LLM을 활용한 실전 AI 애플리케이션 개발
- 허정준
🔬허깅페이스 라이브러리 사용법 익히기
모델 / 토크나이저 / 데이터셋
🎀 모델 활용하기
모델 = 바디 + 헤드
1) 바디 불러오기
from transformers import AutoModel
model_id = 'klue/roberta-base'
model = AutoModel.from_pretrained(model_id)Automodel 클래스
- 모델의 바디를 불러오는 클래스
Automodel.from_pretrained(모델 경로)
- 모델 경로 (웹 허브/ 로컬)에서 모델 불러옴
허깅페이스 모델의 config.json
- 모델의 종류, 설정 파라미터, 어휘 사전 크기, 사용하는 토크나이저 클래스 등의 정보가 저장됨
- Automodel 클래스가 참고하여 모델 등을 불러옴
2) 바디+헤드 불러오기
from transformers import AutoModelForSequenceClassification
model_id = 'SamLowe/roberta-base-go_emotions'
classification_model = AutoModelForSequenceClassification.from_pretrained(model_id)AutoModelForSequenceClassification 클래스
- 텍스트 시퀀스 분류를 위한 헤드가 포함된 모델(+바디) 을 불러오는 클래스
3) 바디+헤드 모델에서 바디만 불러오기
from transformers import AutoModelForSequenceClassification
model_id = 'klue/roberta-base'
classification_model = AutoModelForSequenceClassification.from_pretrained(model_id)분류 헤드가 붙은 모델을 불러올 수 있는 AutoModelForSequenceClassification 클래스로 헤드가 없는 모델을(바디 파라미터만) 불러오면?
=> 경고 발생 ( 분류 헤더의 파라미터를 랜덤으로 초기화시킴/ 추가 학습해서 사용할 것)
🎀 토크나이저 활용하기
토크나이저 : 텍스트를 토큰 단위로 나누고 토큰 아이디를 부여
from transformers import AutoTokenizer
model_id = 'klue/roberta-base'
tokenizer = AutoTokenizer.from_pretrained(model_id)AutoTokenizer 클래스
- 모델-토크나이저 호환성 체크하기!
- 토크나이저도 학습 데이터로 "어휘 사전" 구축하기 때문에 모델과 함께 저장
okenized = tokenizer("토크나이저는 텍스트를 토큰 단위로 나눈다")
print(tokenized)
# {'input_ids': [0, 9157, 7461, 2190, 2259, 8509, 2138, 1793, 2855, 5385, 2200, 20950, 2],
# 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
print(tokenizer.convert_ids_to_tokens(tokenized['input_ids']))
# ['[CLS]', '토크', '##나이', '##저', '##는', '텍스트', '##를', '토', '##큰', '단위', '##로', '나눈다', '[SEP]']
print(tokenizer.decode(tokenized['input_ids']))
# [CLS] 토크나이저는 텍스트를 토큰 단위로 나눈다 [SEP]
print(tokenizer.decode(tokenized['input_ids'], skip_special_tokens=True))
# 토크나이저는 텍스트를 토큰 단위로 나눈다tokenizer에 텍스트를 넣으면 반환하는 것
=
토큰 아이디 리스트(토크나이저 사전의 몇 번째 항목인지) input_ids
토큰이 실제 텍스트인지(1)/길이 맞추기용 패딩인지 알려주는 attention_mask
토큰이 속한 문장의 아이디(0 첫 번째 문장) token_type_ids
(skip_special_tokens 특수 토큰 제외)
CLS : 문장이나 입력 텍스트의 시작을 나타내는 토큰
SEP : 문장이나 입력 간의 구분을 나타내는 토큰
decode : 자연어 변환
#예제 3.10. 토크나이저에 여러 문장 넣기
tokenizer(['첫 번째 문장', '두 번째 문장'])
# {'input_ids': [[0, 1656, 1141, 3135, 6265, 2], [0, 864, 1141, 3135, 6265, 2]],
# 'token_type_ids': [[0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0]],
# 'attention_mask': [[1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1]]}
# 예제 3.11. 하나의 데이터에 여러 문장이 들어가는 경우 (괄호 두 개!)
tokenizer([['첫 번째 문장', '두 번째 문장']])
# {'input_ids': [[0, 1656, 1141, 3135, 6265, 2, 864, 1141, 3135, 6265, 2]],
# 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
# 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}여러 개 데이터
여러 개 문장이 한 개의 데이터 -> 대괄호 2개로 감싸기
#예제 3.13. BERT 토크나이저와 RoBERTa 토크나이저
bert_tokenizer = AutoTokenizer.from_pretrained('klue/bert-base')
bert_tokenizer([['첫 번째 문장', '두 번째 문장']])
# {'input_ids': [[2, 1656, 1141, 3135, 6265, 3, 864, 1141, 3135, 6265, 3]],
# 'token_type_ids': [[0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]],
# 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
roberta_tokenizer = AutoTokenizer.from_pretrained('klue/roberta-base')
roberta_tokenizer([['첫 번째 문장', '두 번째 문장']])
# {'input_ids': [[0, 1656, 1141, 3135, 6265, 2, 864, 1141, 3135, 6265, 2]],
# 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
# 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
en_roberta_tokenizer = AutoTokenizer.from_pretrained('roberta-base')
en_roberta_tokenizer([['first sentence', 'second sentence']])
# {'input_ids': [[0, 9502, 3645, 2, 2, 10815, 3645, 2]],
# 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1]]}NSP : 문장이 서로 이어지는지 맞추는 작업
token_type_ids 필요
nsp가 없는 모델에는 token_type_ids 필요 없음
#예제 3.14. attention_mask 확인
tokenizer(['첫 번째 문장은 짧다.', '두 번째 문장은 첫 번째 문장 보다 더 길다.'], padding='longest')
# {'input_ids': [[0, 1656, 1141, 3135, 6265, 2073, 1599, 2062, 18, 2, 1, 1, 1, 1, 1, 1],
# [0, 864, 1141, 3135, 6265, 2073, 1656, 1141, 3135, 6265, 3632, 831, 647, 2062, 18, 2]],
# 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}padding 인자에 longest 를 넣어서
긴 문장을 기준으로 짧은 문장에 패딩 토큰을 채움 (attention_mask[0] 뒷부분)
🎀 데이터셋 활용하기
# 예제 3.15. KLUE MRC 데이터셋 다운로드
from datasets import load_dataset
klue_mrc_dataset = load_dataset('klue', 'mrc')
# klue_mrc_dataset_only_train = load_dataset('klue', 'mrc', split='train')load_dataset()에 인자로 데이터셋 이름/서브셋 을 전달하여 데이터셋 다운
유형(학습/검증 등) / 칼럼 ( 제목/내용/..같은)
#예제 3.16. 로컬의 데이터 활용하기
from datasets import load_dataset
# 로컬의 데이터 파일을 활용
dataset = load_dataset("csv", data_files="my_file.csv")
# 파이썬 딕셔너리 활용
from datasets import Dataset
my_dict = {"a": [1, 2, 3]}
dataset = Dataset.from_dict(my_dict)
# 판다스 데이터프레임 활용
from datasets import Dataset
import pandas as pd
df = pd.DataFrame({"a": [1, 2, 3]})
dataset = Dataset.from_pandas(df)🔬모델 학습하기
한국어 기사 제목으로 카테고리 분류하는 모델 만들기
⚗️ 데이터 준비하기
klue/klue · Datasets at Hugging Face
https://news.naver.com/main/read.nhn?mode=LS2D&mid=shm&sid1=101&sid2=261&oid=001&aid=0008500365
huggingface.co
KLUE 데이터셋의 YNAT 서브셋 사용
remove_columns 메서드
# 예제 3.17. 모델 학습에 사용할 연합뉴스 데이터셋 다운로드
from datasets import load_dataset
klue_tc_train = load_dataset('klue', 'ynat', split='train')
klue_tc_eval = load_dataset('klue', 'ynat', split='validation')
# klue_tc_train
# klue_tc_train[0]
# klue_tc_train.features['label'].names
# ['IT과학', '경제', '사회', '생활문화', '세계', '스포츠', '정치']
# 예제 3.18. 실습에 사용하지 않는 불필요한 컬럼 제거
klue_tc_train = klue_tc_train.remove_columns(['guid', 'url', 'date'])
klue_tc_eval = klue_tc_eval.remove_columns(['guid', 'url', 'date'])
# 예제 3.19. 카테고리를 문자로 표기한 label_str 컬럼 추가
#klue_tc_train.features['label']
# ClassLabel(names=['IT과학', '경제', '사회', '생활문화', '세계', '스포츠', '정치'], id=None)
#klue_tc_train.features['label'].int2str(1)
# '경제'
klue_tc_label = klue_tc_train.features['label']
def make_str_label(batch):
batch['label_str'] = klue_tc_label.int2str(batch['label'])
return batch
klue_tc_train = klue_tc_train.map(make_str_label, batched=True, batch_size=1000)
# klue_tc_train[0]
# {'title': '유튜브 내달 2일까지 크리에이터 지원 공간 운영', 'label': 3, 'label_str': '생활문화'}
#예제 3.20. 학습/검증/테스트 데이터셋 분할
train_dataset = klue_tc_train.train_test_split(test_size=10000, shuffle=True, seed=42)['test']
dataset = klue_tc_eval.train_test_split(test_size=1000, shuffle=True, seed=42)
test_dataset = dataset['test']
valid_dataset = dataset['train'].train_test_split(test_size=1000, shuffle=True, seed=42)['test']
⚗️ 트레이너 API 사용해서 학습하기
트레이너 API
학습에 필요한 다양한 기능 (데이터 로더, 로깅, 평가, 저장, 등)을 제공
모델
klue/roberta-base · Hugging Face
KLUE RoBERTa base Pretrained RoBERTa Model on Korean Language. See Github and Paper for more details. How to use NOTE: Use BertTokenizer instead of RobertaTokenizer. (AutoTokenizer will load BertTokenizer) from transformers import AutoModel, AutoTokenizer
huggingface.co
# 예제 3.21. Trainer를 사용한 학습: (1) 준비
import torch
import numpy as np
from transformers import (
Trainer,
TrainingArguments,
AutoModelForSequenceClassification,
AutoTokenizer
)
def tokenize_function(examples):
return tokenizer(examples["title"], padding="max_length", truncation=True)
model_id = "klue/roberta-base"
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=len(train_dataset.features['label'].names))
tokenizer = AutoTokenizer.from_pretrained(model_id)
train_dataset = train_dataset.map(tokenize_function, batched=True)
valid_dataset = valid_dataset.map(tokenize_function, batched=True)
test_dataset = test_dataset.map(tokenize_function, batched=True)AutoModelForSequenceClassification 클래스로 모델 바디만 불러오고 헤드는 무작위 초기화됨
- 분류 헤드의 분류 클래스 수를 지정하기 위해 num_labels 인자에 데이터셋의 레이블 수인 len(train_dataset.features['label'].names)) 저장
# 예제 3.22. Trainer를 사용한 학습: (2) 학습 인자와 평가 함수 정의
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
evaluation_strategy="epoch", # 한 에포크 학습이 끝날 떄마다 검증 데이터셋에 대한 평가 수행
learning_rate=5e-5,
push_to_hub=False
)
def compute_metrics(eval_pred): # 평가 지표 정의
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return {"accuracy": (predictions == labels).mean()}학습 사용 인자 설정
- 학습 에포크 수
- 배치 크기
- 결과 저장 폴더
- 평가 수행 빈도
평가 지표 함수 정의
# 예제 3.23. Trainer를 사용한 학습 - (3) 학습 진행
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
trainer.evaluate(test_dataset) # 정확도 0.84train() 메서드로 학습 진행
evaluate 메서드로 검증 진행
⚗️ 트레이너 API 사용하지 않고 학습하기
# 예제 3.24. Trainer를 사용하지 않는 학습: (1) 학습을 위한 모델과 토크나이저 준비
import torch
from tqdm.auto import tqdm
from torch.utils.data import DataLoader
from transformers import AdamW
def tokenize_function(examples): # 제목(title) 컬럼에 대한 토큰화
return tokenizer(examples["title"], padding="max_length", truncation=True)
# 모델과 토크나이저 불러오기
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_id = "klue/roberta-base"
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=len(train_dataset.features['label'].names))
tokenizer = AutoTokenizer.from_pretrained(model_id)
model.to(device)model.to(device)
- 기존 train()이 해주던 GPU로의 모델 이동을 직접 수행
예제 3.25 Trainer를 사용하지 않는 학습: (2) 학습을 위한 데이터 준비
def make_dataloader(dataset, batch_size, shuffle=True):
dataset = dataset.map(tokenize_function, batched=True).with_format("torch") # 데이터셋에 토큰화 수행
dataset = dataset.rename_column("label", "labels") # 컬럼 이름 변경
dataset = dataset.remove_columns(column_names=['title']) # 불필요한 컬럼 제거
return DataLoader(dataset, batch_size=batch_size, shuffle=shuffle)
# 데이터로더 만들기
train_dataloader = make_dataloader(train_dataset, batch_size=8, shuffle=True)
valid_dataloader = make_dataloader(valid_dataset, batch_size=8, shuffle=False)
test_dataloader = make_dataloader(test_dataset, batch_size=8, shuffle=False)전처리
- 제목 컬럼에 대한 토큰화 진행
- rename_column 메서드를 통한 컬럼명 재정의
- remove_column으로 컬럼 삭제
- pytorch의 Dataloader 클래스를 이용해 데이터셋을 배치 데이터로 변환
( trainer api는 토큰화를 제외한 나머지 과정을 알아서 처리해줌)
# 예제 3.26. Trainer를 사용하지 않는 학습: (3) 학습을 위한 함수 정의
def train_epoch(model, data_loader, optimizer):
model.train()
total_loss = 0
for batch in tqdm(data_loader):
optimizer.zero_grad()
input_ids = batch['input_ids'].to(device) # 모델에 입력할 토큰 아이디
attention_mask = batch['attention_mask'].to(device) # 모델에 입력할 어텐션 마스크
labels = batch['labels'].to(device) # 모델에 입력할 레이블
outputs = model(input_ids, attention_mask=attention_mask, labels=labels) # 모델 계산
loss = outputs.loss # 손실
loss.backward() # 역전파
optimizer.step() # 모델 업데이트
total_loss += loss.item()
avg_loss = total_loss / len(data_loader)
return avg_loss학습을 위한 함수
train() 메서드
- 모델을 학습 모드로 변경
데이터 로더 내부 배치 데이터
- input_ids : 토큰 아이디
- attention_mask : 어텐션 마스크
- labels : 정답 레이블
=> model에 인자로 전달하여 모델 계산 수행
'모델 계산 결과'에는 '레이블과의 차이를 통해 계산된 손실'이 있음
손실값을 이용해 '역전파' 수행
역전파 결과값을 바탕으로 모델 업데이트 수행
# 예제 3.27. Trainer를 사용하지 않는 학습: (4) 평가를 위한 함수 정의
def evaluate(model, data_loader):
model.eval()
total_loss = 0
predictions = []
true_labels = []
with torch.no_grad():
for batch in tqdm(data_loader):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
logits = outputs.logits
loss = outputs.loss
total_loss += loss.item()
preds = torch.argmax(logits, dim=-1)
predictions.extend(preds.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
avg_loss = total_loss / len(data_loader)
accuracy = np.mean(np.array(predictions) == np.array(true_labels))
return avg_loss, accuracy모델 평가를 위한 함수
eval() 메서드
- 모델을 추론 모드로 변경
모델 계산 결과의 logits 속성에서 가장 큰 값으로 예측한 카테고리 정보 찾기
손실도/정확도 확인 가능
# 예제 3.28 Trainer를 사용하지 않는 학습: (5) 학습 수행
num_epochs = 1
optimizer = AdamW(model.parameters(), lr=5e-5)
# 학습 루프
for epoch in range(num_epochs):
print(f"Epoch {epoch+1}/{num_epochs}")
train_loss = train_epoch(model, train_dataloader, optimizer)
print(f"Training loss: {train_loss}")
valid_loss, valid_accuracy = evaluate(model, valid_dataloader)
print(f"Validation loss: {valid_loss}")
print(f"Validation accuracy: {valid_accuracy}")
# Testing
_, test_accuracy = evaluate(model, test_dataloader)
print(f"Test accuracy: {test_accuracy}") # 정확도 0.82정의한 학습 함수/ 성능 평가 함수로 학습 진행
- 에포크 수 1 설정
- AdamW 옵티마이저 사용
옵티마이저 (Optimizer)
신경망 학습에서 손실 함수(Loss Function)를 최소화하기 위해 모델의 가중치(Weights)와 편향(Biases)을 업데이트하는 알고리즘
주요 옵티마이저 알고리즘:
- SGD (Stochastic Gradient Descent): 기초적인 경사 하강법으로, 데이터의 일부(배치)를 이용해 가중치를 갱신
- Adam (Adaptive Moment Estimation): SGD의 확장 버전으로, 학습률을 자동으로 조정하며, 빠르고 안정적인 수렴을 제공
- RMSProp, Adagrad: 학습률을 데이터의 스케일에 따라 조정하는 방법들
에포크 (Epoch)
에포크는 신경망이 훈련 데이터를 한 번 모두 사용하여 학습을 완료하는 주기
- 데이터셋이 크면 한 번에 모든 데이터를 사용하기 어려워 미니배치(Mini-batch)로 나누어 학습하며, 배치를 여러 번 반복하는 것이 에포크 하나를 구성
예: 데이터셋이 10,000개이고 배치 크기가 100이라면, 한 에포크는 100번의 배치 업데이트로 구성
역전파 (Backpropagation)
오차를 신경망의 입력 방향으로 전파하며 가중치를 업데이트하는 알고리즘
- 순전파(Forward Propagation): 입력 데이터를 신경망의 각 계층을 통과시켜 출력값을 계산
- 역전파: 출력값과 목표값(라벨) 사이의 오차를 계산하여, 이 오차가 네트워크를 거꾸로 전파되면서 가중치를 조정
배치(Batch)
딥러닝과 머신러닝에서 모델 학습 시 데이터를 처리하는 단위
데이터셋이 너무 크거나 연산량이 많아 한 번에 전체 데이터를 처리하기 어려운 경우, 데이터를 작은 그룹(배치)으로 나누어 처리
⚗️ 학습한 모델 업로드하기
공유와 협업을 위해
허깅페이스 허브에 모델 업로드
User access tokens
Collaborate on models, datasets and Spaces
huggingface.co
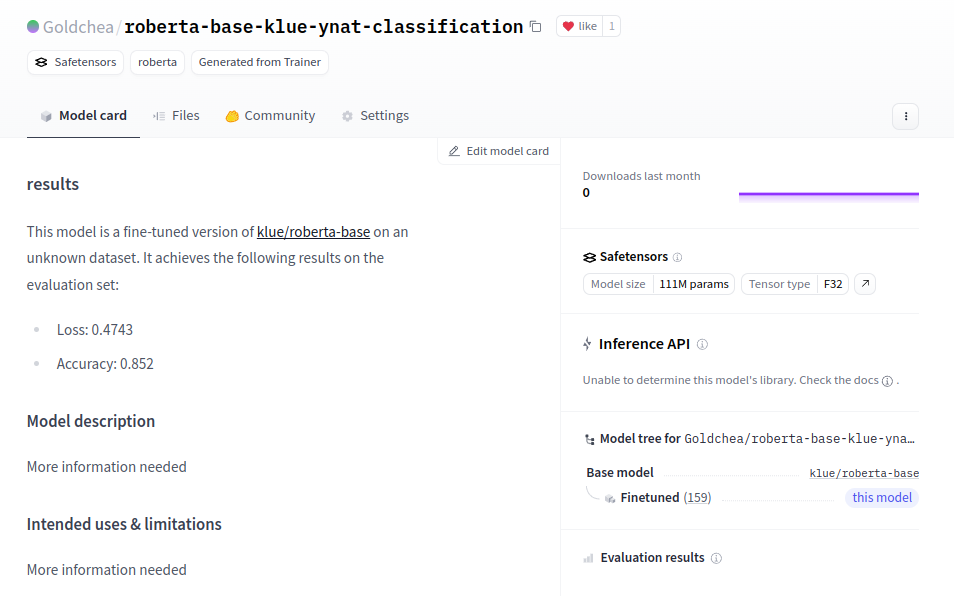
Goldchea/roberta-base-klue-ynat-classification · Hugging Face
results This model is a fine-tuned version of klue/roberta-base on an unknown dataset. It achieves the following results on the evaluation set: Loss: 0.4743 Accuracy: 0.852 Model description More information needed Intended uses & limitations More informat
huggingface.co
업로드했당...!
'🤖 AI > AI' 카테고리의 다른 글
| 🔣 openai api 인자 : logprobs (0) | 2025.01.09 |
|---|---|
| 🔬트랜스포머 모델을 다루기 위한 허깅페이스 트랜스포머 라이브러리 3 (0) | 2025.01.07 |
| 🔬트랜스포머 모델을 다루기 위한 허깅페이스 트랜스포머 라이브러리 1 (0) | 2025.01.06 |
| 🔬LLM의 중추, 트랜스포머 아키텍처 살펴보기 1 (0) | 2025.01.06 |
| Prompt caching : input_cached_tokens 🪙 (0) | 2025.01.03 |

