
저번 LLM 정리글에 지인이 답변을 달아 줬다.
알아보자
🥟 tokenization 토큰화
text : 문서나 문장
Corpus(말뭉치) : 텍스트에서 데이터 분석이나 모델 개발 등 특정 목적을 위해 수집된 텍스트 데이터
Tokenization : 텍스트를 작은 단위(토큰)로 분리하는 것
Features : 토큰화, 정제, 정규화, 불용어 처리, 인코딩 등 여러 단계를 거쳐 실제 모델의 입력 데이터
단어 사전 : 토큰의 리스트
🦾 Word Tokenization
- 가장 일반적인 토큰화 방법
- 특정 구분기호를 가지고 텍스트를 나누는 방법 (영어의 경우 기본적으로 공백 / 한글의 경우 교착어라는 특징 - 단어 구분이 쉽지 않음)
< 단점 1 >
OOV 문제(Out Of Vocabulary)
입력된 데이터가 이미 만들어져 있던 단어사전에 없는 경우 발생
단어 사전 : 코퍼스 데이터에서 만들어지기 때문에 모든 단어를 가지고 있지 않음
-> 훈련 시 없던 단어가 입력으로 들어올 때 문제 발생
해결책
UNK(Unknown Tocken) 만들기
훈련 데이터에서 많이 출현하지 않는 단어/토큰을 UNK로 사전에 등록
하지만 OOV 단어가 많으면 모델이 잘 동작하지 않을 가능성 있음
시간
단어 사전이 클수록 사전에서 단어를 찾고 표현을 찾는 데에 시간이 많이 소요.
고용량의 메모리가 있는 서버 컴퓨팅 자원이 필요.
🦾 Character Tokenization
- 코퍼스를 문자로 분리
영어: 알파벳 26개
한글: 자음과 모음
OOV 문제가 해결
메모리 문제도 해결
< 단점 >
한 건의 입력 내용이 길어짐
-> 모델이 단어간의 관계를 학습하는 것을 어렵게 만듦
🦾 Subword Tokenization
- character tokenization의 확장 버전
- n개의 문자(n-gram characters)(적절한 단위)를 가지고 나누는 방법
- token들의 빈도를 기반으로 높은 빈도의 토큰들을 merge해가며 최종 token들을 만들어내는 방법
서브 워드를 만드는 알고리즘 중에서 가장 유명한 방법 :
BPE(Byte Pair Encoding)
문장을 형태소로 나누어서 각 형태소 별로 인코딩을 하는 방법입니다.
한국어는 형태소 분절 기반의 서브 단어 토큰화 사용을 주로 함
Byte-Pair Encoding tokenization - Hugging Face NLP Course
Byte-Pair Encoding (BPE) was initially developed as an algorithm to compress texts, and then used by OpenAI for tokenization when pretraining the GPT model. It’s used by a lot of Transformer models, including GPT, GPT-2, RoBERTa, BART, and DeBERTa. 💡
huggingface.co
🥟 Chain-of-Thought (CoT)
- 문제의 인과 관계에 대해 프롬프트 작성
- ‘문제-답’ 대신에 ‘문제-풀이-답’ 형태로 프롬프트를 구성
=> 성능이 크게 향상됨
🦾zero-shot prompting
- 추가적인 학습 없이 새로운 데이터에 대한 예측을 가능하게 하는 기법
🦾one-shot prompting
- 한 가지의 입력 데이터를 사용하여 자연어 텍스트를 생성하는 기법
🦾few-shot prompting
- 적은 수의 예시(2-5)를 사용하여 자연어 텍스트를 생성하는 기법
🦾zero-shot prompting with CoT
🟢 Zero Shot Chain of Thought | Learn Prompting: Your Guide to Communicating with AI
Zero Shot Chain of Thought (Zero-shot-CoT) prompting (@kojima2022large) is a
learnprompting.org
🦾few-shot prompting with CoT
으윽..못찾겠다
아무튼 둘 다 정확도가 상승할 듯
🥟 scaling law
LM -> LLM 으로 파라미터가 급격히 증가된 모습
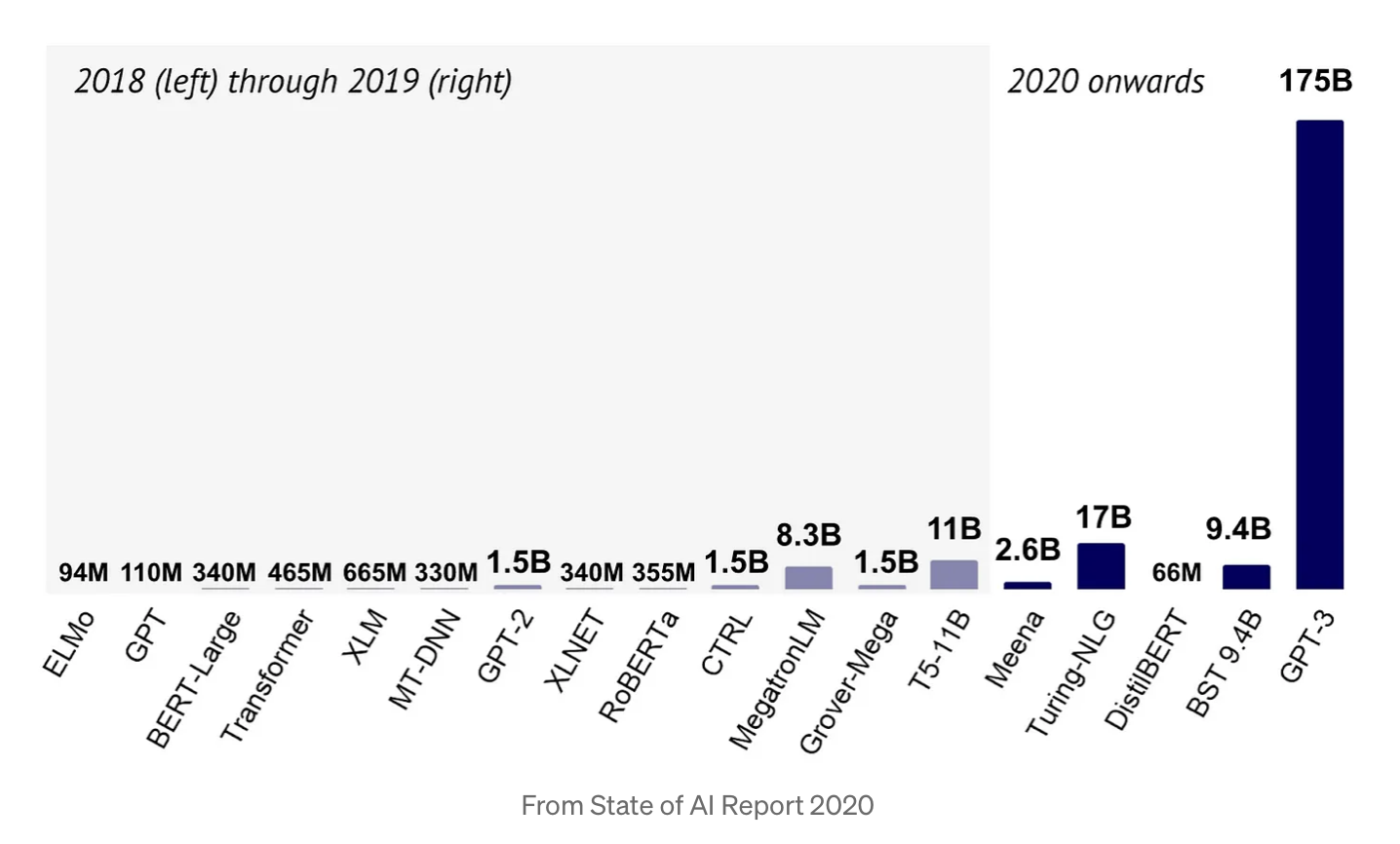
2020, OpenAI : Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models
We study empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitu
arxiv.org
데이터 크기 D, 계산량 C, 모델크기 N
- 성능은 모델의 형태(width, depth)보다는 크기에 의존
- 성능은 다른 두 항목에 의해 병목 현상이 발생하지 않는 경우 세 가지 척도 요소 N, D, C 각각과 power-law를 가짐
- N와 D를 같이 키우면 성능은 예측 가능하게 증가하지만, 한쪽을 고정하면 어느 시점에서 성능이 향상되지 않는다. → 큰 모델은 더 많은 데이터를 필요로 함
- 큰 모델은 작은 모델에 비해 동일한 성능에 더 적은 데이터로 도달 → 데이터 대비 학습 효과가 좋음
=> 데이터를 더 확보하기보다는 모델을 더 키우는 쪽이 효율적
🦾emergent abilities
LLM의 성능은 선형적으로 증가하지 않고 특정 크기를 넘을 때마다 큰 폭으로 증가함
🥟 Fine-tuning vs pre-training vs transfer learning
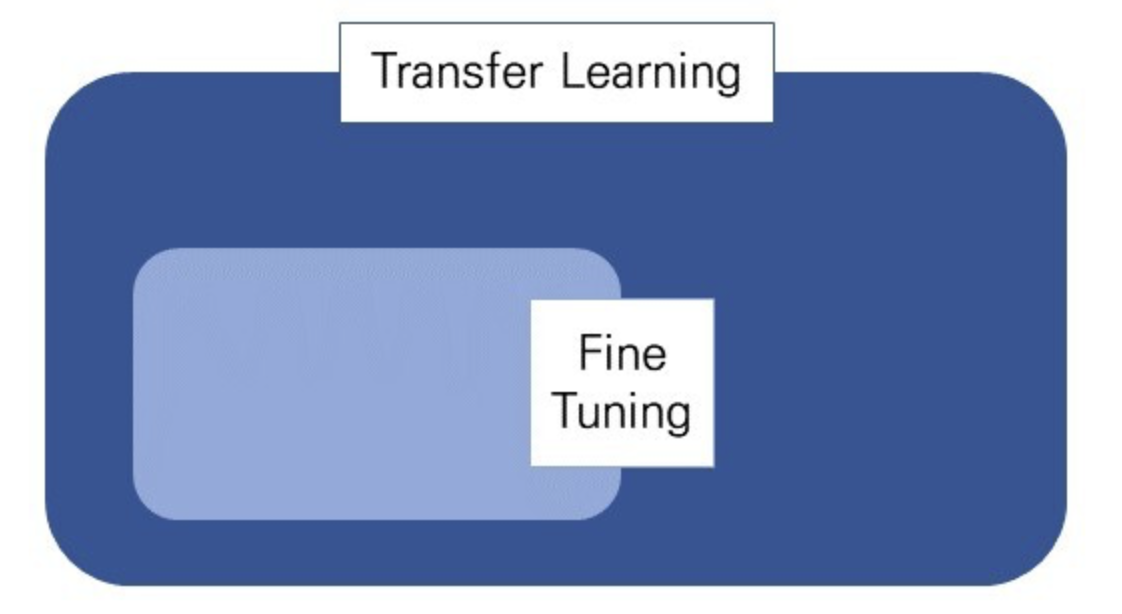
🦾 pre-training
학습이 완료되어 output 도출이 가능한 초기 모델
🦾 transfer learning
: 전이학습(domain adaptation)
특정 분야에서 학습된 신경망의 일부 능력을 유사하거나 전혀 새로운 분야에서 사용되는 신경망의 학습에 이용하는 것을 의미
사전에 학습된 모델 : pre-trained model
=> 이를 활용하여 새로운 데이터셋을 학습하는 과정(transfer learning)
기존 학습된 것을 Freeze시킨 채로 맨 위 Layer만 학습
🦾 Fine-tuning
얻고자 하는 결과값이 다를 때 마지막 output layer를 삭제하고 다른 layer를 붙여서 모델 재학습
🥟 Bias-variance tradeoff
supervised learning 알고리즘이 training set의 범위를 넘어 지나치게 일반화하는 것을 예방하기 위해 두 종류의 오차 ( bias, variance)를 최소화할 때 겪는 문제
- 오차를 편향, 분산, 그리고 데이터 자체가 내재하고 있어 어떤 모델링으로도 줄일수 없는 오류의 합으로 봄 (100% 불가)
Bias
- 잘못된 가정을 했을 때 발생하는 오차
- 높은 편향값은 알고리즘이 데이터의 특징과 결과물과의 적절한 관계를 놓치게 만드는 과소적합(underfitting) 문제를 발생시킴
Variance
- 트레이닝 셋에 내재된 작은 변동(fluctuation) 때문에 발생하는 오차
- 높은 분산값은 큰 노이즈까지 모델링에 포함시키는 과적합(overfitting) 문제를 발생시킴
그렇군
'🤖 AI > AI' 카테고리의 다른 글
| ✅ Viuron - Kia_EV6_RAG (0) | 2024.04.01 |
|---|---|
| 📖논문 - Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4 (2) | 2024.03.20 |
| 신촌정보 MY GPTS 만들어보기 (0) | 2024.01.24 |
| 🦾LLM 강의 정리~!~!🦾 (4) | 2024.01.23 |
| 🤖LLM - 대규모 언어 모델 (0) | 2023.09.28 |


