증 세트에서도 동일하게 관찰되었다 (그림 6 참조).
기존 연구와 비교:
Koppula et al. (2021)은 병합 시간 예측에서 중앙 오차 69.35 Myr를 기록했는데, 이는 본 연구보다 성능이 좋다. 하지만 여러 차이가 존재한다:
- Koppula는 약 20만 개의 병합 은하 이미지 사용 (본 연구는 약 1만 개)
- 병합 시간 범위: -400 ~ +400 Myr (본 연구는 -500 ~ +1000 Myr)
- 공간 해상도: 0.06 arcsec/pixel (본 연구는 0.20 arcsec/pixel)
- 시간 해상도: Koppula는 약 17 Myr, 본 연구는 약 162 Myr
하지만 스냅샷 기준 정확도로 비교하면:
- Koppula: 약 4.0 스냅샷 오차
- 본 연구(CNN): 약 1.2 스냅샷 오차
따라서 시간 분해능 차이를 고려하면 본 연구의 상대 성능은 우수하다.
또한, Koppula 역시 병합까지 오래 남은 pre-merger 은하의 예측 정확도가 낮았음을 보고하였다.
Pre- / Post-merger 분류 정확도:
- 본 연구에서 설정한 기준:
- 정규화 병합 시간 > 0.33 → pre-merger
- ≤ 0.33 → post-merger
- CNN 예측에 기반한 분류 정확도:
- 전체 정확도: 81 ± 1%
- pre-merger 정확도: 90 ± 1%
- post-merger 정확도: 65 ± 3%
→ Post-merger의 시간 범위가 더 좁고, 수가 적으며, 시각적 특징이 희미해 예측 정확도가 낮은 것은 합리적 결과다.
🌌 6. Conclusion
본 연구에서는 은하 병합 전후 시간(merger time)을 예측하는 다양한 신경망 아키텍처의 성능을 비교하고 분석하였다.
주요 결론은 다음과 같다:
- CNN 구조가 가장 높은 병합 시간 예측 정확도를 보였으며,
- 중앙 예측 오차는 약 190 Myr로, 이는 TNG100 시뮬레이션의 스냅샷 간 평균 시간 간격(약 162 Myr)보다 약간 높은 수준이다.
- 병합 시간의 오차는 병합 시점에 가까울수록 낮고, 병합에서 시간적으로 멀어질수록 오차가 커지는 경향이 나타났다.
- 즉, 병합 전 625 Myr 이상이 남은 pre-merger 은하와
- 병합 후 125 Myr 이상이 지난 post-merger 은하에서는
- → 병합 시간 예측이 가장 어렵다.
- 이 시점들의 은하는 형태적 교란이 희미하거나 사라졌기 때문에,
- 네트워크가 병합 시간 단서를 인식하기 어렵다.
ResNet50은 과거 연구에서 유망한 결과를 보여줬지만,
본 연구에서는 대부분의 예측값이 0.5에 몰리는 등 학습 실패에 가까운 결과를 보였다.
Swin Transformer는 CNN보다는 다소 낮은 성능을 보였으며,
이는 입력 밴드 수의 제한(3채널)으로 인해 발생했을 가능성이 있다.
오토인코더는 CNN과 거의 동등한 병합 시간 예측 성능을 보였으며,
잠재 공간(latent space)은 병합 시간뿐 아니라 다양한 은하 특성 정보를 함께 포함하고 있음을 시사한다.
다양한 차원 축소 기법을 활용하여 오토인코더의 잠재 공간을 분석한 결과,
LDA 기반의 선형 회귀 모델이 가장 뛰어난 성능을 보였으며, 이는 오토인코더 내 단일 뉴런 예측 성능과 유사하였다.
본 연구는 병합 시간 예측의 정확도 측면에서 이전보다 진보한 결과를 제시하였으며,
이를 통해 은하 병합의 다양한 단계에서 물리적 변화(별 형성률, AGN 활동 등)를 더 정밀하게 추적할 수 있는 기반을 마련하였다.
향후 연구 방향은 다음과 같다:
- 병합 시간의 불확실성 추정
→ 단일값 예측이 아니라, 예측 신뢰도까지 함께 제공하는 모델이 필요하다. - 은하의 물리량(별 형성률, 질량 등)을 함께 입력 특성으로 추가
→ 더 높은 예측 정확도 가능 - 시계열 이미지 학습 또는 시뮬레이션 스냅샷 연속 활용
→ 병합 과정의 동적인 정보를 직접 반영
꺄악...우리랑 같은 거 하고 계시겟는데 pearson님
https://www.notion.so/AI-1bc10ccd4eb580678448ffae75687927?p=1fc10ccd4eb58038ba23d204680c47d5&pm=s
'Club|Project > 졸업 연구 | 멀티모달 AI를 이용한 은하 병합 단계 분류' 카테고리의 다른 글
| 🏆 이그 - SDSS 데이터 다운,전처리 (0) | 2025.05.22 |
|---|---|
| 🌌 SpaceAI 천문연구원 킥오프 미팅 (1) | 2025.05.20 |
| 🏆 SYENERGI 이그노벨상용 사이드프로젝트 (0) | 2025.05.20 |
| 🌌 충돌 은하 분류 연구 : 지웅배 교수님 진행 계획 정리 (0) | 2025.05.20 |
| 🌌 [Identifying galaxy mergers in observations and simulations with deep learning] 논문 공부 (0) | 2025.05.15 |


