
✨ TODO
헬스케어 데이터 수집 방법 결정 및 데이터셋 확보 ✅
데이터 전처리 및 정제 과정 설계 및 구현
데이터 분석을 위한 주요 지표 및 메트릭 선정
데이터 시각화 도구 선택 및 시각화 계획 수립
✨ TOPIC
🙏 이전 내용은 데이터 분석 미션과 적합하지 않은 부분이 있는 것 같아 주제 선회 결정하였습니다ㅠ 🙏
새로 결정된 주제
개인의 칼로리 섭취, 칼로리 소모 , 기타 요인에 따른 체중 변화 예상 모델
기타요인 : 데이터를 더 찾고 정제하는 과정에서 확실해질 듯
- 개인이 자신의 데이터 입력
- 칼로리 섭취, 칼로리 소모 , 기타 요인 등등을 전체 데이터와 비교한 개인 데이터를 그래프로 보여줌
- 모델을 통해 나온 점수(예상 소모 칼로리양? 등) 을 보여줌
✨ DATA
- 일일 칼로리 섭취량과 운동 정보에 따른 체중 변화
- 다른 사람이 상기 데이터를 분석한 코드 (R언어)
- My weight loss regression dataset and analysis
- 2018 calorie, exercise and weight changes
- 운동 유형에 따른 칼로리 소모량
- 다른 사람이 상기 데이터를 분석한 코드 (Python)
- Getting Started with the Calories Burned Dataset
- 다양한 식품의 영양소 구성
- 식품영양성분 데이터베이스
- food nutrition dataset
- 개인의 일일 물 섭취량CDP: external data source water supply
- Water Consumption
- 물 섭취량에 대한 데이터 보완 및 분석
✨ DATA Analysis
식품영양성분표 + 운동유형칼로리소모표 + 개인의 섭취/운동량에 따른 체중 변화 데이터 + 개인의 물 섭취 데이터
https://various.foodsafetykorea.go.kr/nutrient/general/down/historyList.do
https://www.kaggle.com/datasets/aadhavvignesh/calories-burned-during-exercise-and-activities
https://www.kaggle.com/datasets/chrisbow/2018-calorie-exercise-and-weight-changes
https://www.kaggle.com/datasets/marcomolina/water-consumption-in-a-median-size-city
💛식품영양성분표
식품,가공식품
각종 영양 성분 표시
💛운동유형칼로리소모표
사람이 어떤 활동이나 운동을 할 때 소모하는 칼로리 수가 포함
러닝, 사이클링, 칼리스테닉스 등 248가지 활동과 운동을 포함
💛개인의 섭취/운동량에 따른 체중 변화 데이터
대략적인 칼로리 섭취량과 먹은 것, 운동한 것
칼로리와 운동이 체중 변화에 미치는 영향
회귀 분석을 위한 데이터셋
💛개인의 물 섭취 데이터
2009년부터 2016년까지의 사용자별 물 소비량(입방미터), 토지 이용, 사용자 유형(예: 산업, 주거, 공공 인프라 등), 우편번호 등을 포함
전체 데이터셋의 왜곡을 일으키지 않으면서 결측값(NA)을 처리하는 것이 도전 과제
결측값이 있는지 확인
있다면 이를 채울 수 있는지, 그리고 왜 결측값이 발생했는지 이해
- 가상환경 생성
python3 -m venv myenv
- 가상환경 활성화
source myenv/bin/activate
✨ DATA Analysis : water
Perception of Price when Information is Costly
Explore and run machine learning code with Kaggle Notebooks | Using data from Water Consumption in a Median Size City
www.kaggle.com
데이터 구조 :
중간 규모 도시에서의 물 소비와 관련된 다양한 정보
- USO2013: 아마도 사용자 유형 또는 물 사용 범주를 나타내는 코드
- TU: 사용자 유형을 더 구체적으로 설명
- DC: 다 0.5인 무언가,.
- M: 측정 장치의 모델인 것 같다
- UL: 우편번호 예상
- 그 이후는 월별 물 소비 데이터
아하... 정확히 이해했다
우리의 과제와는 하등 상관없는 데이터다
✨ DATA Analysis : diet
칼로리와 운동이 체중 변화에 미치는 영향
- Date: 날짜.
- Stone, Pounds, Ounces: 체중의 다른 단위
- weight_oz: 체중을 온스로 환산한 값
- calories: 그 날 섭취한 칼로리
- cals_per_oz: 온스당 칼로리
- five_donuts: 도넛 5개를 먹었는지 여부 ..?
- walk: 걷기 운동을 했는지 여부
- run: 달리기 운동을 했는지 여부
- wine: 와인을 마셨는지 여부
- prot: 단백질 섭취 여부
- weight: 체중 변화를 나타내는 변수
- change: 전날 대비 체중의 변화량(온스 단위)
분석 :
- 기초 통계 분석: 각 변수의 평균, 표준편차, 최소/최대 값을 살펴보고 데이터의 전반적인 경향을 이해하기
- 시간에 따른 체중 변화 분석: 날짜별로 체중 변화를 시각화하여 체중 감소 또는 증가 추세를 파악하기
- 상관 분석: 칼로리 섭취량, 운동 유무 등이 체중 변화에 어떤 상관관계를 보이는지 분석하기
- 회귀 분석: 칼로리 섭취량, 운동 여부, 기타 생활 습관이 체중 변화에 어떻게 영향을 미치는지 모델링하여 정량적인 해석을 시도하기
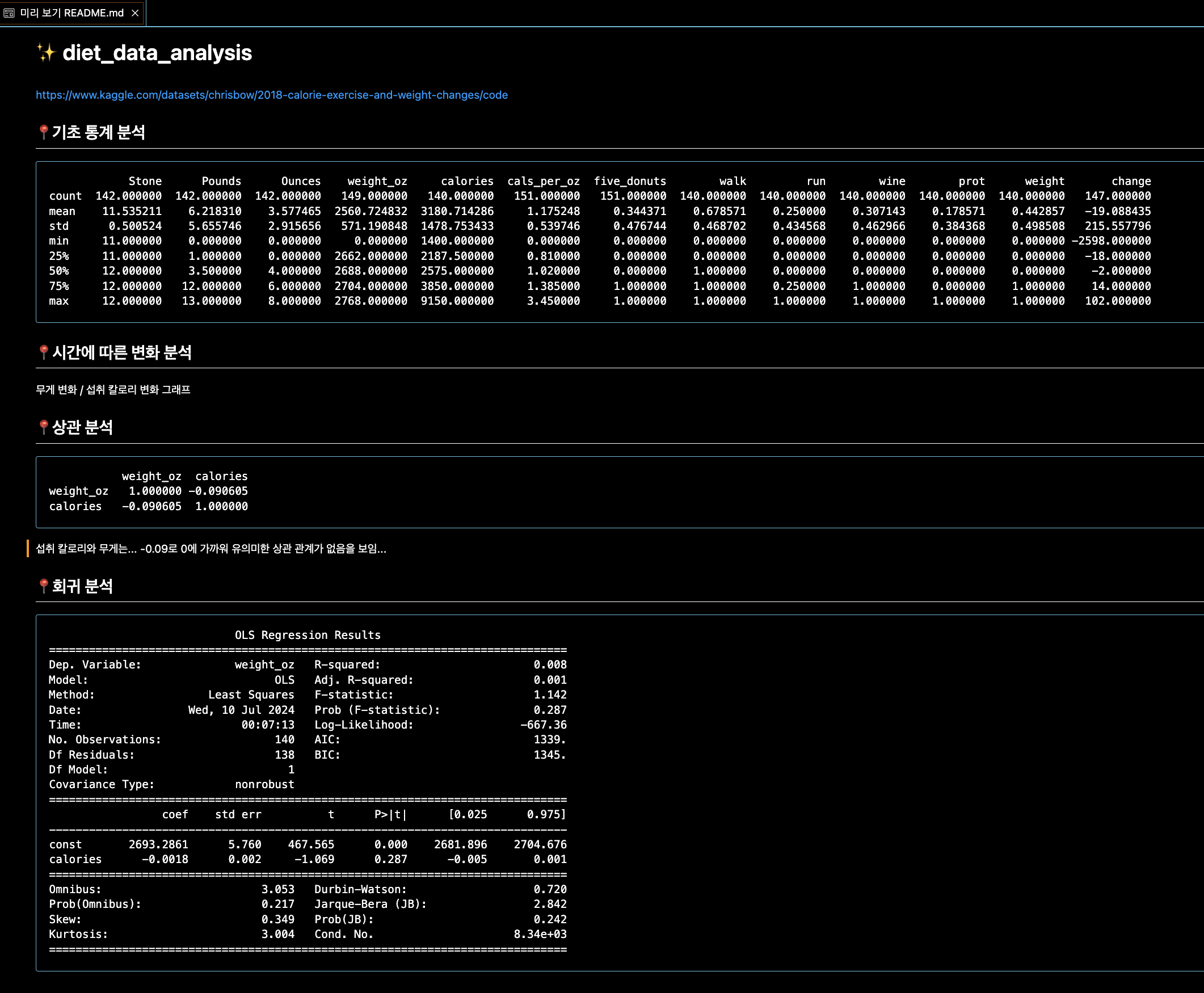
📍기초 통계 분석
pandas 라이브러리의 describe() 메서드
: 각 수치형 변수에 대해 평균, 표준편차, 최소값, 25%, 50%, 75%, 최대값
Stone Pounds Ounces weight_oz calories cals_per_oz five_donuts walk run wine prot weight change
count 142.000000 142.000000 142.000000 149.000000 140.000000 151.000000 151.000000 140.000000 140.000000 140.000000 140.000000 140.000000 147.000000
mean 11.535211 6.218310 3.577465 2560.724832 3180.714286 1.175248 0.344371 0.678571 0.250000 0.307143 0.178571 0.442857 -19.088435
std 0.500524 5.655746 2.915656 571.190848 1478.753433 0.539746 0.476744 0.468702 0.434568 0.462966 0.384368 0.498508 215.557796
min 11.000000 0.000000 0.000000 0.000000 1400.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 -2598.000000
25% 11.000000 1.000000 0.000000 2662.000000 2187.500000 0.810000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 -18.000000
50% 12.000000 3.500000 4.000000 2688.000000 2575.000000 1.020000 0.000000 1.000000 0.000000 0.000000 0.000000 0.000000 -2.000000
75% 12.000000 12.000000 6.000000 2704.000000 3850.000000 1.385000 1.000000 1.000000 0.250000 1.000000 0.000000 1.000000 14.000000
max 12.000000 13.000000 8.000000 2768.000000 9150.000000 3.450000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 102.000000
+ 결측값 처리
cals_per_oz의 object값 정수형으로
채워져 있지 않은 값은 평균값과 0으로
📍시간에 따른 변화 분석
Pandas와 Matplotlib 라이브러리
- 날짜 데이터를 Pandas의 DateTime 형식으로 변환
- 체중 데이터 'weight_oz' /사용
- Matplotlib 라이브러리를 사용하여 날짜에 따른 체중 변화를 선 그래프로 표현
에- 0 빼야
0인 값은 뺀 필터링된 데이타로
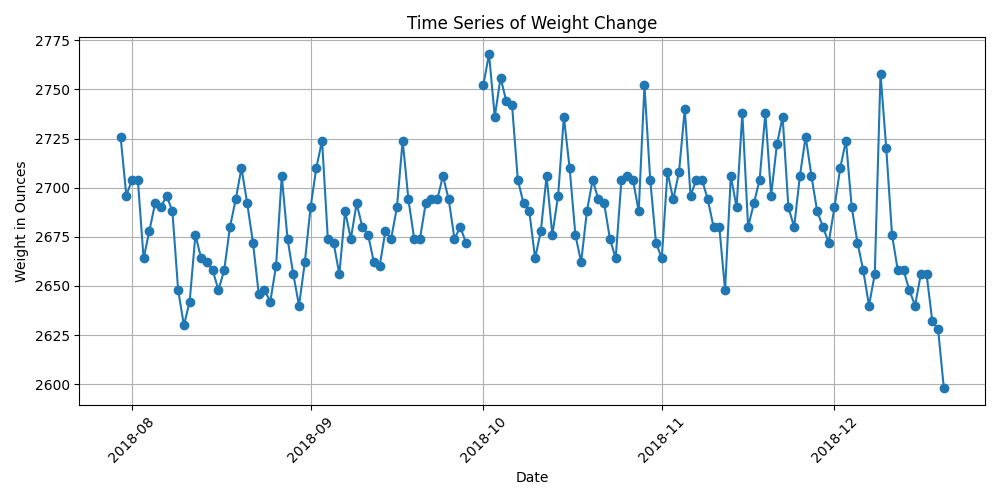
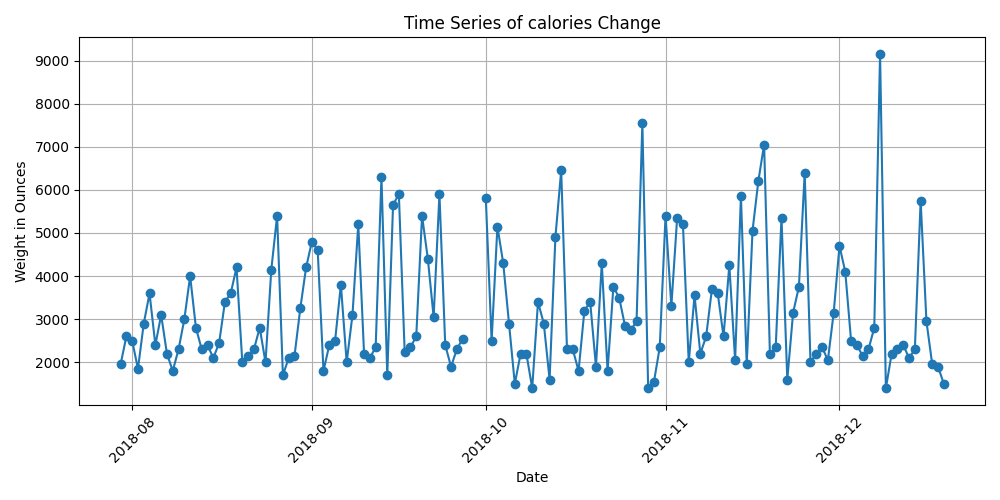
볼만한
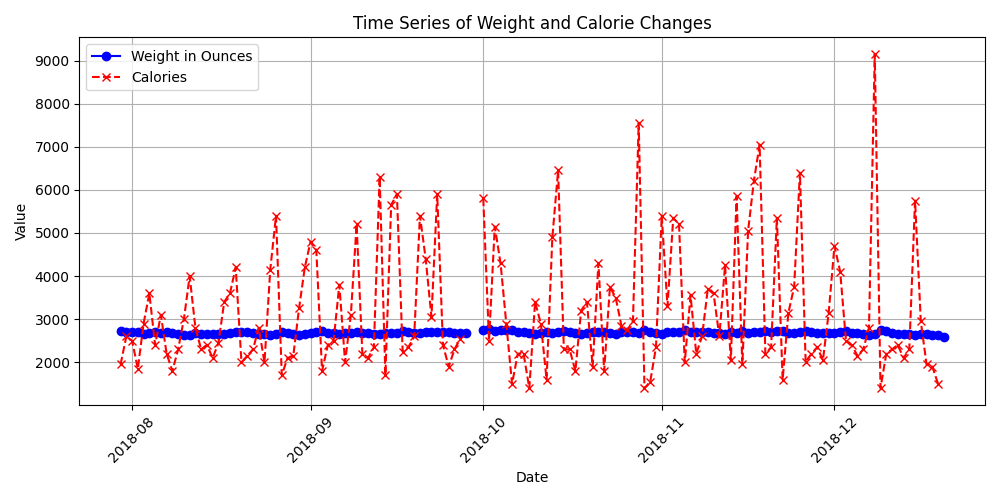
겹쳤더니...
y값 양쪽에 다르게 표시해서 좀 해봐야 할 듯..
📍상관 분석
두 변수 간의 관계의 강도와 방향을 측정
변수들 사이에 어떤 상관 관계가 있는지, 그리고 그 상관 관계가 얼마나 강한지를 파악
- 상관 계수: 이는 -1에서 +1 사이의 값으로 표현되며, +1은 완벽한 양의 선형 관계, -1은 완벽한 음의 선형 관계, 0은 선형 관계가 전혀 없음을 의미
- 피어슨 상관 계수 (Pearson Correlation Coefficient): 연속적이고 정규 분포를 따르는 변수에 주로 사용
- 스피어만 순위 상관 계수 (Spearman's Rank Correlation Coefficient): 정규 분포를 따르지 않거나, 순위나 등급과 같은 서열 척도로 측정된 변수에 사용
weight_oz calories
weight_oz 1.000000 -0.090605
calories -0.090605 1.000000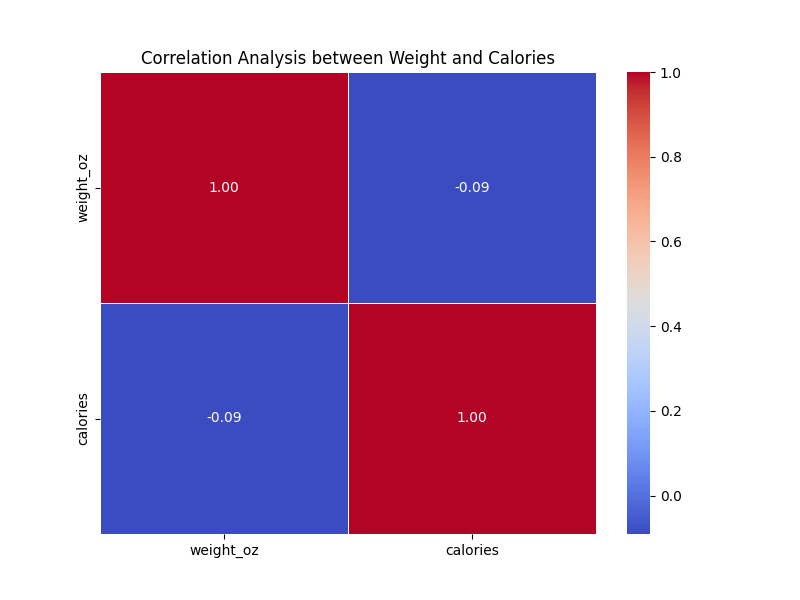
섭취 칼로리와 무게는...
-0.09로 0에 가까워 유의미한 상관 관계가 없음을 보임...
?
📍회귀 분석
변수들 간의 관계를 모델링하여 한 변수의 변화가 다른 하나 이상의 변수에 어떤 영향을 미치는지를 분석
회귀 분석의 주된 목적은 예측과 인과 관계의 추정
- 단순 선형 회귀 (Simple Linear Regression): 하나의 독립 변수와 하나의 종속 변수 사이의 선형 관계를 모델링
- 다중 선형 회귀 (Multiple Linear Regression): 두 개 이상의 독립 변수와 하나의 종속 변수 사이의 관계를 모델링
회귀 모델 구축 및 적합: statsmodels의 OLS 클래스를 사용하여 최소제곱회귀모델을 구축하고 데이터에 적합
결과 출력: summary() 메소드를 통해 회귀 분석 결과를 출력 이 결과에는 회귀 계수, R-squared (결정 계수), p-value, 표준 오차 등이 포함
OLS Regression Results
==============================================================================
Dep. Variable: weight_oz R-squared: 0.008
Model: OLS Adj. R-squared: 0.001
Method: Least Squares F-statistic: 1.142
Date: Wed, 10 Jul 2024 Prob (F-statistic): 0.287
Time: 00:07:13 Log-Likelihood: -667.36
No. Observations: 140 AIC: 1339.
Df Residuals: 138 BIC: 1345.
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 2693.2861 5.760 467.565 0.000 2681.896 2704.676
calories -0.0018 0.002 -1.069 0.287 -0.005 0.001
==============================================================================
Omnibus: 3.053 Durbin-Watson: 0.720
Prob(Omnibus): 0.217 Jarque-Bera (JB): 2.842
Skew: 0.349 Prob(JB): 0.242
Kurtosis: 3.004 Cond. No. 8.34e+03
==============================================================================
- 모델 개요
- Dep. Variable: 종속 변수, 여기서는 weight_oz
- Model: 모델 종류, 여기서는 OLS(최소제곱법)
- Method: 사용된 방법, 여기서는 최소제곱법(Least Squares)
- No. Observations: 관측치 수, 여기서는 140개
- 모델 적합도
- R-squared: 0.008
- 결정 계수로, 모델이 종속 변수의 변동성을 얼마나 설명하는지를 나타냄
- 0.008은 모델이 체중 변동성의 0.8%만을 설명한다는 것을 의미 / 매우 낮은 값
- Adj. R-squared: 0.001
- 조정된 결정 계수로, 모델의 설명력을 설명 변수의 수에 대해 조정한 값/ 매우 낮은 값
- F-statistic: 1.142
- 모델의 전체 유의성을 평가
- Prob (F-statistic): 0.287
- F-통계량의 p-value입니다. p-value가 0.05보다 크므로, 이 모델은 통계적으로 유의하지 않음
- R-squared: 0.008
- 회귀 계수 (Coefficients)
- const (절편): 2693.2861
- 절편 값으로, 칼로리 섭취량이 0일 때 체중이 2693.2861 온스라는 것을 의미
- calories (칼로리): -0.0018
- 칼로리 섭취량의 계수로, 칼로리 섭취량이 1 증가할 때 체중이 0.0018 온스 감소한다는 것을 의미
- 계수는 음수이지만 그 값은 매우 작음
- std err: 표준 오차로 계수의 추정 불확실성을 나타냄
- t: t-통계량으로 계수가 0과 다른지를 평가
- P>|t|: 각 계수의 p-value로, 계수가 0과 통계적으로 유의하게 다른지를 평가 여기서 p-value가 0.05보다 크므로, 칼로리 섭취량의 계수는 통계적으로 유의하지 않음
- [0.025, 0.975]: 95% 신뢰 구간으로, 계수의 추정치가 이 범위 내에 있을 확률이 95%라는 것을 의미
- const (절편): 2693.2861
- 기타 통계량
- Omnibus: 오차의 정규성을 검정하는 통계량
- Prob(Omnibus): Omnibus 검정의 p-value로, 정규성을 따르는지 여부를 평가
- Durbin-Watson: 잔차의 자기상관성을 평가하는 통계량입니다. 2에 가까울수록 자기상관이 없음을 의미
- Jarque-Bera (JB): 오차의 정규성을 검정하는 또 다른 통계량
- Skew: 오차의 왜도를 나타냄
- Kurtosis: 오차의 첨도를 나타냄
- Cond. No.: 독립 변수의 다중공선성을 나타내는 조건수, 높은 값은 다중공선성 문제가 있음을 나타낼 수 있음
..어려움
✨ DATA Analysis : food
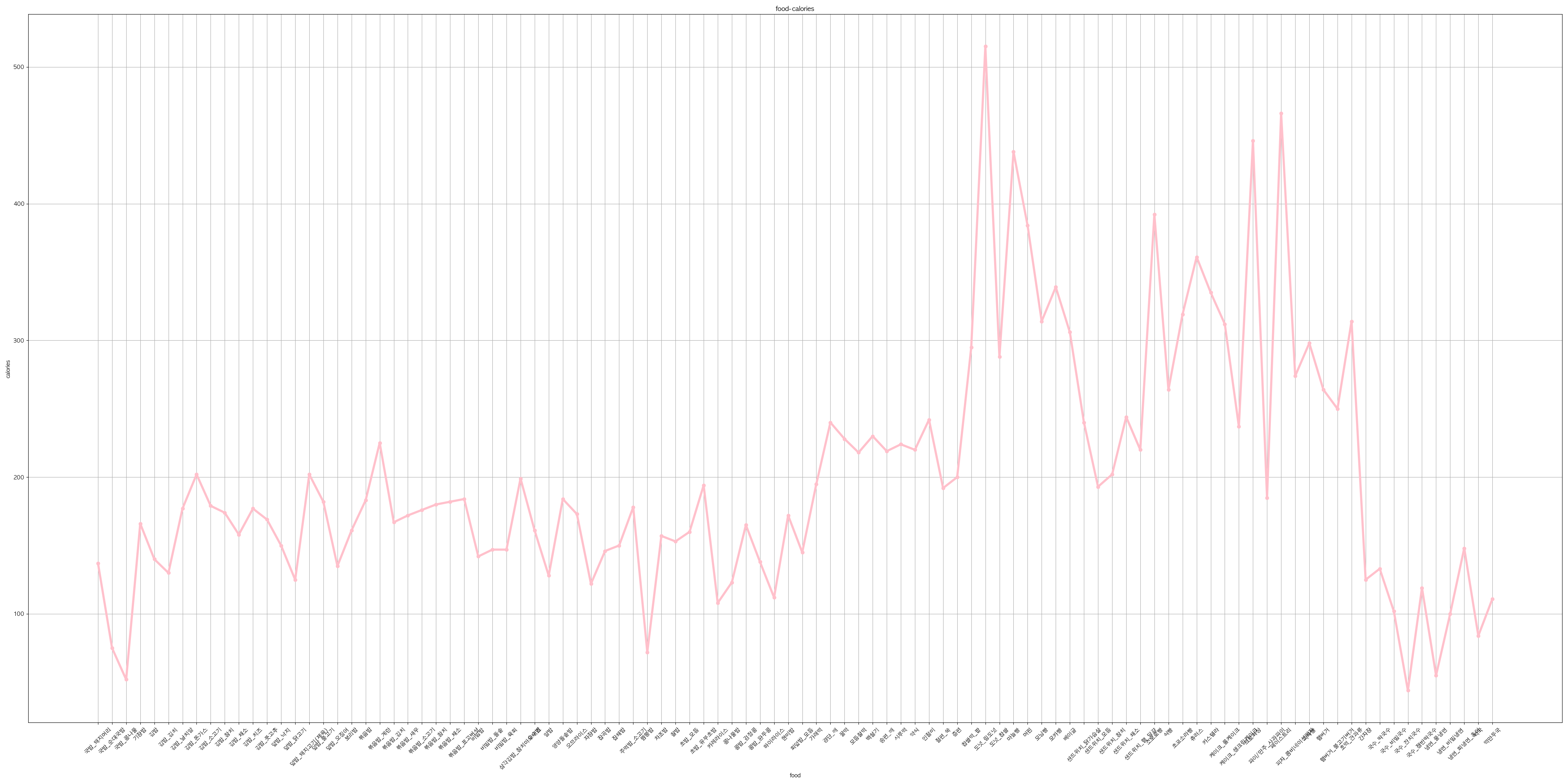
음식별 칼로리량을 그래프로 나타내봄
# 한글 폰트 설정
plt.rcParams['font.family'] = 'AppleGothic' # macOS의 경우 'AppleGothic', Windows의 경우 'Malgun Gothic'
# 데이터 로드
exercise_data = pd.read_excel('./food_data.xlsx') #pd.read_excel xlsx 문서 읽기, pip install openpyxl 필요
# 데이터의 처음 100개의 행만 선택
subset_data = exercise_data.head(100)✨ DATA Analysis : exercise
운동별 소모 칼로리량을 그래프로 나타내봄
깃허브 푸시
협업규칙에 맞춰서
풀리퀘날렸다
'Club|Project > 카카오테크 부트캠프 | AI' 카테고리의 다른 글
| 🍋카카오 부트캠프🍋 7회차 실습 : 데이터 시각화 실습 (0) | 2024.07.10 |
|---|---|
| 💛카카오 부트캠프💛 6회차 (0) | 2024.07.10 |
| 💛카카오 부트캠프💛 5회차 (0) | 2024.07.09 |
| 🍋카카오 부트캠프🍋 5회차 실습 : 데이터 분석 실습 (0) | 2024.07.09 |
| 💛카카오 부트캠프💛 4회차 (0) | 2024.07.08 |



