Retrieval | 🦜️🔗 LangChain
Many LLM applications require user-specific data that is not part of the model's training set.
python.langchain.com
LLM applications require user-specific data that is not part of the model's training set.
=> Retrieval Augmented Generation (RAG)
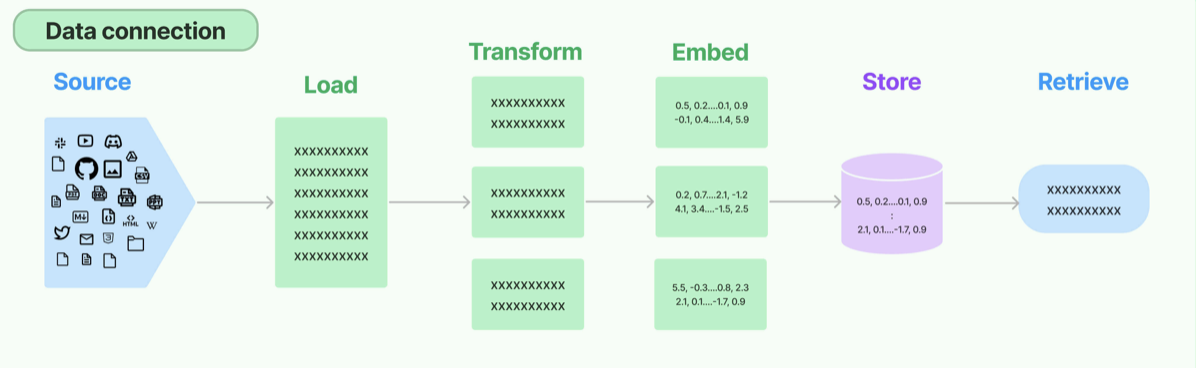
랭체인에서 RAG를 하기 위한 요소들
🦜Document loaders
다양한 출처에서 문서(user-specific data)를 로드
- 100개가 넘는 다양한 문서 로더 보유
- LangChain은 모든 유형의 문서(HTML, PDF, 코드)를 모든 유형의 위치(개인 S3 버킷, 공개 웹사이트)에서 로드할 수 있는 통합을 제공
🦜Text Splitting
큰 문서를 더 작은 조각으로 분할(또는 청킹)하는 것
- 검색의 핵심 부분은 문서의 관련 부분만 가져오는 것
🦜Text embedding models
문서의 임베딩을 생성하는 것
- 임베딩은 텍스트의 의미를 포착하여 유사한 텍스트 조각을 빠르고 효율적으로 찾을 수 있게 함
- LangChain은 오픈 소스부터 독점 API에 이르기까지 25개 이상의 다른 임베딩 제공업체 및 방법과 통합을 제공
🦜Vector stores
임베딩의 효율적인 저장 및 검색을 지원하는 데이터베이스
- LangChain은 오픈 소스 로컬 저장소부터 클라우드 호스팅 독점 저장소에 이르기까지 50개 이상의 다양한 벡터 저장소와의 통합을 제공
🦜Retrievers
데이터베이스에 있는 데이터 검색
- Parent Document Retriever
: 부모 문서당 여러 임베딩을 생성할 수 있게 하여 더 작은 조각을 검색하지만 더 큰 맥락을 반환
- Self-querying
: 질문에서 의미론적 부분을 다른 메타데이터 필터와 분리
- Ensemble Retriever
: 여러 다른 출처에서 또는 여러 다른 알고리즘을 사용하여 문서를 검색
- 기타
🦜Indexing
LangChain 인덱싱 API
데이터를 벡터 저장소로 동기화
벡터 저장소에 중복 콘텐츠를 작성하지 않도록 함
변경되지 않은 콘텐츠를 다시 작성하지 않도록 함
변경되지 않은 콘텐츠에 대해 임베딩을 다시 계산하지 않도록 함
=> 시간과 돈을 절약하고 벡터 검색 결과를 개선
'🤖 AI > AI' 카테고리의 다른 글
| 🌷구축형 AI 환경 세팅하기2 🌷 (2) | 2024.05.16 |
|---|---|
| 🦙 LlamaIndex - RAG 정리 (0) | 2024.05.10 |
| 🪻구축형 AI 환경 세팅하기 🪻 (1) | 2024.04.08 |
| ✅ Viuron - Kia_EV6_RAG (0) | 2024.04.01 |
| 📖논문 - Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4 (2) | 2024.03.20 |


