🪺 목표
- 신촌 구글 드라이브 문서 전부 rag로 던지기!!
+
- gpt - 3.5 터보 버전으로 테스트 / gpt 4로도 테스트해보기
- 창의성 등 LLM 세부사항 조정해보기
🪺 테스트 버전
🥚 문서 하나
우선 문서 하나를 고른다
흠..
"2024 겨울 신촌지역 대학교 프로그래밍 동아리 연합 후원 기획서"로 결정
files에 넣고,
🥚 로직 생각
- 이 파일을 가져와서
- split하고
- embedding하고
- 메모리 저장 (요금 방지)
- 모델 가져오고
- 프롬프트 만들고
- 체인 만들기
- 디스코드 연결
🥚 파일 가져오기
from langchain.document_loaders import UnstructuredFileLoader
loader = UnstructuredFileLoader("./files/chapter_one.txt")UnstructuredFileLoader : 다양한 파일 형식 지원
🥚 split : 문자열 쪼개기
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter.from_tiktoken_encoder(
separator="\n",
chunk_size=600,
chunk_overlap=100,
)줄바꿈 기준으로 쪼개기
문단 청크 600으로 쪼개기
잘리는 문맥이 발생하지 않게 앞 문단에서 100 정도 가져와서 붙임
로드된 문서 이 splitter로 자르기
docs = loader.load_and_split(text_splitter=splitter)🥚 메모리 저장
from langchain.storage import LocalFileStore
cache_dir = LocalFileStore("./.cache/")캐시 파일 생성
🥚 임베딩
from langchain.embeddings import OpenAIEmbeddings, CacheBackedEmbeddings
embeddings = OpenAIEmbeddings()
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(embeddings, cache_dir)임베딩 모듈 가져오고
캐시 저장소 연결
🥚 chroma
the AI-native open-source embedding database
the AI-native open-source embedding database
www.trychroma.com
임베딩 사용을 편리하게 만들어 주는 크로마
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(docs, cached_embeddings)쪼개진 문서와 임베딩해주는 애를 넘김!
🥚 모델 가져오기
from langchain.chat_models import ChatOpenAI
# 모델 가져오기
llm = ChatOpenAI(temperature = 0.1)일단 3.5 터보,
창의력 노노
🥚 체인 만들기
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(
llm=llm,
retriever = vectorstore.as_retriever(),
)RetrievalQA (Retrieval-Based Question Answering)
질문에 대한 답을 찾기 위해 관련 정보를 검색(retrieve)하여 활용하는 질문 답변 시스템의 한 형태
주어진 질문에 가장 적절한 답변을 생성하기 위해, 대규모의 데이터베이스나 문서 집합에서 관련 정보를 검색한 후, 그 정보를 기반으로 답변을 생성하거나 선택
Retriever
RetrievalQA (Retrieval-Based Question Answering) 시스템의 핵심 구성 요소
주어진 질문에 대한 정보를 찾기 위해 대량의 데이터 소스를 검색하는 역할
🥚 + gitignore
files랑 cache 추가
api 키랑 env
🥚 임시 개장 sinchonGPT!
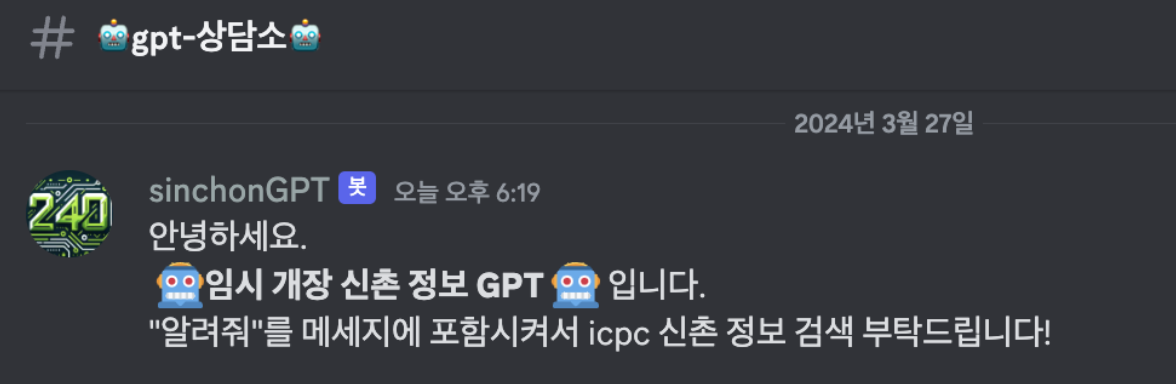
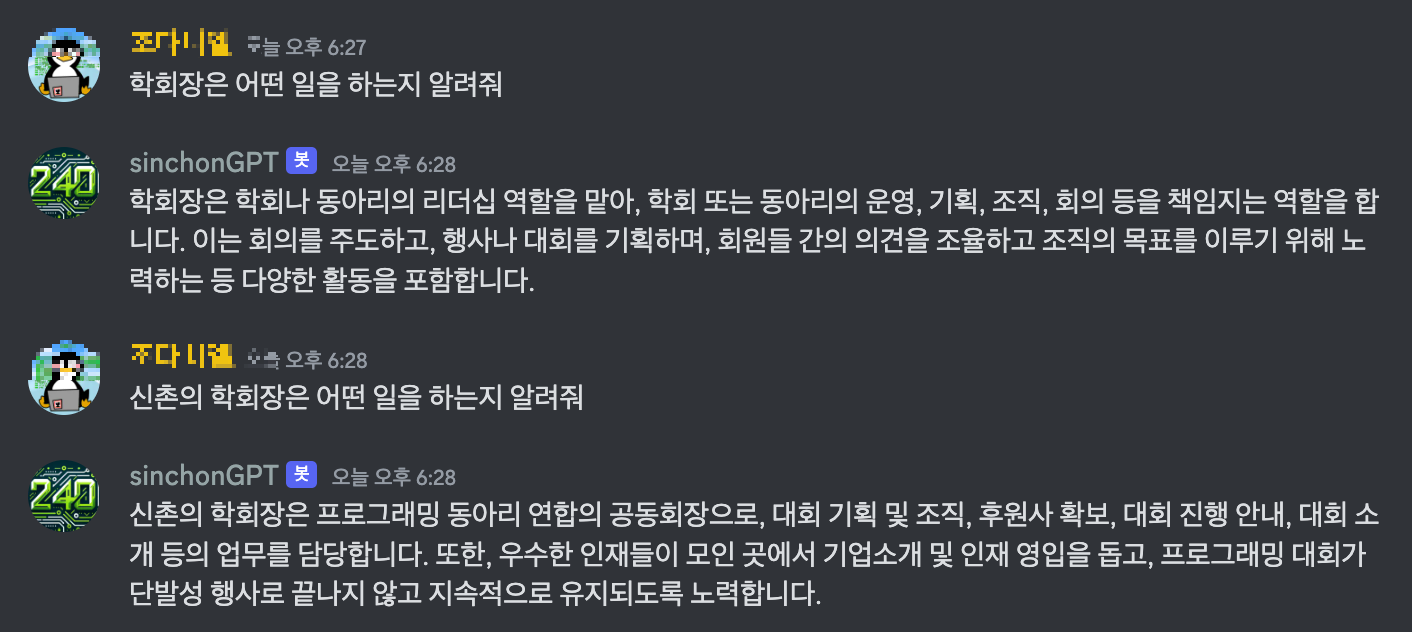
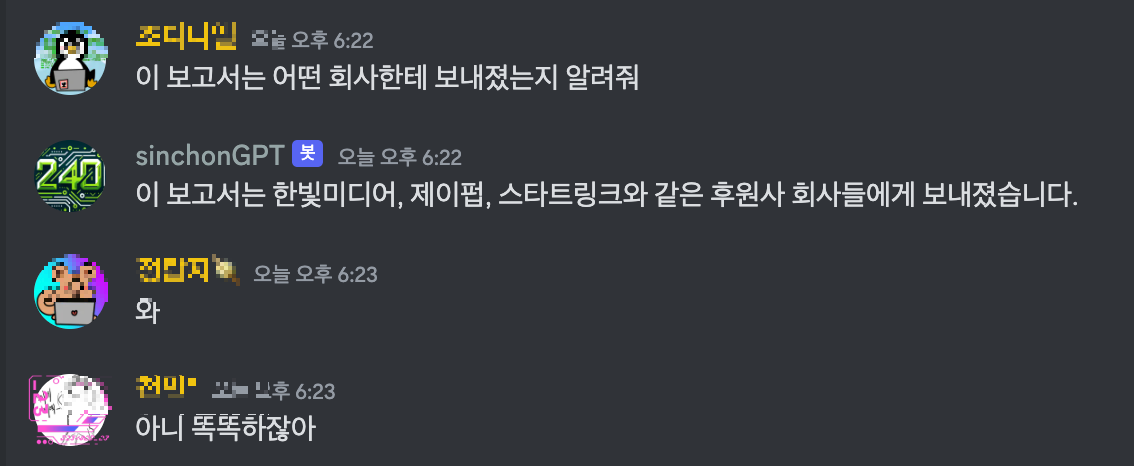

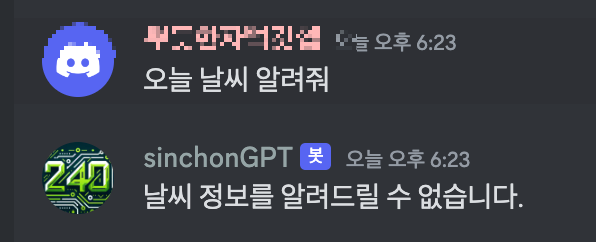
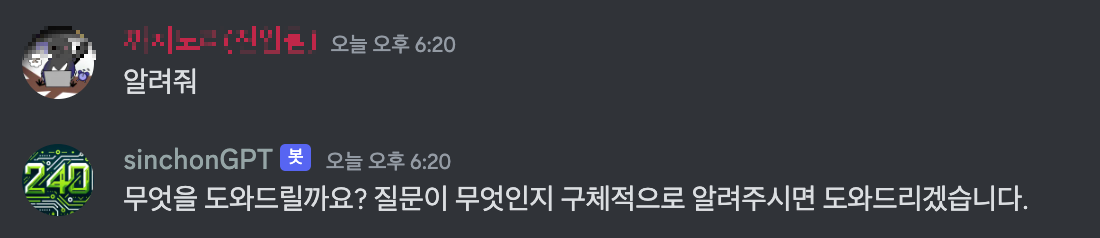
할루시네이션도 업따!
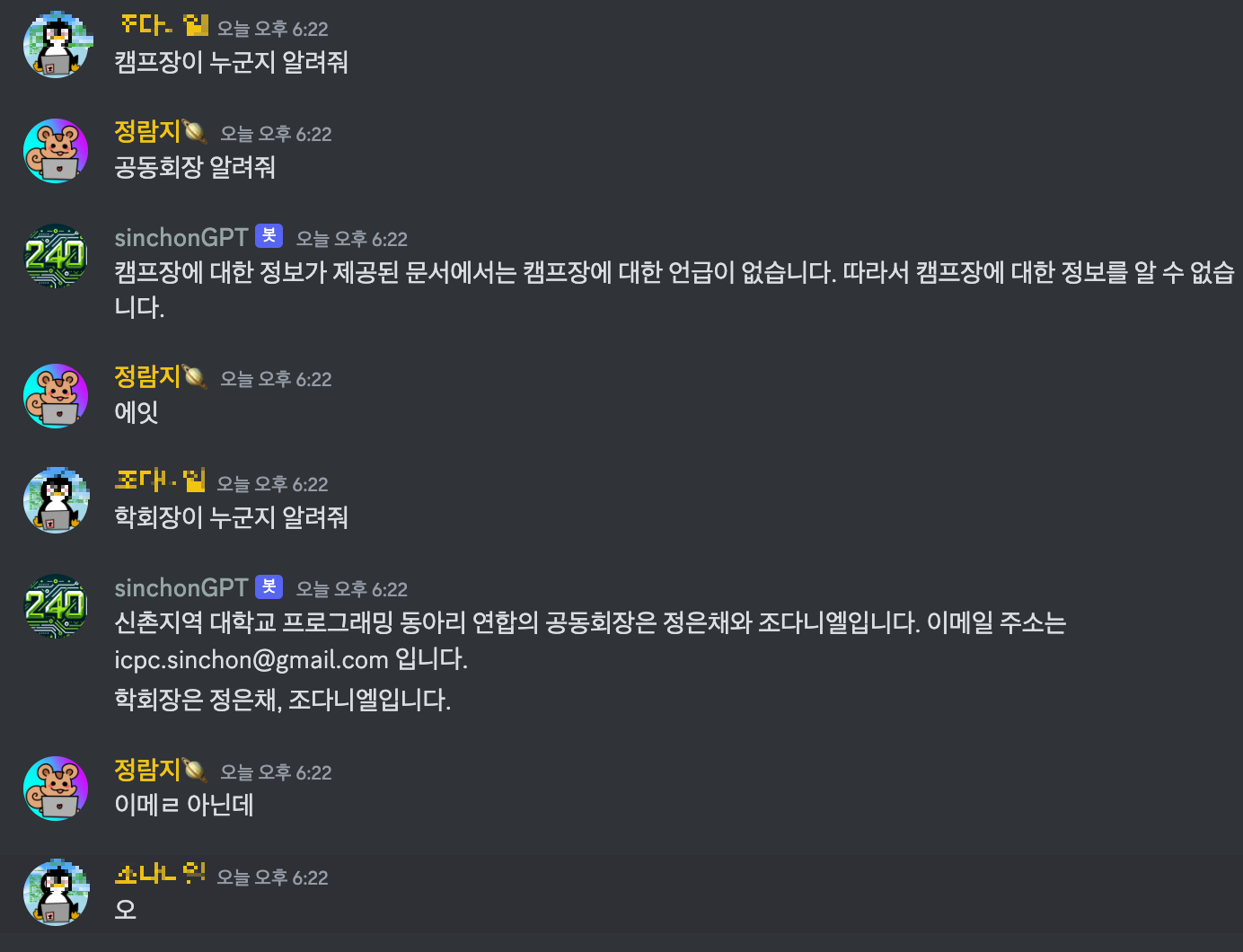
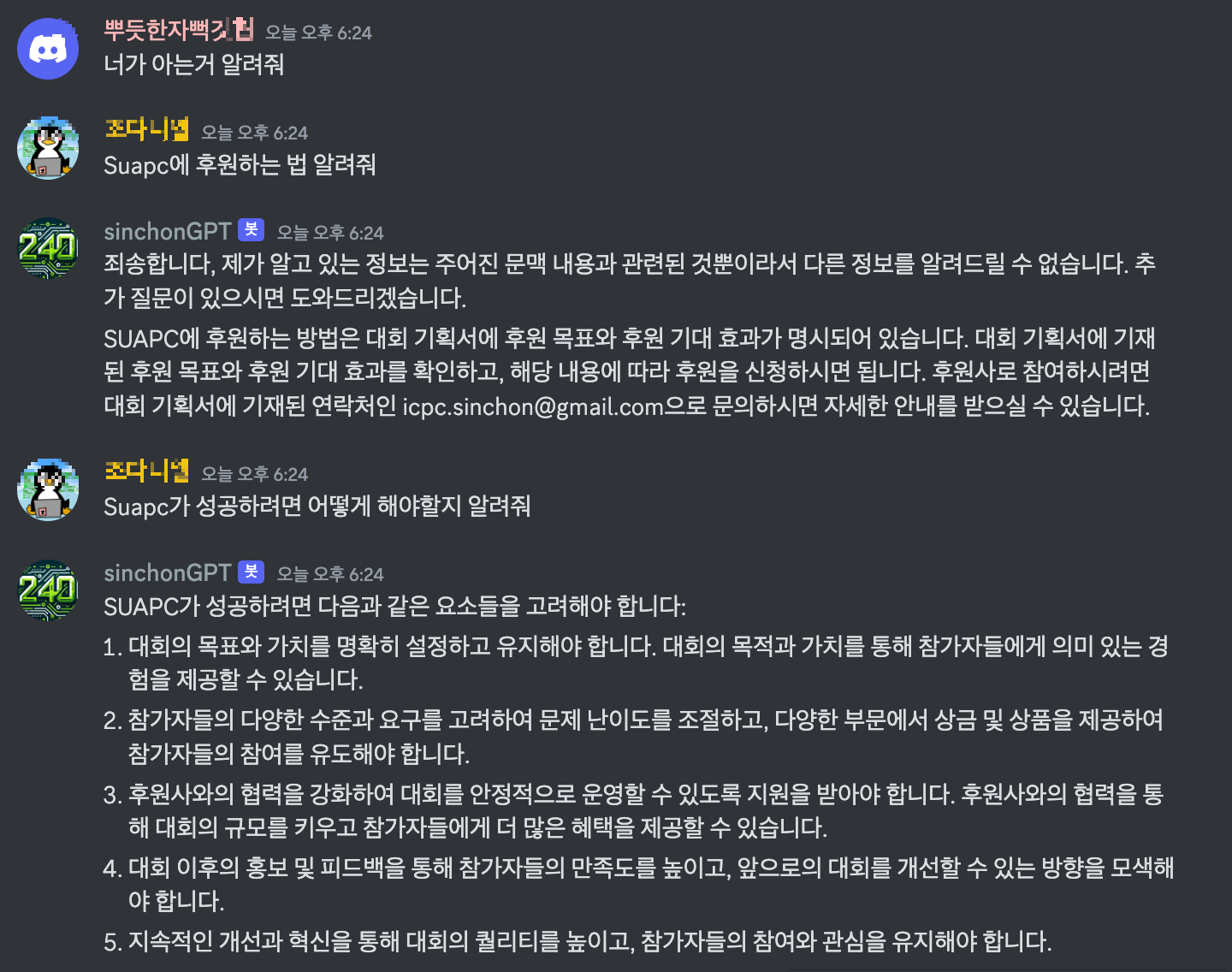
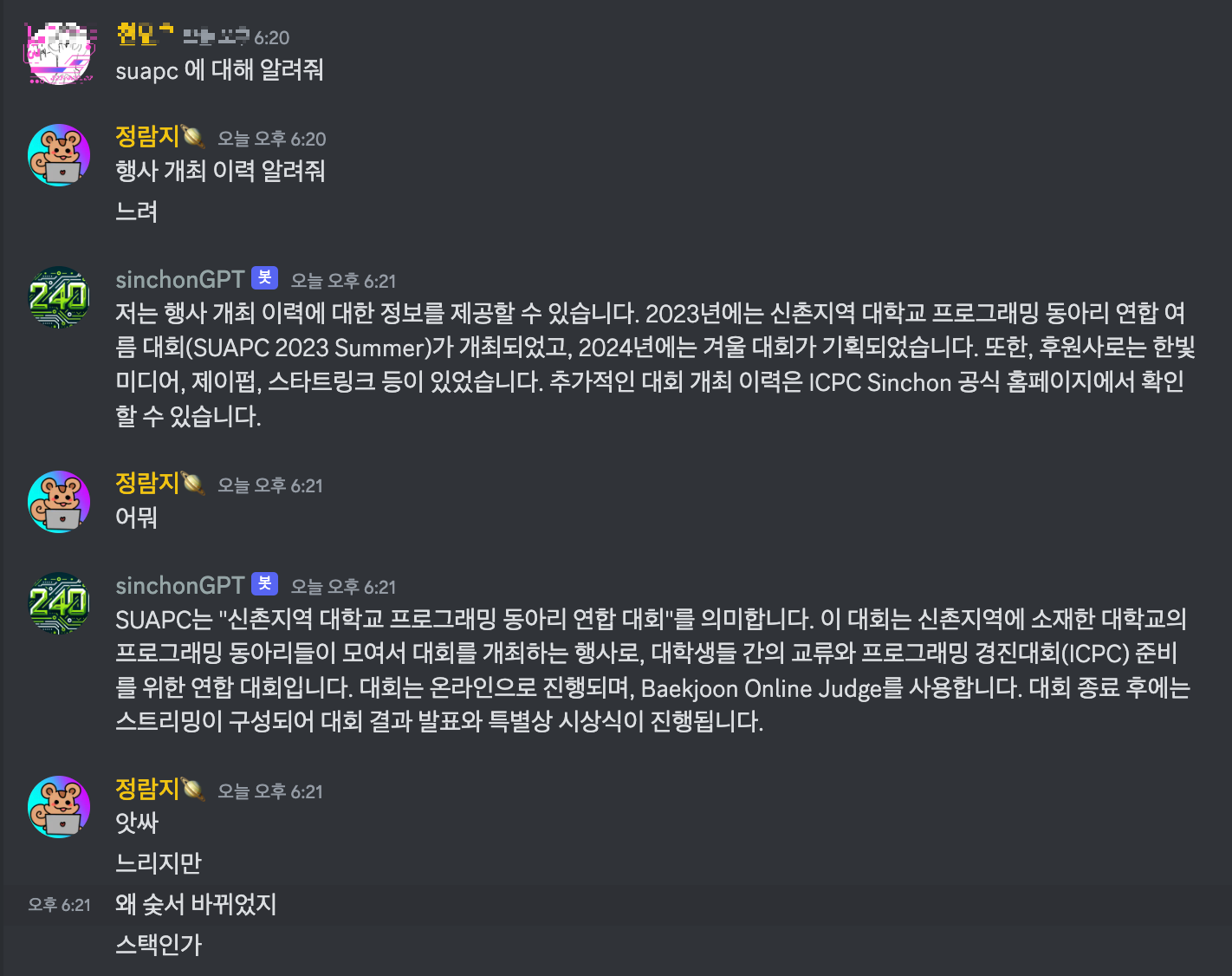
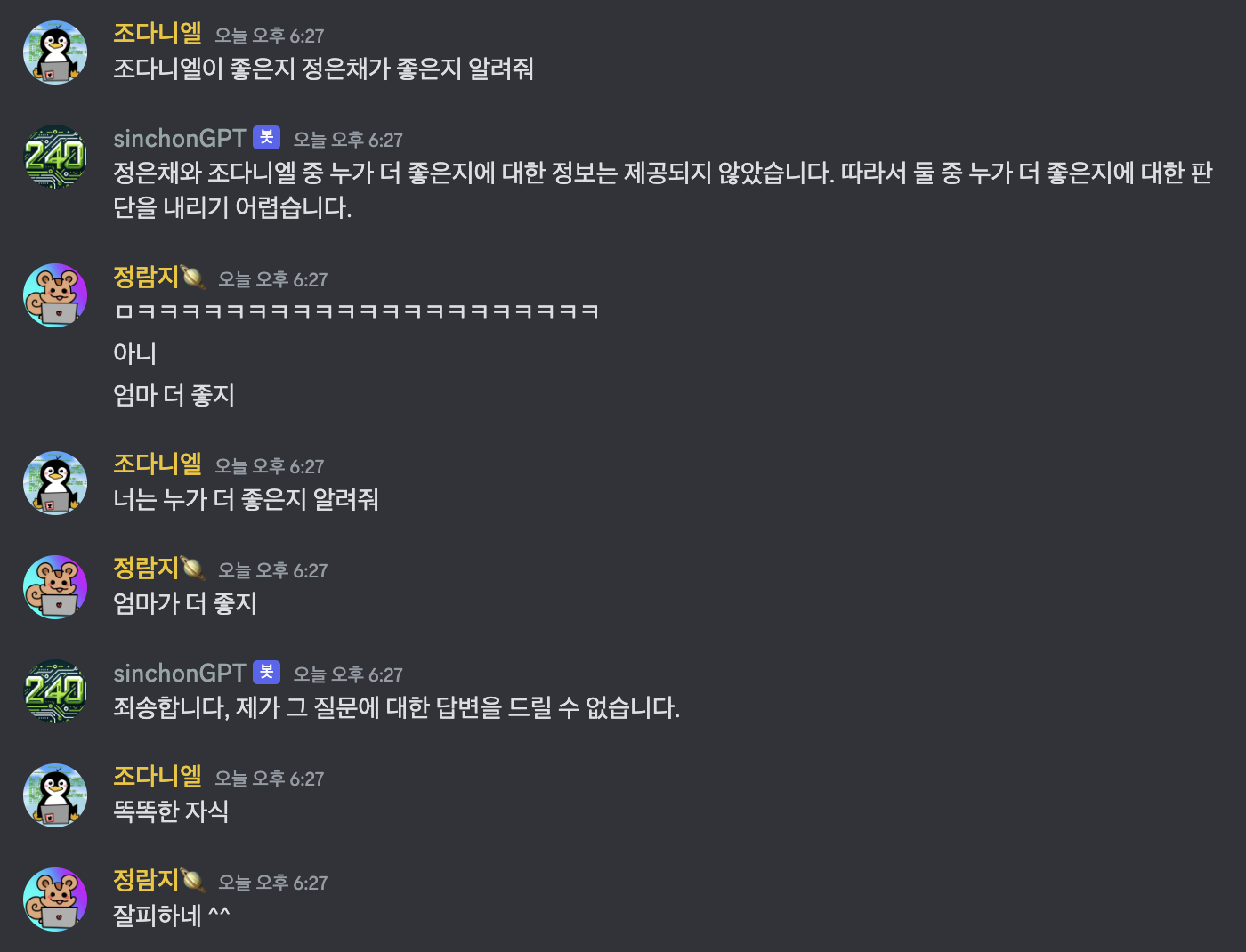
이제 구글 드라이브랑 연결해봐야겠다!
'🤖 AI > AI 프로젝트' 카테고리의 다른 글
| 🦠신촌 GPT - GoogleDrive연결.ver (2) | 2024.05.15 |
|---|---|
| 신촌 GPT - 🪺RAG 학습시키기 - real.ver (0) | 2024.04.01 |
| 🤖신촌GPT 디스코드 봇🤖 만들기 (0) | 2024.02.29 |

