🎞컬렉션 프레임워크🎞
java.until.*에서 제공하는 미리 구현한 자료 구조 라이브러리
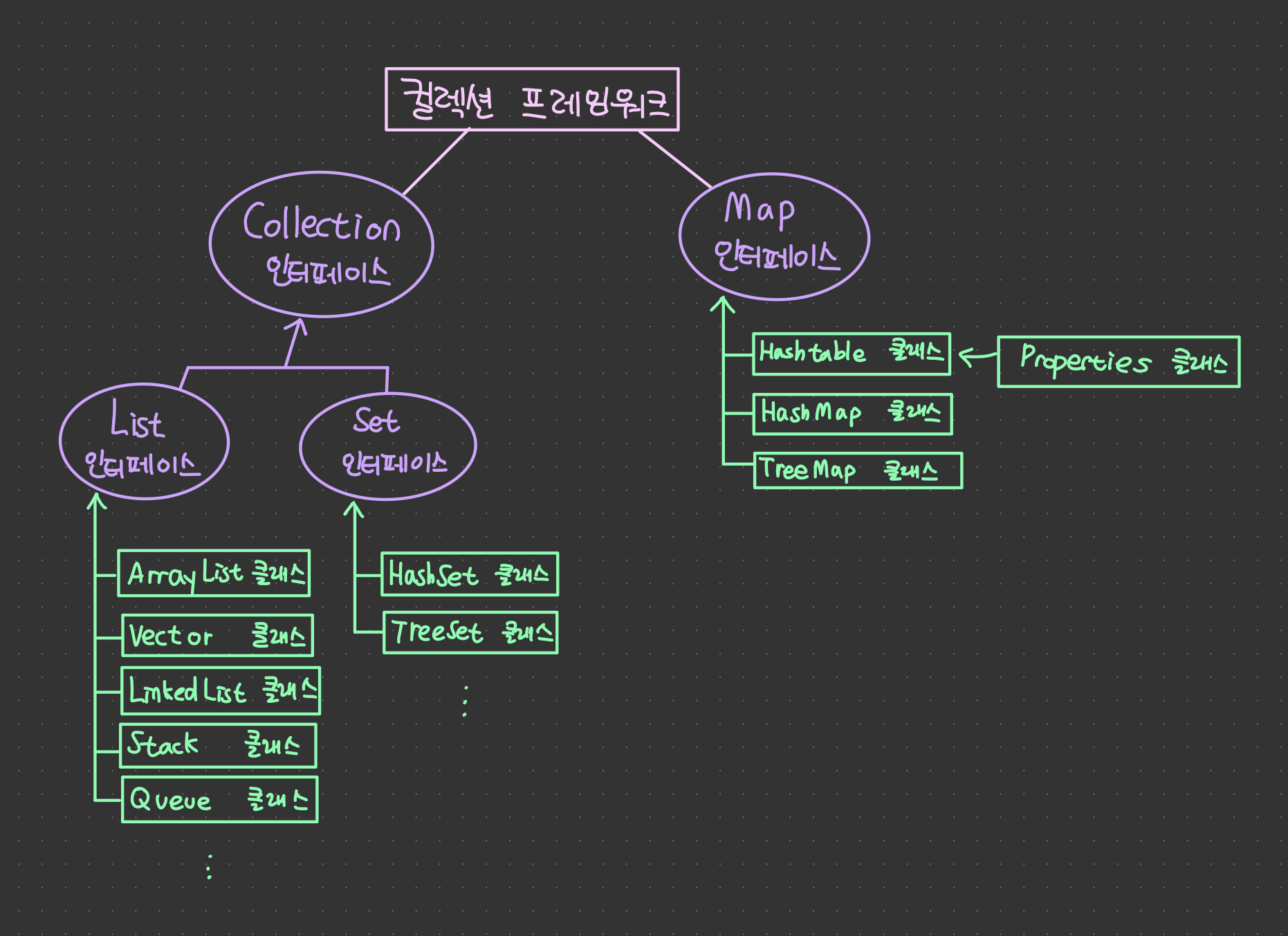
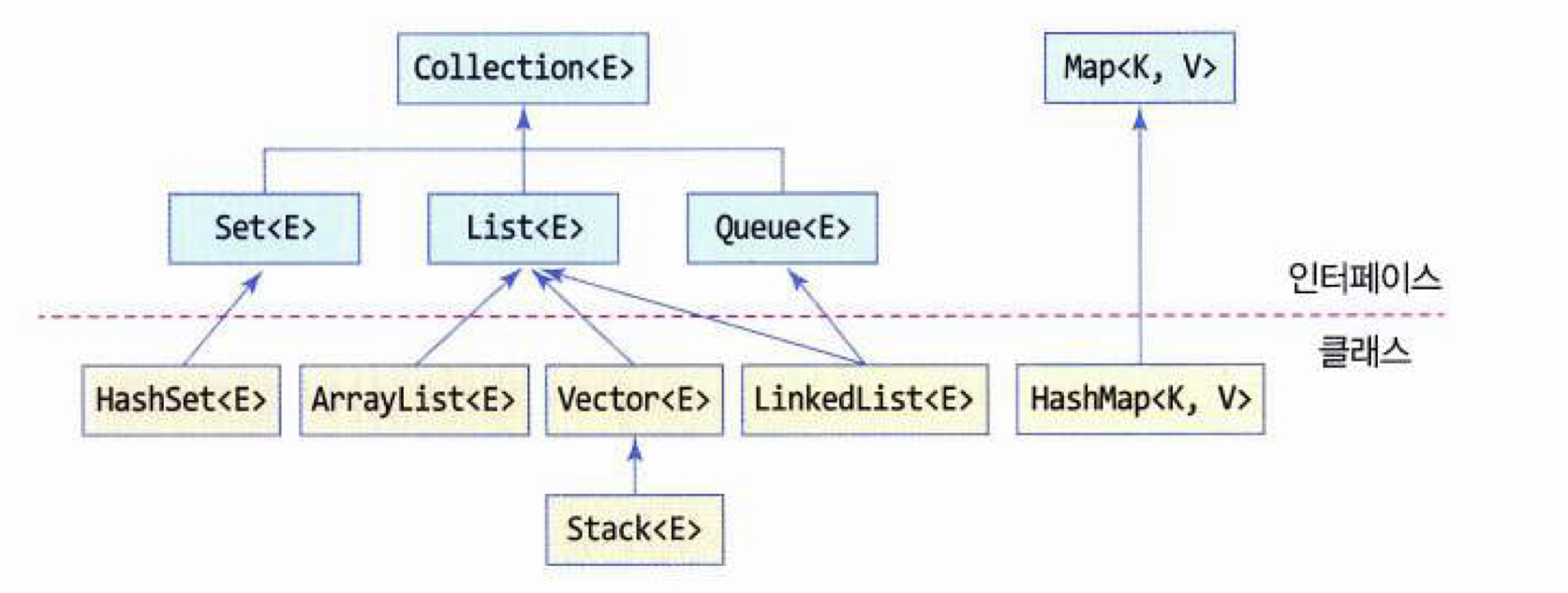
컬렉션 프레임워크 = Collection 인터페이스 + Map 인터페이스
🎞Collections 클래스
메소드들은 모두 Static 타입
sort()
reverse()
max(),min()
binarySearch()
🎞Collection 인터페이스🎞
하나의 자료를 모아서 관리하는 데 필요한 기능 제공
🎞Collection 인터페이스의 메서드
| boolean add(E e) | 컬렉션에 객체를 추가. |
| void clear() | 컬렉션의 모든 객체 제거 |
| Iterator<E> iterator | 컬렉션을 순환할 반복자 반환 |
| boolean remove(Object o) | 컬렉션에 매개변수에 해당하는 인스턴스가 존재할 시 제거 |
| int size() | 컬렉션에 있는 요소의 개수 반환 |
Collection 인터페이스 = List 인터페이스 + Set 인터페이스
🖼List 인터페이스🚶♀️
객체를 순서에 따라 저장하고 유지 / 순차 자료 구조
💥ArrayList 클래스
💕자바 ArrayList 클래스💕
junggoldchae-coding.tistory.com
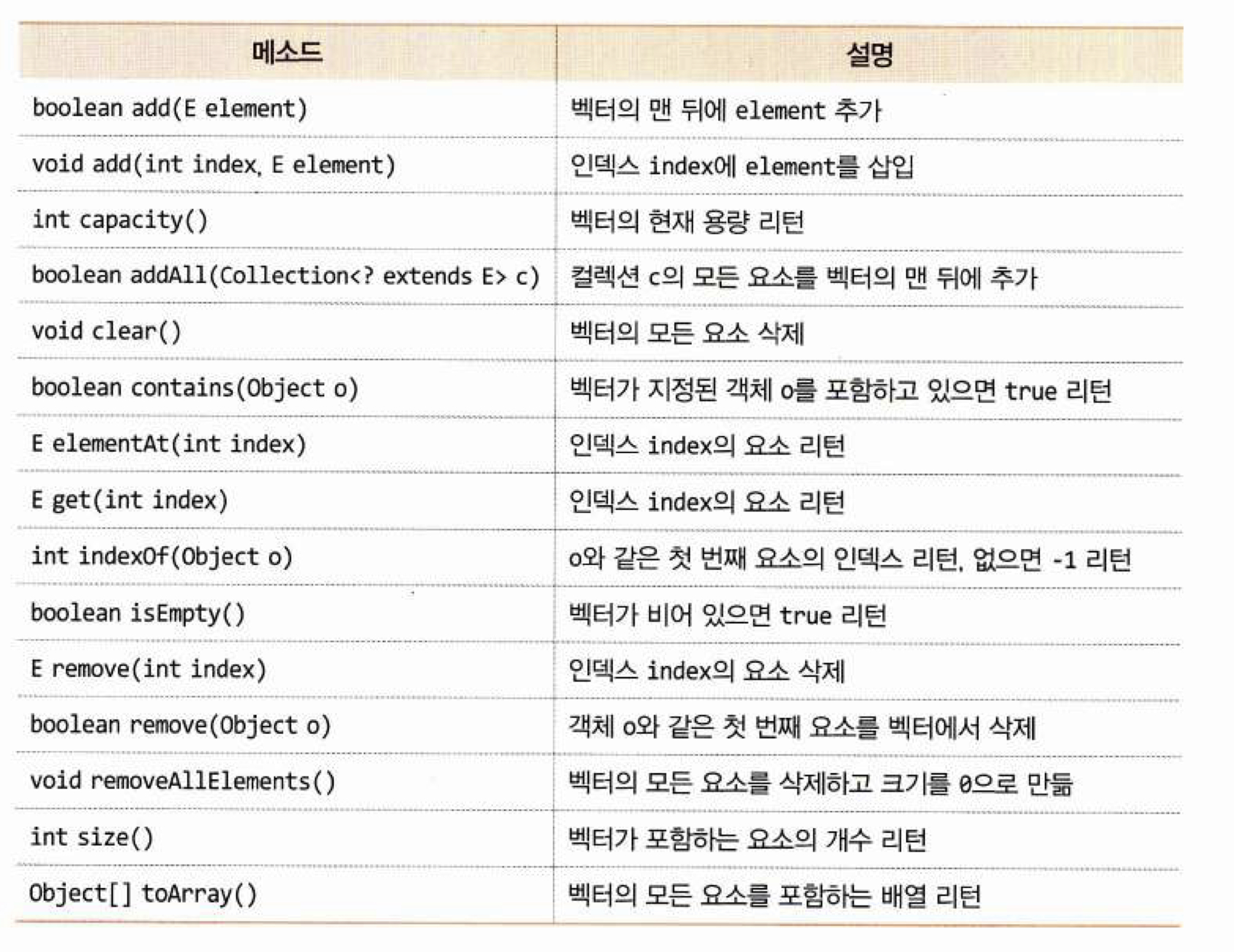
벡터와는 달리 현재 용량을 알려주는 메소드 없음
💥Vector 클래스
가변 크기 지원! 객체의 삽입,삭제,이동 쉬움
ArrayList 클래스와는 다르게 동기화를 지원
동기화 : 멀티 스레드 실행 시 메모리에 동시 접근하지 못하도록 순서를 맞추는 것. 메서드 호출 시 잠금, 끝나면 해제하는 식으로 작동
따라서 ArrayList보다 수행 속도가 느림
+ vector 사용 대신 synchronized 사용 가능
//1
Vector<Integer> v = new Vector<Integer>(용량);
//2
Vector<Integer> v;
v = new Vector<Integer>();() 안에 숫자를 넣어 초기 용량을 정할 수 있음
+ null도 add 가능!
+ 크기보다 큰 요소에 add하면 예외발생
+
벡터의 크기 == 벡터에 들어 있는 요소 개수. size()
벡터의 용량 == 벡터가 수용할 수 있는 크기. capacity()
+
remove() 벡터 요소 삭제
+
컬렉션은 객체들만 요소로 다룸!!
v.add(Integer.valueof(4));
v.add(4); // 자동 박싱됨
int k = v.get(0) //자동 언박싱💥LinkedList 클래스
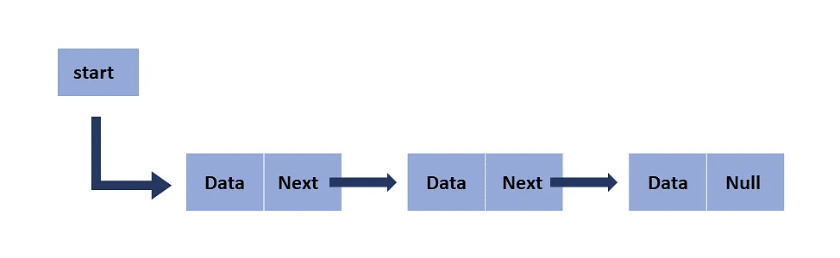
각 요소가 다음 요소를 가리키는 주소 값을 가짐
요소들을 양방향으로 연결하여 관리함
| 배열 | LinkedList |
| - 메모리의 물리적 순서 = 논리적 순서 - 자료 추가/ 제거 시 연속된 자료 구조 구현 - 크기 증가 시 다른 큰 배열 생성 후 복사시킴 - 탐색에는 물리적으로 구조가 연결되어 있어 빠름 |
- 물리적인 메모리는 떨어져 있지만 논리적 앞뒤 순서 존재 - 자료를 추가/ 제거하는 데 시간이 적게 걸림(메모리만 변경, 가비지 콜렉터가 수집) - 크기를 동적으로 증가시킬 수 있음 -탐색은 비교적 느림 |
따라서 자료의 변동(추가,삭제) 가 많은 경우에는 LinkedList,
적은 경우에는 배열 쓰기.
🖼Set 인터페이스🚶♀️
중복을 허용하지 않는 "집합"
순서도 존재하지 않음
💥Hash 클래스
//import java.util.hashset; 임포트
HashSet<String> hashset = new HashSet<String>();동일한 객체는 중복저장되지 않음
=> 동일함에 대한 정의가 새로 필요할 경우엔 해주어야 함( ex 회원아이디가 같으면 같은 것 )
=> equals() 와 hashCode() 메서드를 재정의하기!
💥TreeSet 클래스
Tree로 시작하는 클래스들(컬렉션 프레임워크 중)은 결과 출력 시 결과 값이 정렬됨
// import java.util.TreeSet;
TreeSet<String> treeSet = new TreeSet<String>();자바는 정렬할 때 "이진 트리"를 씀
어떤 기준으로 노드를 비교하여 트리를 형성해야 하는가?
=>
☄️Comparable 인터페이스 / Comparator 인터페이스 이용하기
정렬을 구현할 수 있게 해 주는 인터페이스
정렬 기준 값이 있는 클래스에 상속시킴
public class 클래스 implements Comparable<T>{...}각각 compareTo() / compare(인자 2개) 추상메서드를 재정의
=> 리턴값의 차이로 비교함
(내림차순 정렬 시 리턴값에 -1 곱해주면 됨!)
이때 사용할 TreeSet 클래스의 생성자에 Comparable를 구현한 객체를 매개변수로 전달해야 함
💥Iterator
순서가 없는 클래스에서 요소 순회 등을 할 때 사용
Iterator ir = 자료구조.iterator();| boolean hasNext() | 이후에 요소가 더 있는지 체크 |
| E next() | 다음에 있는 요소 반환 |
활용
while (ir.hasNext(){
// ir.next() 를 이용한 코드
}🎞Map 인터페이스🎞
쌍( key - value 쌍) 으로 된 자료들을 관리하는 데 유용한 기능 제공 (검색용 자료구조)
key 값은 중복 불가
value 값은 중복 가능
🎞Map 인터페이스의 메서드
| V put( k key, V value) | 키값에 해당하는 밸류값을 맵에 넣습니다. |
| V get(K key) | 키에 해당하는 밸류값을 반환합니다 |
| boolean isEmpty | 맵이 비었는지 여부를 파악합니다 |
| boolean constainsKey(Object key) | 맵에 해당 키가 있는지 여부를 반환합니다 |
| boolean constainsValue(Object value) | 맵에 해당 밸류가 있는지 여부를 반환합니다. |
| Set keyset | 키 집합을 셋으로 반환합니다 |
| Collection values | 밸류를 컬렉션으로 반환합니다 |
| V remove(key) | 키가 있는 경우 삭제합니다 |
| boolean remove(Object key, Object value) | 키가 있는 경우 키에 해당하는 밸류가 매개변수와 일치할 때 삭제합니다. |
💥HashMap 클래스
// import java.util.HashMap
public HashMap<Integer, String> hashmap = new HashMap<Integer, String>;
hashmap.put(1, "hamster");put(키,값), get(키)
- 요소의 삽입 삭제가 매우 빠름
- 요소 검색은 더욱 빠름
- 없는 키값 get하면 null 반환
- keySet() 모든 키를 컬렉션으로 만들어 리턴! (이후 Iterator로 뽑아보기)
💥HashTable 클래스
멀티스레드를 위한 동기화 제공
💥TreeMap 클래스
TreeSet 클래스 와 유사!
+
❓배열 용량(capacity)
size()(유효한 값이 저장된 크기)와는 다르다.
Arraylist() 기본 크기는 10개
용량 부족 시( add(), insert() 사용) 큰 용량의 배열 생성 후 복사함
❓스레드
=작업 단위
하나의 스레드 수행 => 단일 스레드
두개 이상의 스레드 수행. => 멀티 스레드
멀티스레드 수행 시 같은 메모리 공간에 접근하기 때문에 오류가 생길 수 있음
❓가비지 콜렉터
프로그램이 동적으로 할당했던 메모리 영역 중에서 필요없게 된 영역을 해제하는 기능
❓해시 테이블
해시 방식의 자료를 저장하는 공간
'💾 Backend > 자바' 카테고리의 다른 글
| 💕자바 탐구 - 배틀게임 제작💕 (2) | 2023.05.28 |
|---|---|
| 💗자바 ArrayList 클래스💗 (1) | 2023.05.26 |
| 💖자바 제네릭💖 (2) | 2023.05.19 |
| 💖자바 예외‼️ 처리💖 (0) | 2023.05.11 |
| 💕객체 지향 공부 - 시나리오 작성💕 (2) | 2023.05.09 |



