LLM을 활용한 실전 AI 애플리케이션 개발
- 허정준
🪧문장 임베딩 방식
텍스트 활용 시 단어보다는 문장을 많이 사용함
🫔 문장 사이의 관계를 계산하는 두 가지 방법
Bert 모델
- 트랜스포머 인코더 구조 사용
=> 입력 문장을 문장 임베딩으로 만드는 데 뛰어난 성능을 보임
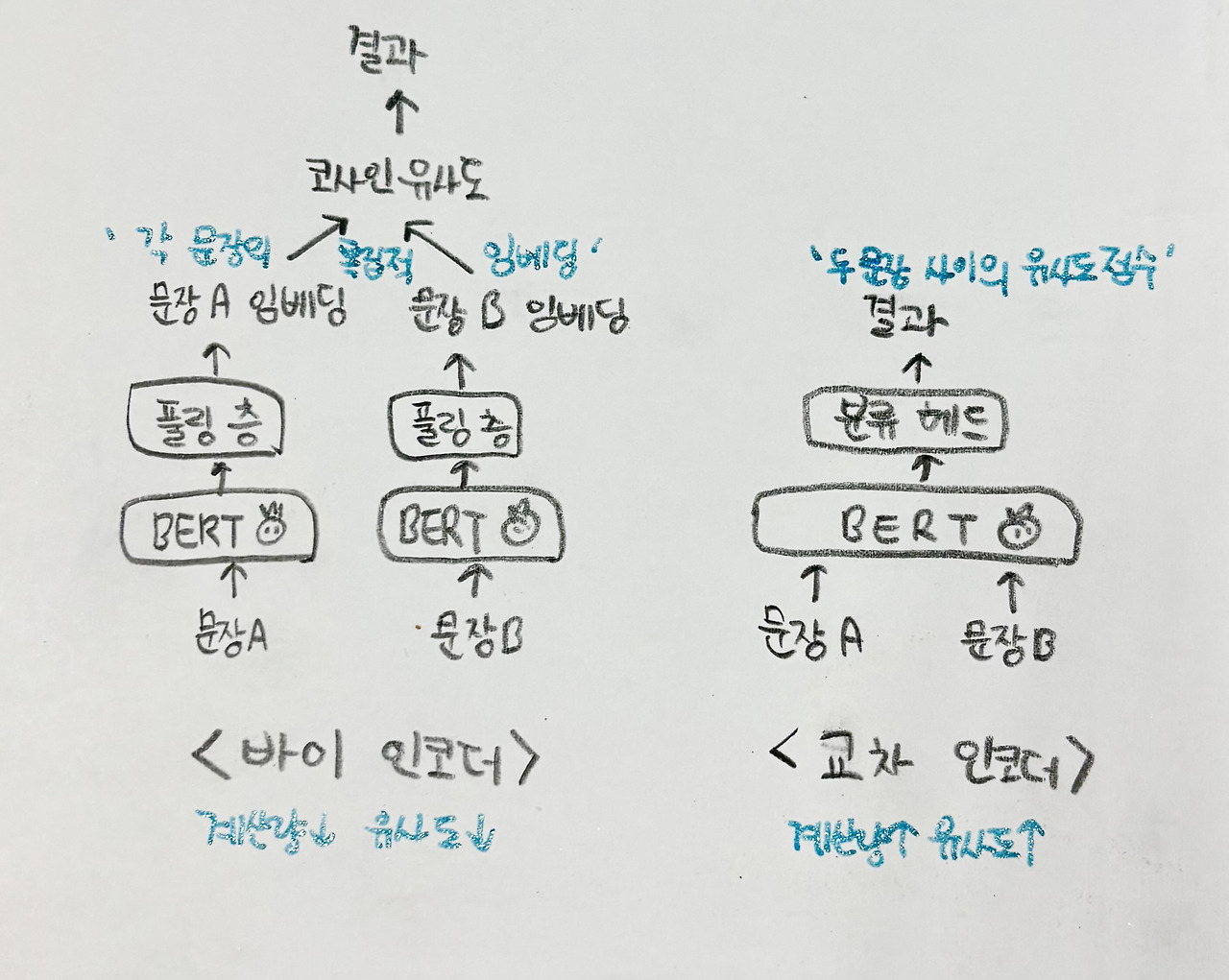
< Bert 모델을 활용하여 문장 사이의 관게를 계산하는 두 가지 방법>
1. 바이 인코더 bi-encoder
- 문장 두 개를 각각 bert 모델에 입력
- 모델의 출력 결과 (문장 임베딩 벡터) 사이의 유사도를 코사인 유사도를 통해 구함
2. 교차 인코더 Cross-encoder
- 문장 두 개를 함께 bert 모델에 입력
- 모델이 두 문장 사이의 관계를 출력

교차 인코더
=> 계산량이 많지만 두 문장의 상호작용을 고려할 수 있어 더 정확한 관계 예측이 가능
- 직접적으로 두 텍스트 사이의 관계를 모두 게산하기 때문에 정확한 유사도 계산이 가능하지만,
- Bert 트랜스포머 모델의 무거운 어텐션 연산을 모든 문장의 쌍에 대해 진행해야 하기 때문에 계산량 문제 있음..
=>
그래서 문장을 각각 모델에 입력하는 바이 인코더 방식 개발
ex) 1000개의 문서에 대한 관계를 모두 알고 싶음
교차 인코더 : 1000C2(조합) 499500번의 BERT 연산
바이 인코더 : 1000번의 BERT 연산
🫔 바이 인코더 모델 구조
< 진행 로직 >
1. 텍스트 입력
2. Bert 모델 연산 처리
3. 문맥이 반영된 단어 임베딩들 출력 (Bert 모델은 입력하는 토큰마다 각각 출력 임베딩을 생성)
4. 풀링 층을 통과하여 여러 단어 임베딩들을 하나의 임베딩으로 통합 ( 문장의 길이가 다르면 유사도 계산이 쉽지 않으므로 )
이후 코사인 유사도 등을 이용하여 두 문장 사이의 임베딩 거리 계산
< SentenceTransformer 라이브러리를 이용해서 바이 인코더 사용하기 >
from sentence_transformers import SentenceTransformer, models
# 사용할 BERT 모델
word_embedding_model = models.Transformer('klue/roberta-base')
# 풀링 층 차원 입력하기
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
# 두 모듈 결합하기
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])- klue/roberta-base에서 모델 가져오기
- Pooling 클래스로 풀링 층 생성하기
get_word_embedding_dimension() 메서드로 입력으로 들어오는 토큰 임베딩의 차원을 알려줌 - SentenceTransformer 클래스에 모듈로 언어 모델과 풀링 층을 입력해서 바이 인코더를 생성
< 3가지 풀링 모드 >
- 클래스 모드 (pooling_mode_cls_tokens)
Bert 모델의 첫 번째 토큰인 [CLS] 토큰의 출력 임베딩을 문장 임베딩으로 사용 - 평균 모드 (pooling_mode_mean_tokens)
Bert 모델에서 모든 입력 토큰의 출력 임베딩을 평균한 값을 문장 임베딩으로 사용 - 최대 모드 (pooling_mode_max_tokens)
Bert 모델에서 모든 입력 토큰의 출력 임베딩에서 문장 길이 방향 최댓값을 문장 임베딩으로 사용
🫔 sentence-Transformers로 텍스트와 이미지 임베딩 생성해 보기
예제 10.6 한국어 문장 임베딩 모델로 입력 문장 사이의 유사도 계산
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('snunlp/KR-SBERT-V40K-klueNLI-augSTS')
embs = model.encode(['잠이 안 옵니다',
'졸음이 옵니다',
'기차가 옵니다'])
cos_scores = util.cos_sim(embs, embs)
print(cos_scores)
# tensor([[1.0000, 0.6410, 0.1887],
# [0.6410, 1.0000, 0.2730],
# [0.1887, 0.2730, 1.0000]])
snunlp/KR-SBERT-V40K-klueNLI-augSTS · Hugging Face
snunlp/KR-SBERT-V40K-klueNLI-augSTS This is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search. Usage (Sentence-Transformers) Using this model b
huggingface.co
- 한국어 문장 임베딩 모델 snunlp/KR-SBERT-V40K-klueNLI-augSTS
- util.cos_sim으로 문장 사이의 코사인 유사도 계산
문장 사이의 유사도를 확인 가능 (1-0)
예제 10.7 CLIP 모델을 활용한 이미지와 텍스트 임베딩 유사도 계산
from PIL import Image
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('clip-ViT-B-32')
img_embs = model.encode([Image.open('dog.jpg'), Image.open('cat.jpg')])
text_embs = model.encode(['A dog on grass', 'Brown cat on yellow background'])
cos_scores = util.cos_sim(img_embs, text_embs)
print(cos_scores)
# tensor([[0.2771, 0.1509],
# [0.2071, 0.3180]])이미지도 가능!!
sentence-transformers/clip-ViT-B-32-multilingual-v1 · Hugging Face
sentence-transformers/clip-ViT-B-32-multilingual-v1 This is a multi-lingual version of the OpenAI CLIP-ViT-B32 model. You can map text (in 50+ languages) and images to a common dense vector space such that images and the matching texts are close. This mode
huggingface.co
- clip-ViT-B-32 모델 : OpenAI가 개발한 텍스트-이미지 멀티 모달 모델
이미지와 텍스트의 임베딩을 동일한 벡터 공간의 임베딩으로 변환함 (서로 유사도 계산 가능)
🫔 오픈소스와 상업용 임베딩 모델 비교하기
대표적 오픈소스 임베딩 모델 : Sentence-Transformers 라이브러리를 이용한 사전 학습 모델들 사용
대표적 상업용 임베딩 모델 : OpenAI의 text-embedding-ada-002 모델
| 오픈소스 임베딩 모델 | 상업용 임베딩 모델 | |
| 장 | - 무료 - 자신의 데이터에 특화된 임베딩 모델로 파인튜닝 가능 |
- 성능이 좋다 |
| 단 | - 성능이 떨어진다 | - 유료 (하지만 언어 모델에 비해서는 1/10가격) - 파인튜닝 기능 제공하지 않음 |
'🤖 AI > AI' 카테고리의 다른 글
| 🔬임베딩 모델로 데이터 의미 압축하기 : 검색 방식 조합/ 하이브리드 검색 (0) | 2025.01.20 |
|---|---|
| 🔬임베딩 모델로 데이터 의미 압축하기 : 의미 검색 구현 (0) | 2025.01.20 |
| 🔬임베딩 모델로 데이터 의미 압축하기 : 텍스트 임베딩 (0) | 2025.01.17 |
| 🔬LLM 어플리케이션 개발하기 : 데이터 로깅 (0) | 2025.01.16 |
| 🔬LLM 어플리케이션 개발하기 : 데이터 검증 (0) | 2025.01.16 |


