더이상물러날수없다
cd /usr/local/mysql/bin
🐋 MySQL 실행 실패
mysql
zsh: command not found: mysql
시스템의 PATH 환경 변수에 MySQL이 설치된 디렉토리가 포함되어 있지 않은 상태
- zsh 셸 설정 파일 열어서 PATH에 MySQL 추가하기
export PATH="/usr/local/mysql/bin:$PATH"
- 변경사항 적용하기
source ~/.zshrc
🐋 MySQL 로그인 실패
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
미치고 팔짝
팔짝팔짝
얘 왜 계속 이 에러떠요
sql삭제하고 다시깔았는데도
팔짝팔짝
- MySQL 서버 상태 확인
brew services list
mysql none
없는거
mysql started ~
실행중인거
brew services start mysql
실행하기!
바꾸기
유저네임: Goldchae
비번: 컴비번
드디어!

FLUSH PRIVILEGES;
ALTER USER 'root'@'localhost' IDENTIFIED BY 'celina324';
🐬 SQL
<SQL 실행>
brew services start mysql
<SQL 종료>
brew services stop mysql
<SQL 접속>
mysql -u root -p
mysql -u Goldchae -p
Goldchae 유저에게는 권한이 없는 상태..나중에 줘 보자
< 종료>
exit;
🐬 데이터베이스
<데이터베이스 생성>
create database {데이터베이스명};
<데이터베이스 보기>
show databases;
information_schema
MySQL 서버의 메타데이터를 저장
테이블, 컬럼, 데이터 타입, 액세스 권한 등 데이터베이스 구조에 대한 정보 포함
사용자가 직접 데이터를 추가하거나 변경할 수 없는 시스템 데이터베이스
mysql
MySQL 서버의 사용자 계정, 권한, 플러그인 등을 관리하는 정보가 저장된 시스템 데이터베이스
MySQL 설치와 운영에 필수적인 정보 포함
performance_schema
MySQL 서버의 성능 모니터링에 사용되는 데이터를 저장하는 시스템 데이터베이스
실행 중인 쿼리, 리소스 사용량 등의 정보를 포함하며, 데이터베이스 성능 분석과 최적화에 도움을 줌
sys
performance_schema의 데이터를 기반으로 보다 쉽게 성능 분석과 문제 진단을 할 수 있도록 포맷된 뷰(view)와 프로시저를 제공하는 데이터베이스
performance_schema에 저장된 정보를 사용자 친화적인 형태로 제공
testdb
내가 만든 사용자 정의 데이터베이스
<데이터베이스 선택>
use {데이터베이스명};

🐬 테이블
<테이블 생성 >
CREATE TABLE {테이블이름}
( {내부 설정들..} );

<전체 테이블 목록 보기>
show tables;
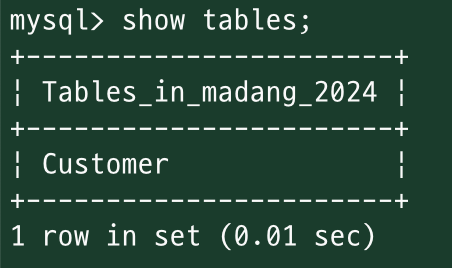
<하나 테이블 스키마 보기>
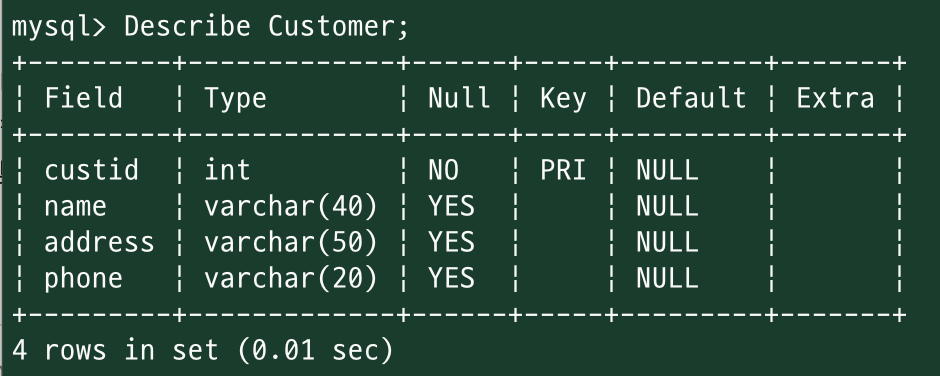
Describe {테이블명};
< 테이블의 스키마,튜플들 보기>
Select * from {테이블명};
+
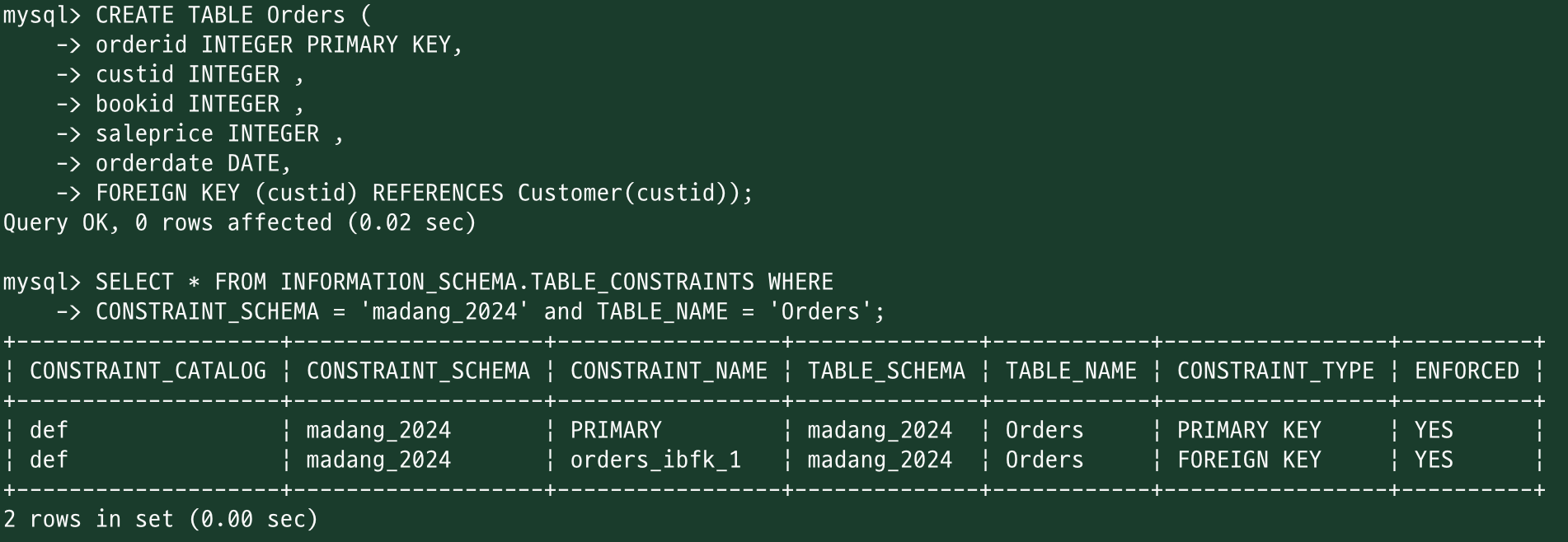
INFORMATION_SCHEMA 데이터베이스의 TABLE_CONSTRAINTS 테이블에서 특정 조건을 만족하는 데이터를 조회하기
SELECT *
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS
WHERE CONSTRAINT_SCHEMA = '{스키마(또는 데이터베이스)}' and TABLE_NAME = '{테이블}';
특정 {스키마(또는 데이터베이스)}에서 특정 {테이블}에 설정된 제약 조건을 찾고 있습니다.
결과를 보면 Customer 테이블에는 PRIMARY KEY 제약 조건이 설정되어 있음을 알 수 있습니다.
- CONSTRAINT_CATALOG: 제약 조건이 정의된 데이터베이스 서버의 카탈로그 / 표준 SQL에서는 def로 표시
- CONSTRAINT_SCHEMA: 제약 조건이 정의된 데이터베이스의 이름
- CONSTRAINT_NAME: 제약 조건의 이름
- TABLE_SCHEMA: 제약 조건이 적용된 테이블이 있는 데이터베이스의 이름입니다.
- TABLE_NAME: 제약 조건이 적용된 테이블의 이름
- CONSTRAINT_TYPE: 제약 조건의 유형
- ENFORCED: 제약 조건이 데이터베이스에 의해 강제되고 있는지를 보여줌
+
외래키 있는 테이블 생성 / 확인
🐬 데이터 삽입

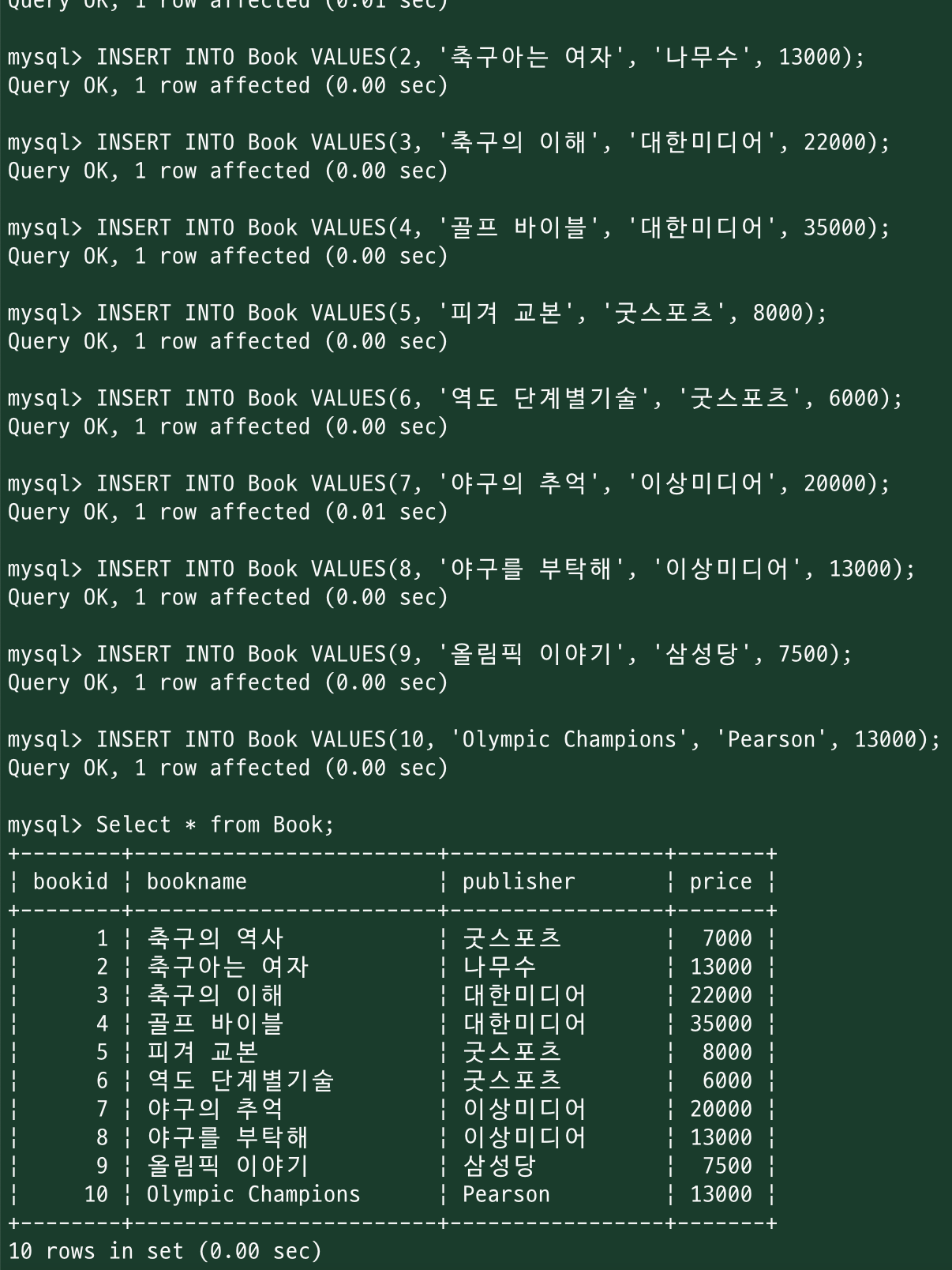
<튜플 삽입>
INSERT INTO {테이블명} VALUES({튜플내용});
+
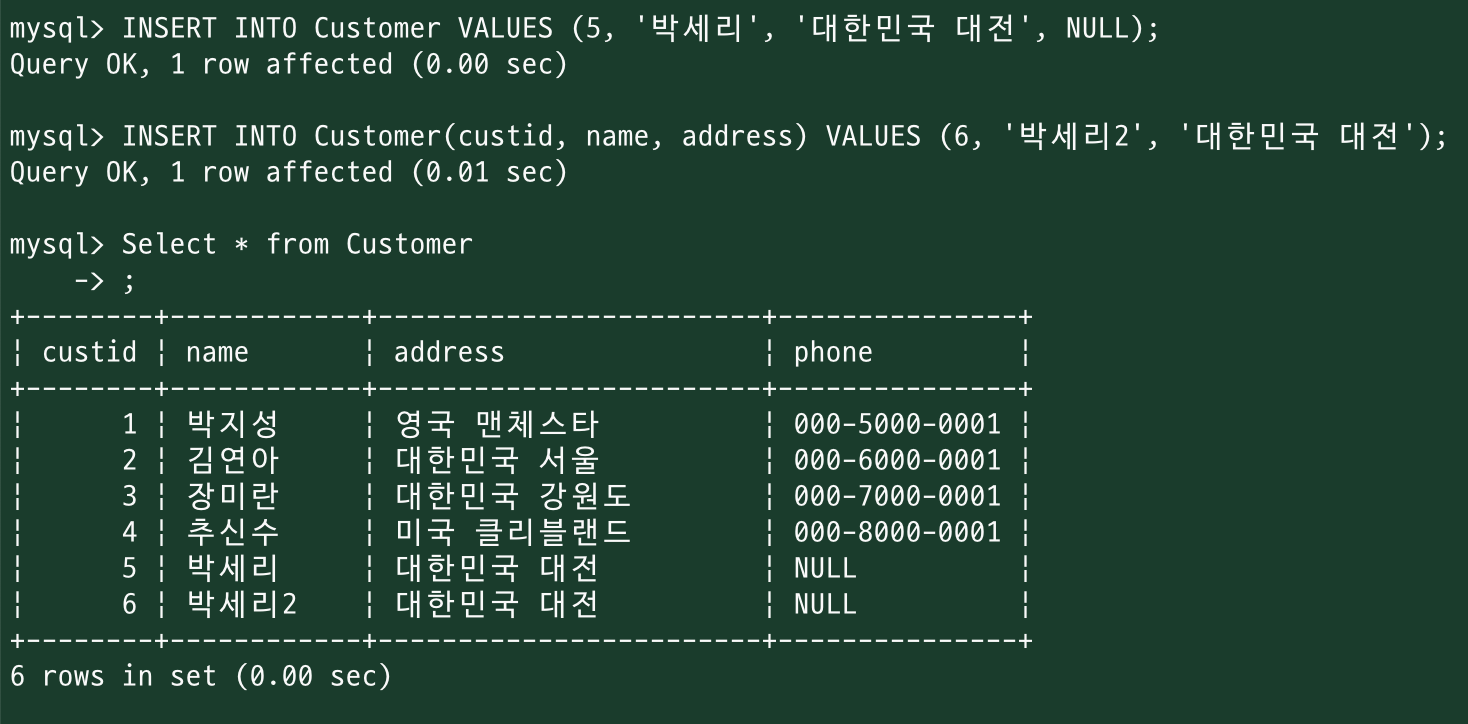
안 넣거나 / NuLL 할당하면 => NULL 로 들어감
+
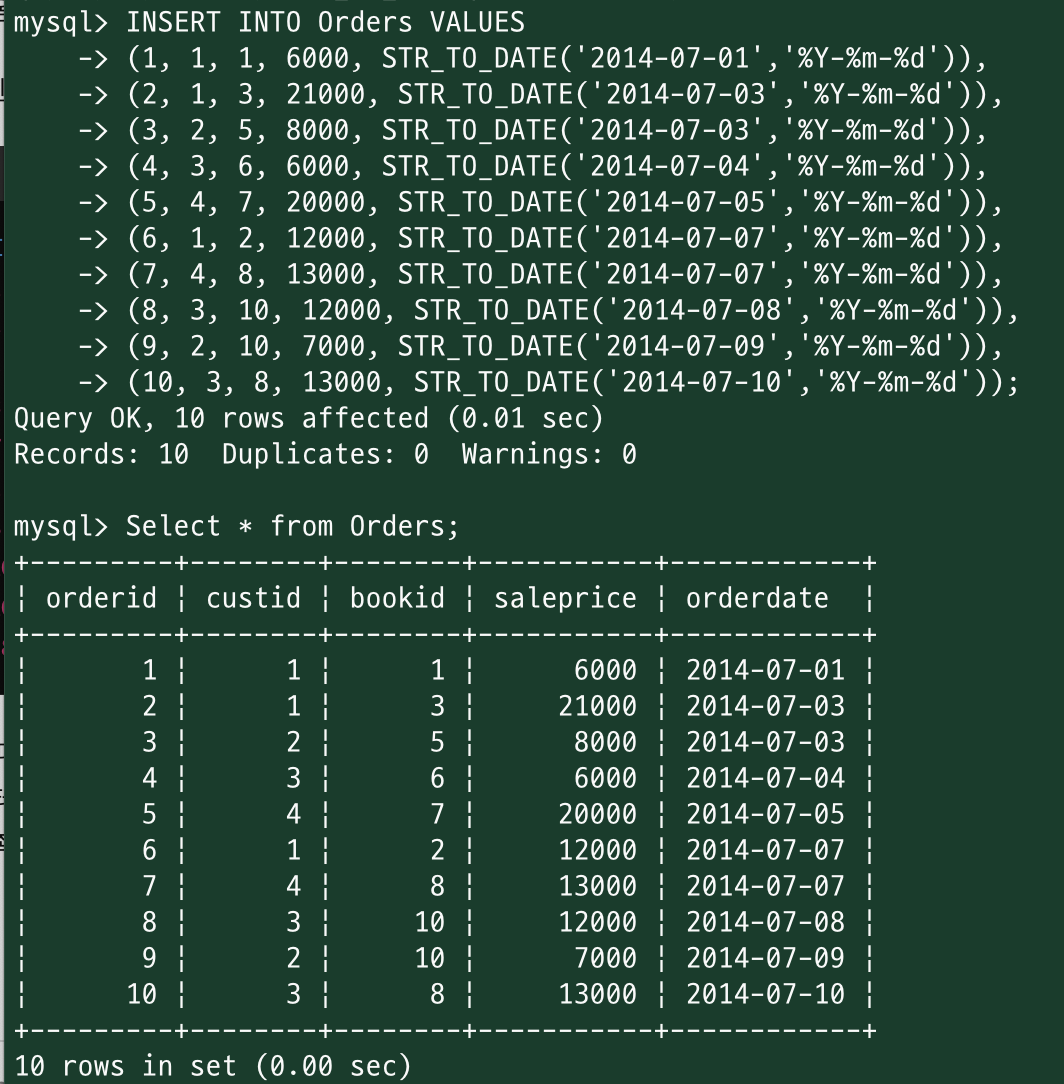
"INSERT INTO {테이블명} VALUES" 매 튜플 앞에 붙여도 되고, 한번만 하고 뒤에 튜플 좌라락 해도 됨
+
<테이블에 제약 조건을 추가하기>
외래 키 제약조건 추가
ALTER TABLE {테이블명}
ADD CONSTRAINT {상수명}
FOREIGN KEY ({속성이름}) REFERENCES {참조테이블명}({참조테이블의 참조속성명});
🐬 데이터 검색
SELECT {속성명}
FROM {테이블명}
WHERE {조건};
기본
<하나의 속성 보기>
SELECT {속성명}
FROM {테이블명};
중복 삭제
SELECT DISTINCT {속성명}
FROM {테이블명};

<속성에 조건 달아서 튜플 보기>
SELECT {속성명}
FROM {테이블명}
WHERE {조건};
* 는 전부 선택

조건 예시 )
가격 20000원 이상 - price < 20000
제목에 "포함되어야하는말" 포함 - bookname LIKE '%포함되어야하는말%';
+
<GROUP BY>
SELECT COUNT(*) AS {속성이름1}, SUM({합치기연산할 컬럼명}) AS {속성이름2}
FROM {테이블명}
GROUP BY {그룹지을 컬럼명};
- COUNT(*) AS {{속성이름}}:
COUNT(*)는 GROUP된 그룹의 모든 행(row)의 수를 계산
{{속성이름}} 이름으로 결과가 표시
- SUM({합치기연산할 컬럼명}) AS {속성이름}:
{컬럼명} 컬럼의 값들을 모두 합하는 함수
{{속성이름}} 이름으로 결과가 표시
- FROM {테이블명}:
쿼리가 조회될 테이블을 지정
- GROUP BY {그룹지을 컬럼명} :
결과를 {컬럼명} 컬럼의 값에 따라 그룹화
같은 {컬럼명} 값을 가진 행들이 하나의 그룹으로 묶여 COUNT(*)와 SUM(saleprice) 함수의 연산 대상이 됨
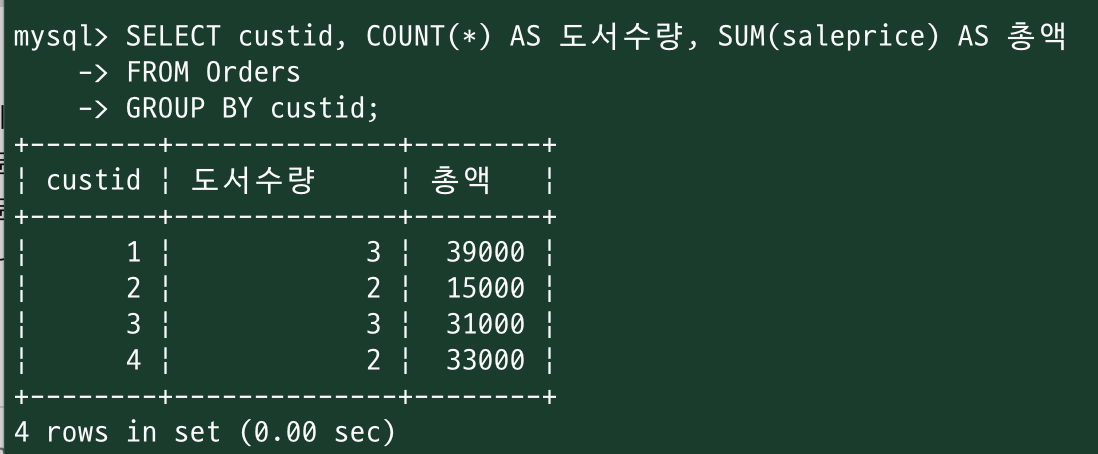
+
<HAVING>
SELECT {속성}, COUNT(*) AS {속성이름}
FROM {테이블명}
WHERE {조건}
GROUP BY {그룹지을 컬럼명};
HAVING {조건};
HAVING {조건}:
GROUP BY로 그룹화된 결과에 추가 조건을 적용
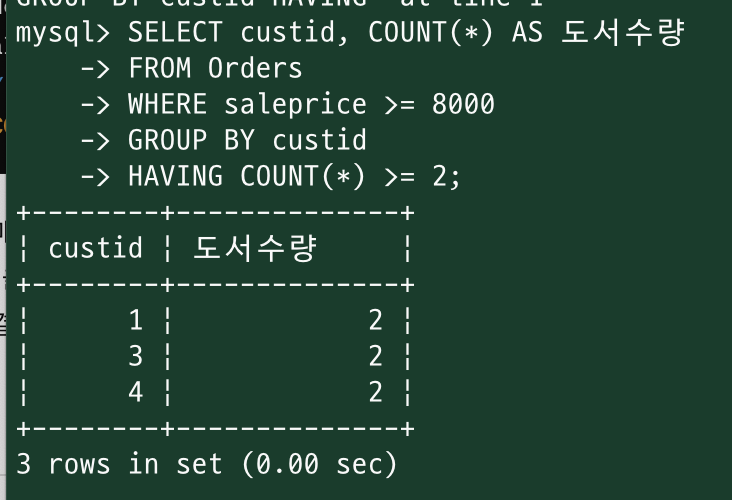
+
WHERE Customer.custid=0rders.custid AND Orders.bookid=Book.bookid AND Book-price=20000;
where절에 조건 AND 등 사용 가능
+
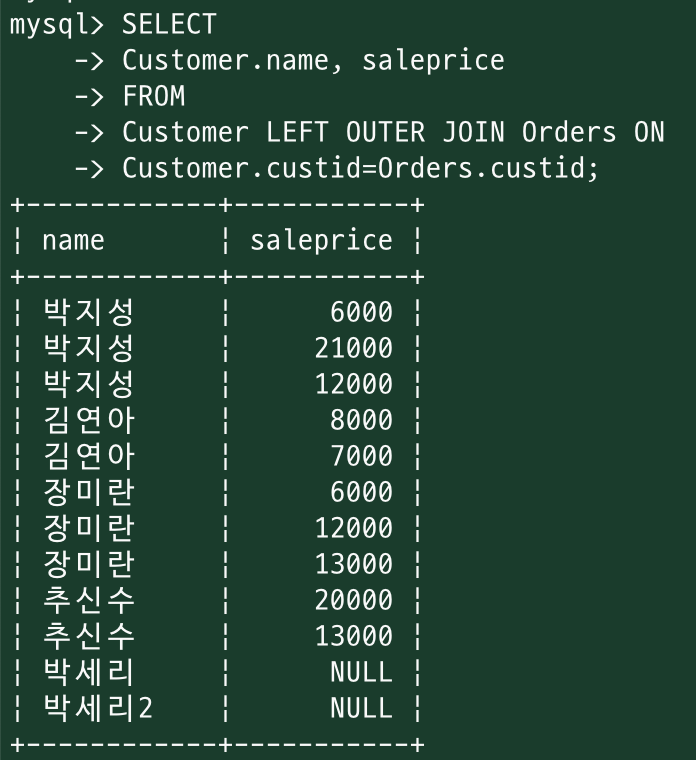
<LEFT OUTER JOIN>
SELECT {합친레코드에서 뽑을 칼럼}
FROM {왼쪽 테이블}
LEFT OUTER JOIN {오른쪽 테이블}
ON {두 테이블을 어떻게 결합할지 결정하는 조건};
LEFT OUTER JOIN
두 테이블을 결합
"왼쪽 테이블"의 모든 레코드와 "오른쪽 테이블"에서 일치하는 레코드를 반환
오른쪽 테이블에 일치하는 레코드가 없는 경우 : 결과에 왼쪽 테이블의 레코드가 포함/오른쪽 테이블의 열은 NULL
ON
JOIN 연산에서 두 테이블을 어떻게 결합할지 결정하는 조건을 명시
보통 두 테이블 사이에 공통적으로 존재하는 컬럼(또는 필드)의 값이 서로 일치하는 행끼리 결합하도록 지정
+
<IN>
SELECT {칼럼}
FROM
WHERE {조건}
IN {하위 쿼리};
IN
지정된 목록에 포함된 값 중 하나와 일치하는 데이터를 조회
하위 쿼리로부터 반환된 목록을 사용
하위 쿼리
(SELECT/ FROM...)문 사용

+
<이중 하위 쿼리>
SELECT name
FROM Customer
WHERE custid IN(
SELECT custid
FROM Orders
WHERE bookid IN(
SELECT bookid
FROM Book
WHERE publisher='대한미디어'));

+
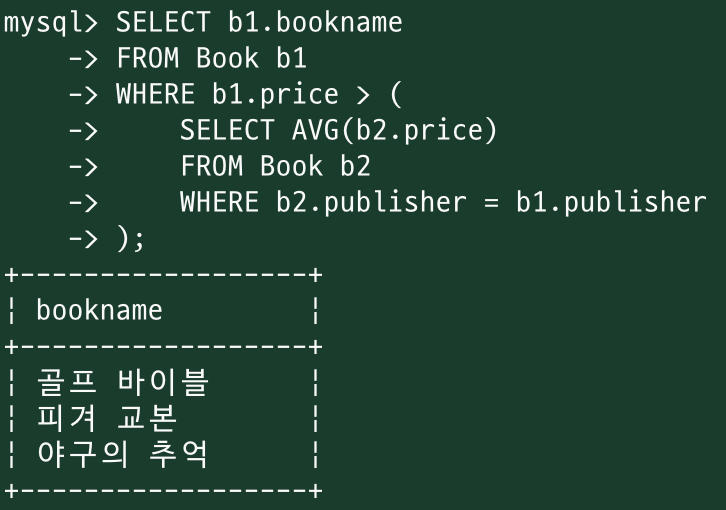
<변수사용>
SELECT b1.bookname
FROM Book b1
WHERE b1.price > ( SELECT AVG(b2.price)
FROM Book b2
WHERE b2.publisher = b1.publisher );
🐬 데이터 수정(변경)
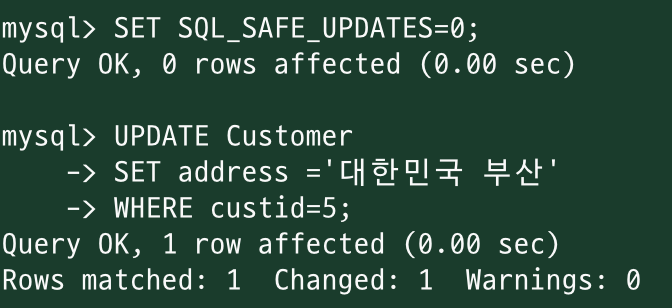
<안전 업데이트 모드 비활성화>
SET SQL_SAFE_UPDATES=0;
SET SQL_SAFE_UPDATES=0
MySQL에서 안전 업데이트 모드를 비활성화
SQL_SAFE_UPDATES 옵션이 활성화 시
- WHERE 절 없이 UPDATE나 DELETE 명령을 실행할 수 없게 하거나, WHERE 절이 KEY 컬럼을 참조하지 않는 경우 실행을 제한
- 실수로 많은 레코드를 변경하거나 삭제하는 것을 방지
SQL_SAFE_UPDATES 옵션이 비활성화 시 (0 설정)
유연한 데이터 조작이 가능
실수로 대량의 데이터를 변경하거나 삭제할 위험
( 수정 완료 후 다시 조건 바꾸기 => SET SQL_SAFE_UPDATES = 1 )
<데이터 변경>
UPDATE {업데이트할 테이블명}
SET {변경할 내용}
WHERE {변경할 요소 조건};


+
UPDATE Book
SET publisher = (SELECT publisher
FROM imported_book
WHERE bookid = 21)
WHERE bookid = 14;
SET 안에 또 구문 넣기 가능!
🐬 데이터 삭제
< 테이블 튜플 삭제>
DELETE FROM {테이블명}
WHERE {삭제할 요소 조건};

<테이블 삭제>
Drop table {테이블명}

<데이터베이스 삭제>
Drop table {데이터베이스명}
Workbench에서도 써봐야 한다
그거슨 내일


'💾 Backend > 데이터베이스' 카테고리의 다른 글
| 📊 데이터베이스(mySQL) - 3. SQL 기초 - DML:검색 (0) | 2024.04.24 |
|---|---|
| 📊 데이터베이스(mySQL) - 2. 관계 데이터 모델 - 관계대수 (0) | 2024.04.22 |
| 📊 데이터베이스(mySQL) - 2. 관계 데이터 모델 - 무결성 제약조건 (0) | 2024.04.22 |
| 📊 데이터베이스(mySQL) - 1. 데이터베이스 시스템 (0) | 2024.04.19 |
| 🐬 MySQL 써보기 (4) | 2024.03.27 |



