Abstract
우리는 SegFormer라는 간단하고 효율적이면서도 강력한 의미론적 분할 프레임워크를 제안한다. 이 프레임워크는 Transformer 기반 인코더와 경량 MLP 디코더를 통합한 구조다. SegFormer는 다음과 같은 두 가지 주요 특징을 가진다:
- SegFormer는 계층적 구조의 Transformer 인코더를 도입하여 멀티스케일 피처를 출력한다. 이 인코더는 포지셔널 인코딩을 필요로 하지 않기 때문에, 테스트 시 해상도가 학습 시와 다를 경우 발생할 수 있는 성능 저하를 피할 수 있다.
- SegFormer는 복잡한 디코더를 피한다. 제안된 MLP 디코더는 다양한 레이어에서 정보를 집계하며, 이를 통해 로컬 어텐션(local attention)과 글로벌 어텐션(global attention)을 결합하여 강력한 표현을 생성한다.
우리는 이러한 단순하고 경량화된 설계가 Transformer 기반 분할에서 효율성의 핵심임을 보인다.
이 방식을 확장하여 SegFormer-B0부터 SegFormer-B5까지 일련의 모델을 구축하였고, 기존 방법보다 성능과 효율 면에서 월등한 결과를 얻었다. 예를 들어, SegFormer-B4는 64M 파라미터로 ADE20K에서 50.3% mIoU를 달성했으며, 이는 기존 최고 성능 모델보다 5배 작고 2.2% 높은 성능이다. 가장 성능이 좋은 SegFormer-B5는 Cityscapes 검증 세트에서 84.0% mIoU를 기록, Cityscapes-C에서 뛰어난 zero-shot 강인성을 보였다.
코드는 다음 주소에서 공개될 예정이다:
👉 https://github.com/NVlabs/SegFormer
1. 서론 (Introduction)
의미론적 분할(Semantic Segmentation)은 컴퓨터 비전의 기본적인 작업이며, 다양한 후속 응용들을 가능하게 한다. 이는 이미지 분류와 밀접하게 관련되어 있는데, 이미지 전체에 대한 클래스 예측이 아닌 픽셀 단위의 클래스 예측을 수행하기 때문이다.
이러한 관계는 FCN(Fully Convolutional Networks)을 이용한 시초 연구에서 지적되었고 체계적으로 연구되었다 [1]. 이후로 FCN은 많은 후속 연구의 기반이 되었으며, 현재까지도 밀집 예측(dense prediction)을 위한 대표적인 설계 방식으로 자리잡았다.
의미론적 분할과 이미지 분류는 밀접한 관계가 있기 때문에, 많은 최신 분할 프레임워크들은 ImageNet 이미지 분류 모델의 변형을 기반으로 한다. 따라서 백본(backbone) 아키텍처 설계는 여전히 의미론적 분할에서 핵심적인 연구 분야다. 초기 VGG 계열의 모델부터 시작해, 훨씬 더 깊고 강력한 백본 구조로의 발전은 성능을 획기적으로 끌어올렸다.
백본 이외에도 또 다른 연구 방향은 의미론적 분할을 구조적 예측 문제(structured prediction problem)로 바라보며, 문맥 정보를 효과적으로 캡처할 수 있는 모듈과 연산자(operator)를 설계하는 것이다. 대표적인 예로는 dilated convolution이 있으며, 이는 필터에 ‘구멍’을 넣어 수용 범위(receptive field)를 넓힌다 [4,5].
자연어 처리(NLP) 분야에서 Transformer의 성공을 목격한 후, 이를 비전 분야에도 도입하려는 시도가 활발히 이루어지고 있다. 예를 들어 Dosovitskiy et al.은 Vision Transformer (ViT)를 제안하며, 이미지를 여러 패치로 나눈 후 이를 positional embedding과 함께 Transformer에 입력하여 ImageNet에서 인상적인 성능을 달성하였다 [6].
의미론적 분할에서도 ViT 기반의 SETR 모델이 처음으로 Transformer 기반 구조의 가능성을 보여주었다 [7]. SETR은 ViT를 백본으로 사용하고, CNN 디코더를 통해 특징 해상도를 확장한다. 하지만 ViT는 다음과 같은 한계를 지닌다:
- 단일 해상도의 저해상도 feature만 출력한다.
- 큰 이미지를 처리할 때 계산 비용이 높다.
이러한 문제를 해결하기 위해, Wang et al.은 pyramid 구조를 도입한 Pyramid Vision Transformer (PVT)를 제안하였다 [8]. PVT는 객체 탐지 및 의미론적 분할에서 ResNet 기반 모델을 능가하는 성능을 보였다. 이후 Swin Transformer, Twins 등의 구조가 등장했지만, 이들 대부분은 인코더 구조 설계에 집중했으며, 디코더 설계의 중요성은 간과하였다.
이 논문에서는 효율성, 정확도, 강인성을 모두 고려한 최첨단 Transformer 기반 의미론적 분할 프레임워크인 SegFormer를 소개한다. 이전 방식들과 달리, SegFormer는 인코더와 디코더 모두를 새롭게 설계하였다. 본 논문의 핵심 기여는 다음과 같다:
- 포지셔널 인코딩 없이도 위치 정보를 학습할 수 있는 계층적 Transformer 인코더
- 복잡한 모듈 없이도 강력한 표현을 생성하는 경량 MLP 디코더
- 세 가지 공개 의미론 분할 데이터셋에서 효율성과 정확도 모두에서 최신 state-of-the-art 성능 달성
제안된 인코더는 학습 시와 테스트 시 해상도가 다르더라도 성능 저하 없이 적응이 가능하며, 고해상도 세부 정보와 저해상도 추상 정보를 동시에 생성할 수 있는 계층 구조를 갖는다. 반면 ViT는 고정 해상도의 단일 feature map만 출력한다.
디코더는 Transformer에서 유도된 로컬 어텐션(하위 계층)과 비로컬 어텐션(최상위 계층)을 결합하는 방식으로, 멀티 레벨 정보를 통합하여 간단하지만 강력한 표현을 생성한다.
2. 관련 연구 (Related Work)
의미론적 분할 (Semantic Segmentation)
의미론적 분할은 이미지 분류를 이미지 수준에서 픽셀 수준으로 확장한 작업이라 볼 수 있다. 딥러닝 시대에 접어들면서 [12–16], FCN(Fully Convolutional Network) [1]은 의미론적 분할의 근간을 이룬 핵심 연구로, end-to-end 방식으로 픽셀 단위 분류를 수행할 수 있게 했다.
이후 연구들은 FCN의 성능을 개선하기 위해 여러 방향으로 발전해왔다. 주요 흐름은 다음과 같다:
- 수용 영역(receptive field) 확대 [17–19, 5, 2, 4, 20]
- 문맥 정보(contextual information)의 정제 [21–29]
- 경계 정보 활용 [30–37]
- 다양한 어텐션 모듈 설계 [38–46]
- AutoML 기반 구조 검색 [47–51]
이러한 접근 방식들은 의미론적 분할 성능을 비약적으로 향상시켰지만, 그 대가로 복잡하고 계산량이 큰 설계를 초래했다.
최근에는 Transformer 기반 아키텍처가 의미론적 분할에 효과적임이 입증되었지만 [7, 46], 이들 역시 계산량이 높아 실시간 처리에는 부적합한 경우가 많다.
Transformer 백본 (Transformer Backbones)
ViT [6]는 Transformer만으로 이미지 분류에서 최고 성능을 달성할 수 있음을 처음 증명한 연구이다. ViT는 이미지를 토큰 시퀀스로 간주하고, 이를 여러 Transformer 계층에 입력하여 분류한다.
이후 DeiT [52]는 데이터 효율적인 학습 전략과 distillation 기법을 통해 ViT의 성능을 더욱 개선했다.
더 최근 연구들(T2T-ViT [53], CPVT [54], TNT [55], CrossViT [56], LocalViT [57])은 ViT의 구조를 다양한 방식으로 개선하여 분류 성능을 끌어올렸다.
분류를 넘어서: 밀집 예측을 위한 Transformer 구조
PVT (Pyramid Vision Transformer) [8]는 Transformer에 피라미드 구조를 도입하여 의미론적 분할 및 객체 탐지 같은 밀집 예측 작업에서 기존 CNN 백본을 능가하는 성능을 보였다.
그 뒤를 이어 Swin [9], CvT [58], CoaT [59], LeViT [60], Twins [10] 등은 로컬 연속성 유지 및 고정 크기 positional embedding 제거 등을 통해 Transformer의 성능을 한층 더 끌어올렸다.
특정 작업에 Transformer를 적용한 사례들
- DETR [52]: NMS 없이 end-to-end 객체 탐지 프레임워크를 처음으로 구축한 Transformer 기반 모델
- 기타 적용 분야: 추적(tracking) [61, 62], 초해상도(super-resolution) [63], Re-ID [64], 색상화(colorization) [65], 검색(retrieval) [66], 멀티모달 학습 [67, 68] 등
의미론적 분할에서는 SETR [7]이 ViT [6]를 백본으로 활용하여 특징을 추출하고 여러 CNN 디코더를 결합하여 인상적인 성능을 보였다.
그러나 이러한 Transformer 기반 방식들은 효율성이 매우 낮아, 실제 실시간 환경에 배포하기에는 현실적인 제약이 많다.
3. 방법론 (Method)

이 장에서는 복잡한 수작업 모듈 없이도 효율적이고, 강인하며, 강력한 분할 프레임워크인 SegFormer를 소개한다.
그림 2에 나타난 것처럼, SegFormer는 다음 두 가지 핵심 구성 요소로 구성된다:
- 계층적 Transformer 인코더: 고해상도의 거친(coarse) 특징과 저해상도의 정교한(fine) 특징을 생성
- 경량 All-MLP 디코더: 위에서 추출한 다중 수준 특징들을 융합하여 의미론적 분할 마스크를 생성
입력 및 전처리
입력 이미지 크기가 H \times W \times 3일 때, 이를 먼저 4 \times 4 크기의 패치들로 나눈다. 이는 기존 ViT가 사용하는 16 \times 16보다 작으며, 밀집 예측에 더 적합하다.
이 패치들을 계층적 Transformer 인코더에 입력하여 \frac{1}{4}, \frac{1}{8}, \frac{1}{16}, \frac{1}{32} 해상도에서 멀티 레벨 특징을 추출한다.
그 후 이들 특징은 All-MLP 디코더로 전달되어 최종적으로
\frac{H}{4} \times \frac{W}{4} \times N_{\text{cls}} 크기의 분할 마스크를 출력한다.
(N_{\text{cls}}: 클래스 수)
3.1 계층적 Transformer 인코더 (Hierarchical Transformer Encoder)
우리는 MiT(Mix Transformer) 시리즈 MiT-B0 ~ MiT-B5를 설계했다. 이들은 아키텍처는 동일하지만 크기(파라미터 수, 레이어 수 등)가 다르다.
예: MiT-B0 → 가장 작고 빠름, MiT-B5 → 가장 크고 정확도 높음
✅ 계층적 특징 표현 (Hierarchical Feature Representation)
기존 ViT는 단일 해상도의 특징맵만 생성한다. 이에 반해 우리는 CNN처럼 다중 수준의 특징맵을 생성하도록 인코더를 설계하였다.
예:
입력 이미지 크기 H \times W \times 3 →
→ 단계별로 downsampling 하여, 각 단계 i에서
F_i = \frac{H}{2^{i+1}} \times \frac{W}{2^{i+1}} \times C_i 형태의 피처맵을 생성한다.
한 번에 끝내는 대신, 이미지를 점점 줄여가며 크기(공간)는 작지만 정보는 점점 추상화된 특징들을 여러 수준으로 뽑아낸다는 의미
SegFormer 인코더는 4단계로 나뉘어 각기 다른 해상도에서 특징(feature map)을 뽑
✅ Overlapping Patch Merging
ViT는 비중첩(non-overlapping) 패치를 사용하여 지역 연결(local continuity)을 놓친다.
SegFormer는 중첩(overlapping) 패치 병합을 적용하여 이 문제를 해결했다.
- 커널 크기 K, 스트라이드 S, 패딩 P 설정
- 실험에서:
- K=7, S=4, P=3
- K=3, S=2, P=1 사용
Transformer 인코더에서도 커널을 겹치게(stride < kernel size) 움직이며
패치들을 추출해서 연속적인 지역 정보를 유지
✅ 효율적인 자기어텐션 (Efficient Self-Attention)
Transformer의 연산 병목은 self-attention 연산에 있다. 기존 방식은
복잡도 \mathcal{O}(N^2) (N: 토큰 수)로 매우 비싸다.
SegFormer는 Sequence Reduction 기법 [8]을 적용하여 연산을 경량화:
- 시퀀스를 R배 줄이고
- 복잡도는 \mathcal{O}(N^2 / R)로 감소
- 실험에서 R = [64, 16, 4, 1] (stage 1~4)
✅ Mix-FFN: 위치 인코딩 없이 위치 정보 학습
기존 Transformer는 위치 정보를 위해 positional encoding을 사용하지만,
이는 해상도 변화 시 성능이 저하되는 단점이 있다.
SegFormer는 Mix-FFN을 통해 positional encoding을 제거하고, 대신
3×3 convolution을 FFN에 삽입하여 위치 정보 학습이 가능하도록 했다:
x_{\text{out}} = \text{MLP}(\text{GELU}(\text{Conv}{3\times3}(\text{MLP}(x{\text{in}}))) + x_{\text{in}}
여기서 MLP는 depth-wise convolution으로 구현되어 파라미터 수 최소화 + 연산 효율 확보
3.2 경량 All-MLP 디코더 (Lightweight All-MLP Decoder)
SegFormer의 디코더는 복잡한 수작업 모듈 없이 MLP만으로 구성된다.
이는 Transformer 인코더가 넓은 수용 영역(ERF)을 갖고 있어 가능하다.
디코더는 다음과 같이 동작한다:
- 각 단계의 멀티 레벨 피처 F_i를 받아 MLP로 채널 정규화
- 모든 피처를 \frac{1}{4} 해상도로 upsample
- 이어 붙이고(concat) MLP로 융합
- 최종적으로 또 다른 MLP로 분할 마스크 M 생성
\begin{align*} \hat{F}_i &= \text{Linear}(C_i, C)(F_i) \\ \hat{F}_i &= \text{Upsample}(\hat{F}_i) \\ F &= \text{Linear}(4C, C)(\text{Concat}(\hat{F}i)) \\ M &= \text{Linear}(C, N{\text{cls}})(F) \end{align*}

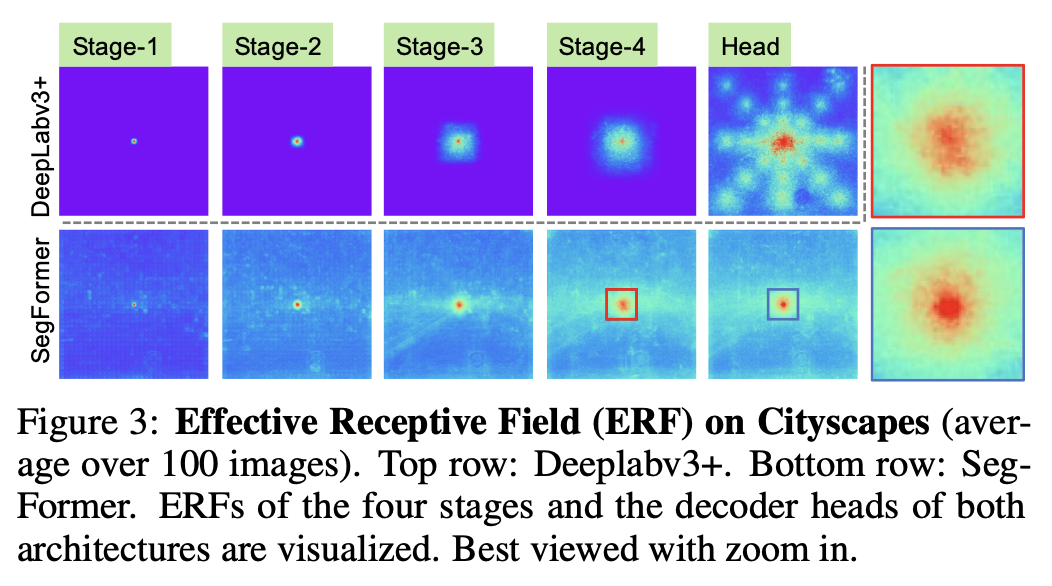
✅ 수용 영역 분석 (Effective Receptive Field, ERF)
- DeepLabv3+는 stage-4에서도 수용 영역이 작음
- SegFormer는 하위 계층에서 로컬 어텐션, 상위 계층에서 비로컬 어텐션을 동시에 학습
- MLP 디코더는 이 두 정보를 조합하여 더 강력한 표현력을 획득함
CNN 백본에서 이 MLP 디코더를 적용하면 성능이 떨어진다 → Transformer 특유의 ERF 활용이 핵심
3.3 SETR와의 비교
SegFormer는 SETR 대비 다음과 같은 개선점을 가진다:
- ImageNet-1K만으로 사전 학습 (SETR은 ImageNet-22K 사용)
- 계층적 인코더 구조 → 고해상도 coarse + 저해상도 fine 피처 동시 생성
- positional encoding 제거 → 해상도 변화에도 robust
- MLP 기반 경량 디코더 → 연산량 적고 효율적
4. 실험 (Experiments)
4.1 실험 설정 (Experimental Settings)
데이터셋
우리는 다음의 공개 데이터셋 세 가지를 사용했다:
- ADE20K [72]: 150개의 세밀한 의미론적 클래스가 포함된 장면 파싱(scene parsing) 데이터셋, 총 20,210장의 이미지로 구성
- Cityscapes [71]: 19개 카테고리를 가진 운전 환경의 고해상도 이미지 5,000장
- COCO-Stuff [73]: 172개의 라벨과 총 164,000장의 이미지 (train 118k, val 5k, test-dev 20k, test-challenge 20k)
구현 세부사항
- 프레임워크: mmsegmentation
- GPU: Tesla V100 8개
- 인코더는 ImageNet-1K로 사전 학습, 디코더는 무작위 초기화
- 데이터 증강:
- 랜덤 리사이즈 (비율 0.5~2.0)
- 수평 뒤집기
- 랜덤 크롭:
- ADE20K: 512×512 (B5는 640×640)
- Cityscapes: 1024×1024
- COCO-Stuff: 512×512
- 옵티마이저: AdamW
- 학습 반복:
- ADE20K, Cityscapes: 160K
- COCO-Stuff: 80K
- Ablation 실험: 40K
- 학습 반복:
- 배치 크기: ADE20K/COCO-Stuff = 16, Cityscapes = 8
- 초기 학습률: 0.00006, Poly LR 스케줄 사용
- OHEM, 보조 손실, 클래스 불균형 보정은 사용하지 않음
- 평가 시, 짧은 축을 학습 크기로 리스케일 + 비율 유지
- Cityscapes: 슬라이딩 윈도우(1024×1024) 방식 사용
- 평가지표: mean Intersection over Union (mIoU)
4.2 Ablation Study (구성 요소 분석)
✅ 모델 크기 변화가 성능에 미치는 영향
- MiT-B0 ~ B5 모델을 비교
- 디코더는 B0에서는 0.4M 파라미터, B5에서도 전체 파라미터의 4% 이하만 차지
- 인코더 크기를 키울수록 모든 데이터셋에서 성능이 지속적으로 증가
- SegFormer-B0: 경량화된 실시간 모델
- SegFormer-B5: 세 데이터셋 모두에서 state-of-the-art 성능
✅ MLP 디코더의 채널 차원 C 영향
- C 값: 256, 512, 768, 1024, 2048로 실험
- C=256: 효율성과 정확도의 균형
- C 증가 시 성능은 다소 향상되지만, C > 768부터는 성능 향상 정체
- 최종 선택:
- SegFormer-B0, B1: C=256
- SegFormer-B2 이상: C=768
✅ Mix-FFN vs Positional Encoding (PE)
- Cityscapes에서 두 해상도(768×768, 1024×2048)로 비교
- 결과:
- 동일 해상도일 때도 Mix-FFN이 더 높은 mIoU
- 테스트 해상도 변경 시, PE는 성능 3.3% 감소, Mix-FFN은 0.7% 감소에 그침
- → Mix-FFN이 더 강건함
✅ CNN 백본과 Transformer 백본 비교
- MLP 디코더를 CNN (ResNet50, ResNet101, ResNeXt101)과 결합
- 동일한 디코더 사용 시 CNN 백본은 성능이 낮음
- CNN은 수용 영역이 작기 때문
- Transformer 백본(MiT)은 저수준 로컬 피처 + 고수준 비로컬 피처를 동시에 결합 가능
4.3 기존 방법과의 비교
✅ ADE20K와 Cityscapes 비교 (Table 2)
Real-Time 세팅:
- SegFormer-B0:
- 37.4% mIoU / 8.4G FLOPs / 50.5 FPS
- DeeplabV3+(MobileNetV2) 대비:
- mIoU +3.4%
- 속도 +7.4 FPS
- 파라미터 1/4
High-Performance 세팅:
- SegFormer-B5:
- 51.8% mIoU (ADE20K)
- 84.0% mIoU (Cityscapes)
- 기존 최고 성능 모델 SETR 대비:
- mIoU +1.6%
- 5배 빠름, 4배 작음
✅ Cityscapes 테스트셋 비교 (Table 3)
- SegFormer-B5 (ImageNet-1K + Mapillary Vistas 사용):
- 83.1% mIoU
- SETR (ImageNet-22K + Coarse)보다 성능 우위
- 추가 데이터 없이도 SETR을 능가함
✅ COCO-Stuff 전체 성능 비교 (Table 4)
- SegFormer-B5:
- 46.7% mIoU / 84.7M 파라미터
- SETR보다 +0.9% mIoU, 모델 크기는 4배 작음
4.4 자연스러운 왜곡에 대한 강인성 (Robustness to Corruptions)
- 실험: Cityscapes-C (Cityscapes 검증셋 + 16가지 인공 왜곡: noise, blur, weather 등)
- SegFormer-B5 vs DeepLabV3+ 비교 (Table 5)
결과:
- Gaussian Noise: 최대 +588% 향상
- Snow: +295% 향상
- SegFormer는 대부분의 왜곡 유형에서 월등한 zero-shot 강인성을 보임
5. 결론 (Conclusion)
이 논문에서는 SegFormer를 소개하였다.
SegFormer는 간결하고 깔끔하면서도 강력한 의미론적 분할(Semantic Segmentation) 프레임워크로서 다음과 같은 특징을 가진다:
- 포지셔널 인코딩(position encoding)을 제거한 계층적 Transformer 인코더
- 수작업 튜닝이 필요 없고 계산적으로 가벼운 All-MLP 디코더
SegFormer는 기존 방법들이 사용하는 복잡한 설계 요소들을 모두 배제하면서도,
높은 효율성과 우수한 정확도를 동시에 달성하였다.
뿐만 아니라, 일반적인 데이터셋에서 최신 state-of-the-art 성능을 기록했으며,
zero-shot 환경에서의 강인성 역시 매우 뛰어남을 보였다.
우리는 SegFormer가 의미론적 분할을 위한 강력한 기본 베이스라인으로 작용하고,
후속 연구의 출발점이 되기를 기대한다.
한계점 (Limitation)
SegFormer의 가장 작은 모델인 3.7M 파라미터 모델(B0)은 기존 CNN 기반 모델보다 작지만,
100KB 이하의 메모리만 허용되는 극한의 엣지 디바이스에서 원활히 동작할 수 있을지는 아직 불확실하다.
이 점은 향후 과제로 남겨둔다.
✅ SegFormer: 핵심 요약
🔷 문제 배경
- 기존 의미론적 분할 모델은 복잡한 구조(예: ASPP, heavy 디코더, positional encoding)에 의존하며,
- 실시간 처리에 비효율적이고, 고해상도 대응력이나 왜곡에 대한 강인성도 부족함.
🔷 제안된 모델: SegFormer
SegFormer는 다음의 두 구성 요소로 이뤄진 효율적인 분할 프레임워크다:
- Mix Transformer 인코더 (MiT)
- 계층적 구조로 다중 해상도 특징 추출 가능
- positional encoding 제거 → 해상도 변화에 강건
- Mix-FFN + overlapping patch merging + efficient attention으로 정확도와 연산 효율 동시 확보
- All-MLP 디코더
- 복잡한 구조 없이 단순 MLP만으로 다중 수준 특징을 융합
- 연산량 낮고, 파라미터 수 적으며, 정확도 유지
- Transformer 인코더의 넓은 수용 영역(ERF) 덕분에 MLP만으로도 좋은 성능 가능
🔷 실험 결과 요약
- ADE20K, Cityscapes, COCO-Stuff에서 모두 SOTA 성능 달성
- SegFormer-B5:
- ADE20K: 51.8% mIoU (기존보다 +1.6%)
- Cityscapes: 84.0% mIoU
- COCO-Stuff: 46.7% mIoU
- SegFormer-B0:
- 실시간 성능에서도 기존 모델보다 빠르고 정확 (37.4% mIoU, 50+ FPS)
🔷 강점 요약
- 💡 간단하고 튜닝 없는 설계 (No ASPP, No PE, No 복잡 디코더)
- ⚡ 빠르고 작고 강력함 (실시간 처리 가능)
- 🔍 Zero-shot 강인성 뛰어남 (Cityscapes-C 왜곡 테스트에서 압도적인 성능)
- 🧠 인코더의 ERF 활용 + 단순 MLP 디코더 조합이 핵심
Transformer는 고유하게 매우 넓은 ERF (Effective Receptive Field)를 가진다.
🔍 ERF (Effective Receptive Field) = 실질적으로 영향을 주는 입력 영역
- CNN에서는 어떤 출력 픽셀이 영향을 받는 입력 영역의 범위를 “수용 영역(Receptive Field)“이라고 해.
- 예를 들어 CNN에서 3×3 필터를 3번 적용하면 대략 7×7 크기의 정보를 보는 셈이지.
- 하지만 이론적인 receptive field보다 실제로 모델이 집중해서 쓰는 정보 영역(=ERF)는 더 작을 수 있어.
ERF가 넓을수록 → 더 넓은 문맥 정보, 더 나은 전역 구조 파악 가능.
✅ Transformer는 왜 ERF가 넓을까?
Transformer는 Self-Attention을 통해 모든 위치의 정보를 직접 연결해서 처리함.
- CNN은 이웃 정보만 단계적으로 모아야 하기 때문에 ERF가 작게 시작해서 천천히 커짐
- 반면 Transformer는 한 단계에서 전 위치 간 정보 교환이 일어나기 때문에
- 단 한 단계만으로도 이론적으로 전 범위에 대한 정보 접근이 가능해.
👉 즉, Transformer의 ERF는 전역적(global)이고,
학습이 잘 되면 실제로도 그 넓은 영역을 잘 활용하게 돼.
✅ SegFormer에서 ERF의 역할
SegFormer는 디코더를 단순한 MLP로 구성했어. 그런데도 잘 작동하는 이유는:
인코더가 이미 전역 정보를 충분히 담은 강력한 표현을 제공해주기 때문이야.
즉,
- CNN이라면 디코더에서 복잡한 구조(ASPP, CRF 등)로 전역 정보를 다시 조합해야 하는데
- Transformer는 인코더 단계에서 이미 넓은 ERF 덕분에 context-rich한 feature를 만들어냄
- 그래서 디코더는 단순하게 MLP만 써도 충분히 정확한 예측이 가능


