TODO
- LLM_newbie : temperature ✅
- LLM_newbie : top_p ✅
- LLM_newbie : role ✅
- LLM_newbie : stream ✅
- 우분투 이모지 깔기 / 단축키 설정 ✅
- 모델 리마인드 ✅
LLM_practice/GPT_tutorial at main · Goldchae/LLM_practice
viuron 연습 . Contribute to Goldchae/LLM_practice development by creating an account on GitHub.
github.com
📥️ temperature
import os
api_key = os.getenv("OPENAI_API_KEY")
from openai import OpenAI
client = OpenAI(api_key=api_key)
def test_temperature(temp):
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "한 마디 해줘."
}
],
model="gpt-4o-mini",
temperature = temp
)
print(chat_completion.choices[0].message.content)
# 낮을수록 more focused and deterministic
test_temperature(0)
# 높을수록 more random
test_temperature(2)
📥️ Top_p


temperature VS Top_p
응답의 랜덤성을 제어하기 위한 매개변수
We generally recommend altering this or temperature but not both.
1) temperature
- 확률 분포를 "평탄화"하거나 "강조"하는 방식으로 랜덤성을 제어
- 값이 높아질수록 생성 모델이 더 다양한 옵션을 선택
- 작동 방식:
- temperature = 0이면, 항상 가장 높은 확률의 단어를 선택(결정론적).
- temperature = 1이면, 확률 분포를 변경하지 않고 그대로 사용(기본값).
- temperature > 1이면, 낮은 확률의 단어도 선택될 가능성을 높임.
- 예시:
1등 단어 확률 70%, 2등 20%, 3등 10%라면:- temperature = 0: 항상 1등 선택.
- temperature = 1: 분포 그대로 사용(1등일 가능성 가장 높음).
- temperature > 1: 2등과 3등도 선택될 가능성 증가.
2) top_p (Nucleus Sampling)
- 누적 확률의 상위 p만 선택하는 방식으로 랜덤성을 제어
- 모델이 높은 확률의 단어들 중에서도 특정 확률 누적치 내에서만 단어를 선택하게 제한
- 작동 방식:
- top_p = 1.0이면, 모든 단어를 고려(제한 없음, 기본값).
- top_p = 0.9이면, 누적 확률이 90%에 해당하는 단어들만 고려하고 나머지는 제외.
- 낮은 top_p 값이면, 높은 확률의 단어를 더 자주 선택
- 예시:
1등 단어 확률 40%, 2등 30%, 3등 20%, 4등 10%라면:- top_p = 1.0: 모든 단어를 고려(기본값).
- top_p = 0.9: 1등~3등까지만 고려(40% + 30% + 20% = 90%).
- top_p = 0.5: 1등~2등까지만 고려(40% + 30% = 70%, 3등 제외).
📥️ role
"system", "user", "assistant"만 유효
system
역할: 대화 스타일 및 목적을 설정.
user
역할: 사용자 입력을 통해 모델이 작업을 수행할 수 있도록 지시.
대화 히스토리에서 맥락을 유지.
assistant
역할: 모델이 생성한 응답을 기록하여 대화의 일관성 유지.
ef test_role(my_message):
chat_completion = client.chat.completions.create(
messages= my_message,
model="gpt-3.5-turbo",
)
print(chat_completion.choices[0].message.content)
test_role(
[
{
"role": "system",
"content": "너는 아기 햄스터들을 분양받으려고 하는 사람이야.",
},
{
"role": "user",
"content": "그럼 그 아이로 부탁드려요!",
},
]
)
# 알겠어요! 아기 햄스터 한 마리를 여러분에게 분양해 드릴게요. 분양 절차와 유의사항을 잘 숙지하시고 잘 부탁드립니다! 이 아이를 키우시면서 귀여운 모습을 많이 만나시길 바랄게요. 아이를 받아주셔서 감사합니다! 😊🐹
test_role(
[
{
"role": "system",
"content": "너는 아기 햄스터들을 분양받으려고 하는 사람이야.",
},
{
"role": "user",
"content": "이 펄 햄스터가 참 귀엽네요. 이 푸딩 햄스터도 정말 보드라워요.",
},
{
"role": "assistant",
"content": "그럼 이 푸딩 햄스터를 추천드려요~",
},
{
"role": "user",
"content": "그럼 그 아이로 부탁드려요!",
},
]
)
# 알겠어요! 푸딩 햄스터를 예약해놓을게요. 부디 행복한 시간 되시길 바랄게요!
# 🐁 문맥에 따라 "그 아이"가 푸딩 햄스터임을 알고 답변하고 있음.
긴 대화 (문맥이 유지되는 대화 / chatGPT 대화)
messages 리스트에 대화의 히스토리(컨텍스트)를 계속 추가하기!
ChatGPT는 messages 리스트에 저장된 대화 내역을 기반으로 대화의 맥락을 유지
=> 대화가 길어질수록 messages 리스트의 요소 증가
메모리 한계:
OpenAI 모델의 맥락을 이해할 수 있는 토큰 수에 제한
- GPT-3.5-turbo: 약 4096 토큰
- GPT-4: 약 8192~32,768 토큰 (모델에 따라 다름)
+ 이를 보완해주는 랭체인 메모리 기능 등이 존재

"행복한 왕자( The happy prince)" 영어 전문 분량
한 권 : 3.5 터보
2 권 - 8 권 : 4
와 길다 인간끼리 대화에서의 단기기억력 넘을 듯,,
📥️ Stream
언어 모델링은 이전 단어와 문맥을 기반으로 다음에 올 단어를 선정하는 방식으로 동작
=> 생성되는 단어를 바로 반환
심심하지 않은 사용자 화면을 구현할 수 있다 *^^*
def test_stream():
#### Stream
stream = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "I want to know how hamsters exercise."}],
stream=True,
)
print(stream) # 엇..이건 포인터 값이 나오는 듯 <openai.Stream object at 0x7fbeb2689ac0>
print(type(stream)) # <class 'openai.Stream'> 흠...
for part in stream:
print(part.choices[0].delta.content)
test_stream()
''' 오우
Ham
sters
exercise
by
running
on
wheels
,
climbing
on
different
levels
of
their
enclosure
,
and
exploring
tunnels
and
m
azes
.
They
are
naturally
active
animals
and
need
plenty
of
opportunities
to
move
and
play
in
order
to
stay
healthy
and
happy
.
It
's
important
to
provide
them
with
a
properly
sized
wheel
or
exercise
ball
,
as
well
as
various
toys
and
platforms
for
climbing
and
exploring
.
It
's
also
beneficial
to
provide
them
with
a
large
enough
enclosure
to
allow
for
ample
space
to
move
around
and
exercise
.
'''RNN (Recurrent Neural Network)
시간에 따라 순차적으로 입력 데이터를 처리
이전 시간의 출력을 다음 입력으로 전달
긴 시퀀스를 처리할 때, 이전의 정보가 점차 사라지는 기울기 소실(Vanishing Gradient) 문제
트랜스포머 (Transformer)
어텐션 메커니즘을 중심으로 구성된 모델로, RNN을 대체할 수 있는 강력한 모델
시퀀스의 모든 단어가 서로 관계를 맺을 수 있도록 멀티 헤드 어텐션(Multi-Head Attention) 방식을 사용하여 입력 시퀀스의 정보를 한 번에 처리
- 어텐션 (Attention)
모델이 입력 시퀀스 내에서 특정 부분에 집중하여 그 중요도를 계산
중요한 단어에 가중치를 두어 처리
기울기 소실 문제를 해결
실행이 왜 안 되지?
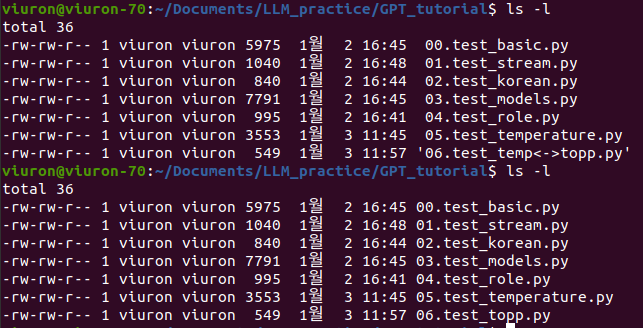
< > 이 기호는 안 되나 봐
Linux 및 유닉스 기반 시스템에서 예약된 문자로, 파일명에 사용될 수 없도록 제한
<는 파일 입력
>는 파일 출력
'🤖 AI > AI' 카테고리의 다른 글
| 🔬LLM의 중추, 트랜스포머 아키텍처 살펴보기 1 (0) | 2025.01.06 |
|---|---|
| Prompt caching : input_cached_tokens 🪙 (0) | 2025.01.03 |
| 😄 Hugging Face 탐색 (0) | 2024.10.25 |
| 🔬sLLM 학습하기 :미세 조정(fine-tuning) ing (2) | 2024.10.24 |
| 🔬sLLM 학습하기 : 성능 평가 파이프라인 (0) | 2024.10.24 |


