Club|Project/카카오테크 부트캠프 | AI
🦜카부캠 앵무말(Parrotalk) : 성능 통계
정람지
2024. 12. 3. 20:57


재료

통계 목표
- 평균 (Mean): 각 모델의 평균 점수 계산
- 중앙값 (Median): 점수의 중간값 계산
- 분산 (Variance) / 표준편차 (Standard Deviation): 점수의 분포 정도를 확인
- 점수 차이 (Difference): 파인튜닝 모델 점수 - 베이스 모델 점수
- 점수 차이의 평균: 점수 차이가 얼마나 일관되게 개선되었는지 확인
- 점수 차이의 분포: 차이의 분산 및 표준편차 계산
통계
import json
file_paths = ["fineTuning/validate_data/base_model_validation.json",
"fineTuning/validate_data/fineTuning_model_validation.json",
"fineTuning/validate_data/gpt_model_validation.json"]
for file_path in file_paths:
with open(file_path, "r", encoding="utf-8") as file:
datas = json.load(file)
scores = []
for data in datas:
scores.append(int(data["evaluation_score"]))
# 평균
MEAN = sum(scores) / len(scores)
# 중앙값
scores.sort()
MEDIAN = scores[len(scores)//2]
# 분산
VARIANCE = sum((x - MEAN) ** 2 for x in scores) / len(scores)
print(f"{file_path}에 대한 결과:")
print(f"평균 : {MEAN:.2f}")
print(f"중앙값 : {MEDIAN:.2f}")
print(f"분산 : {VARIANCE:.2f}")
print()
fineTuning/validate_data/base_model_validation.json에 대한 결과: 평균 : 0.66 중앙값 : 0.00 분산 : 2.10 fineTuning/validate_data/gpt_model_validation.json에 대한 결과: 평균 : 8.88 중앙값 : 10.00 분산 : 3.51
룰루
시각화
matplotlib 라이브러리로


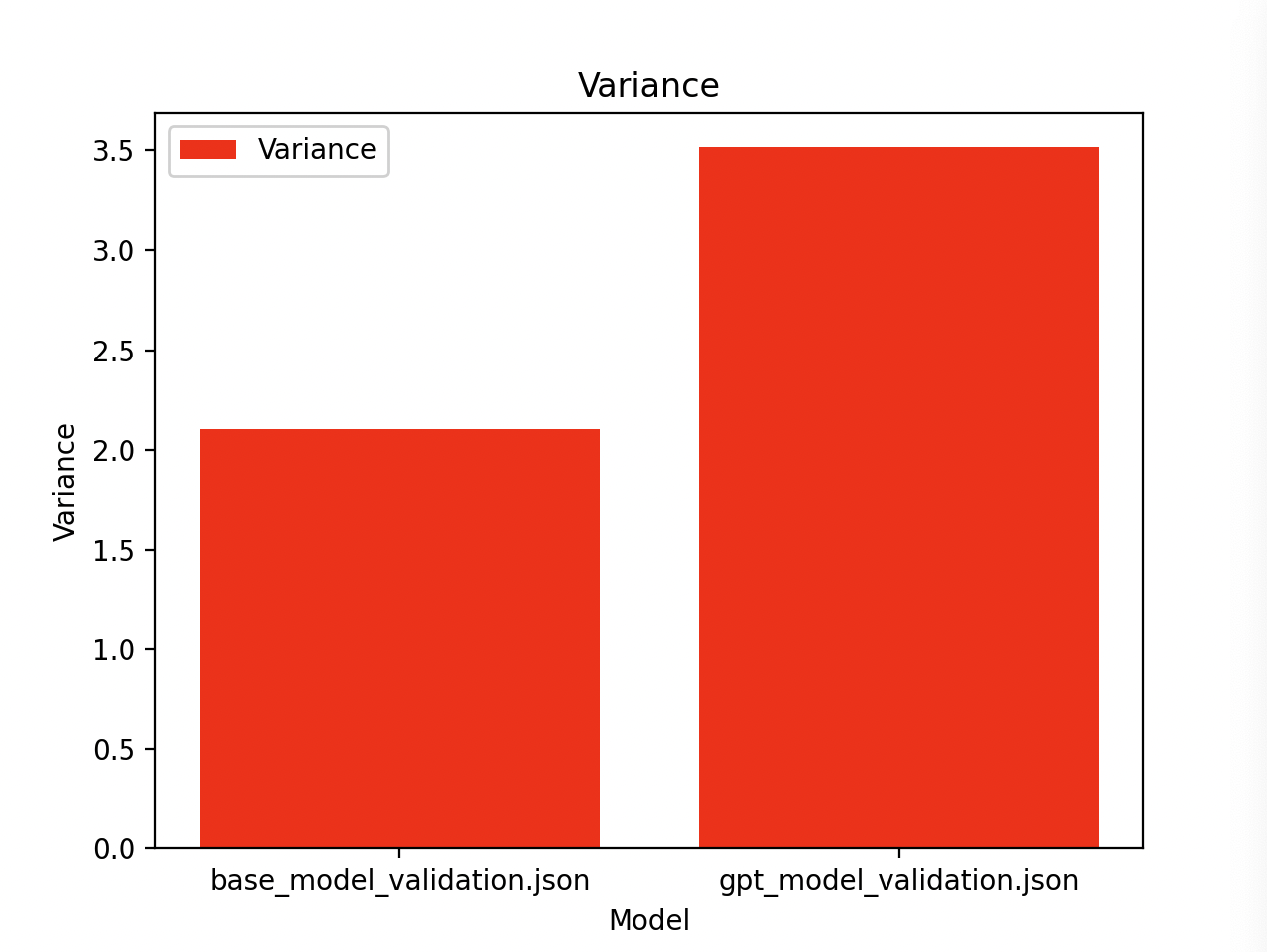
극단적이고 아름답다.
각 질문에 대한 차이 보려고 했는데
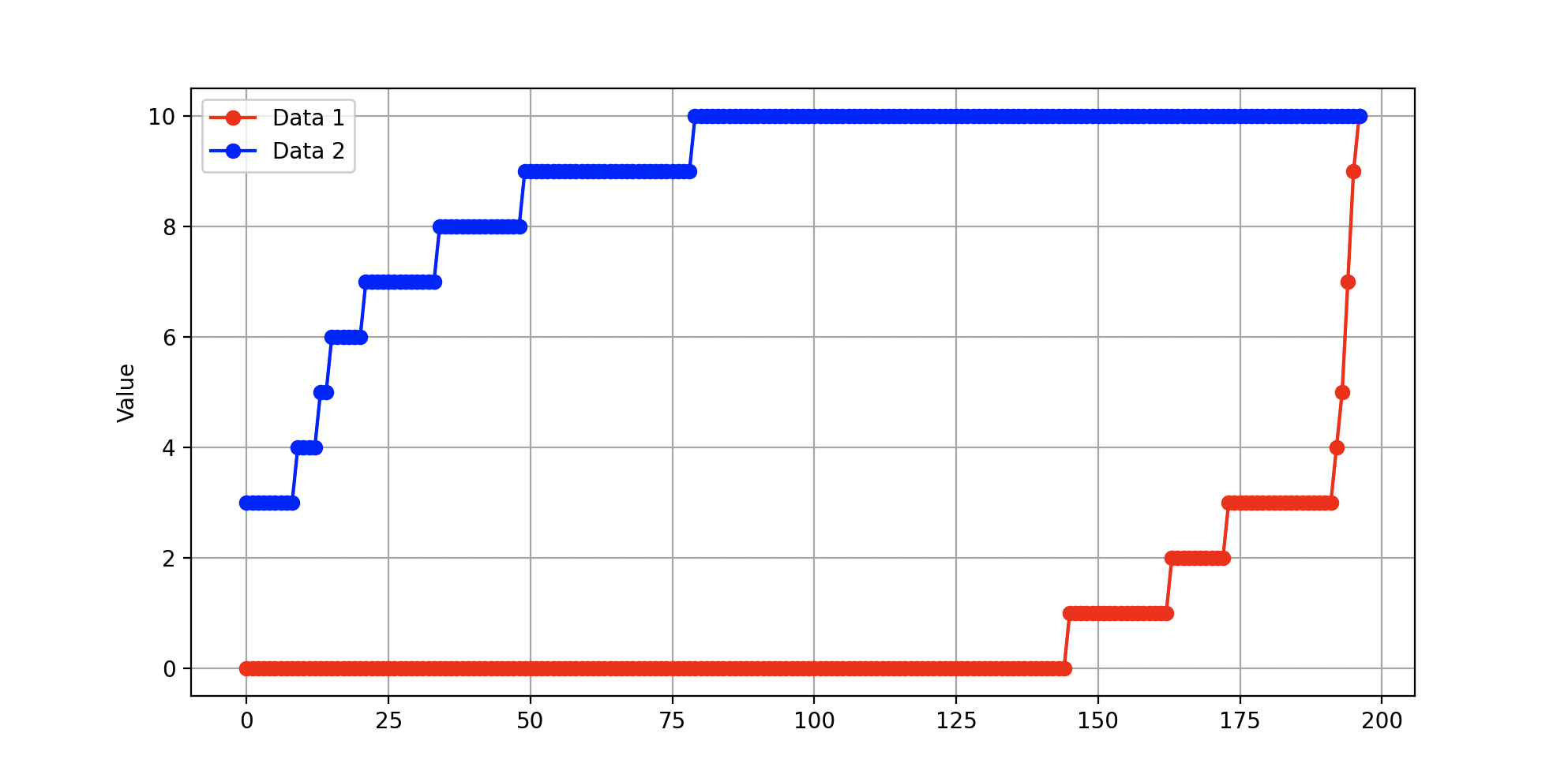
에? 왜 정렬되어 있지??
는 바로 파이썬 리스트 포인터 때문..
중간값때문에 .sort()가 뒤에 잇엇다...
scored = sorted(scores)
바꿈
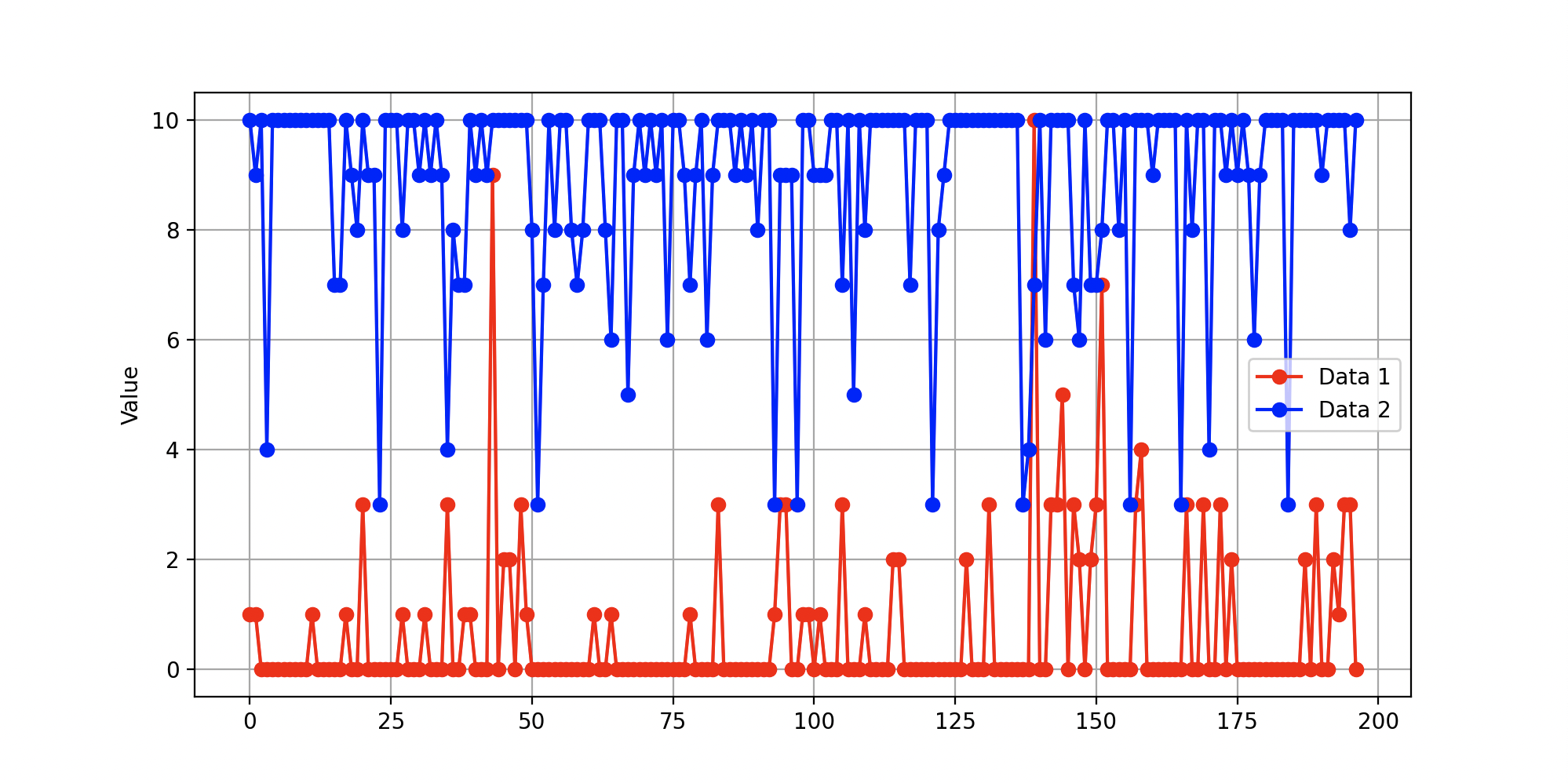
마치..종유석 석순같아.. 석주도 몇 개 있구나
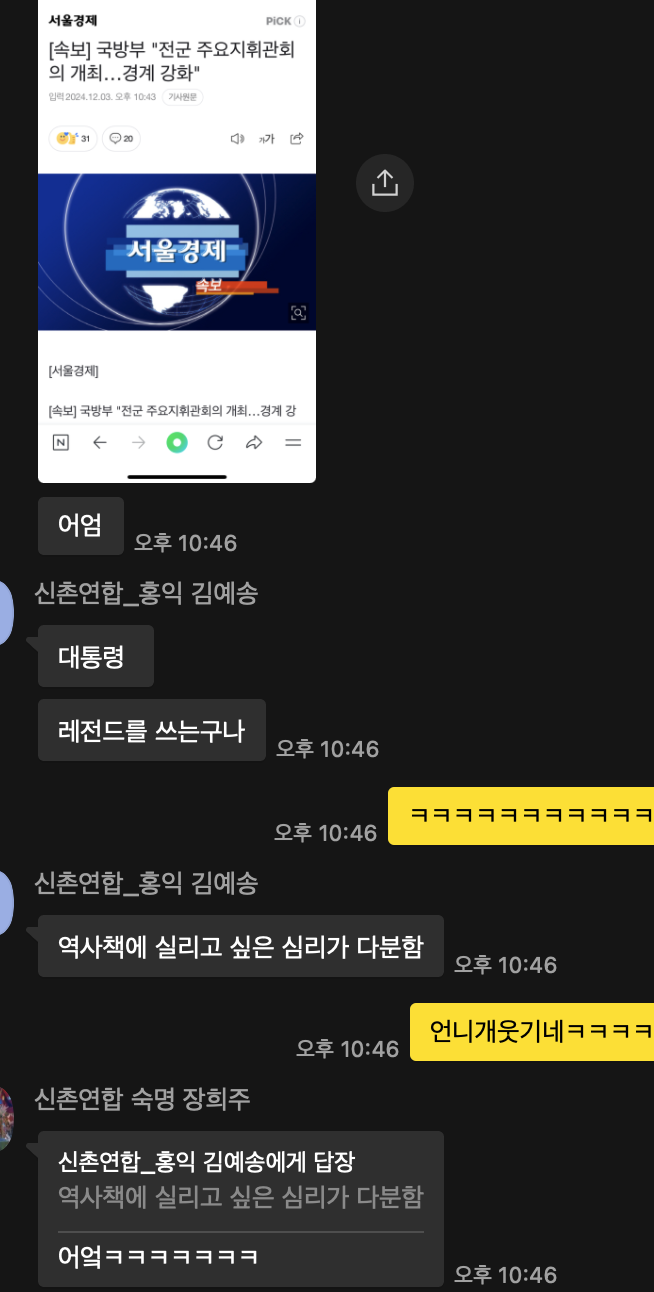
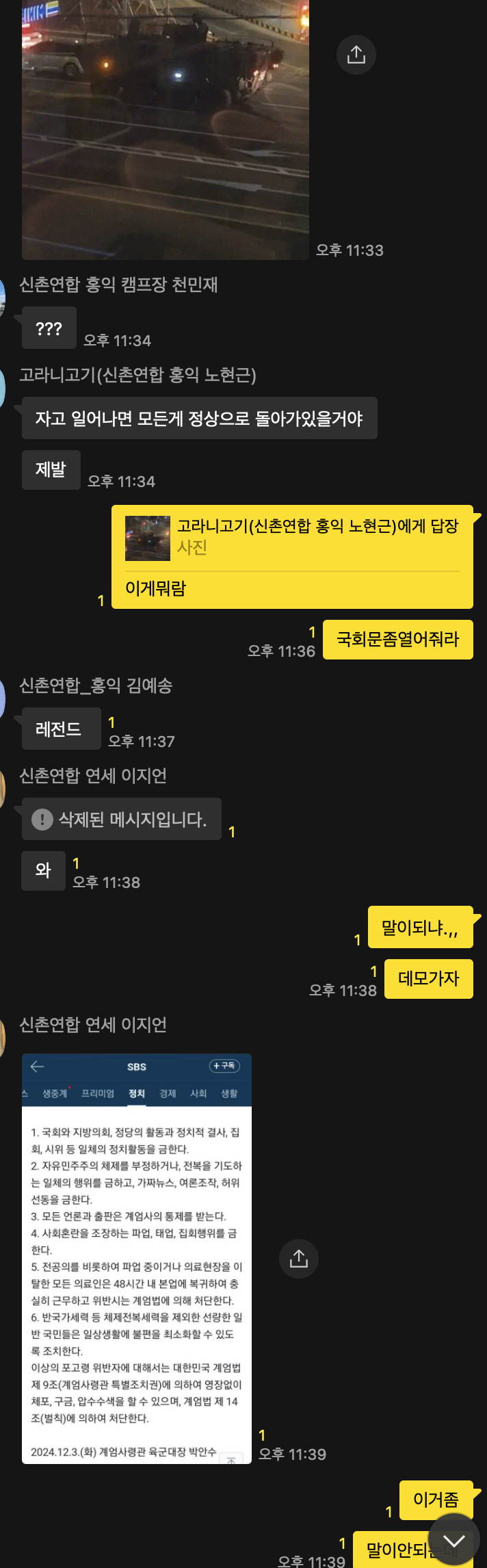
계엄.,.?머임??
갑자기머임??